Abstract
- 딥러닝은 고품질의 label이 존재하는 대규모의 Dataset에 대해 높은 성능을 달성하였습니다. 그러나 이런 Dataset은 일부 전문 영역의 경우 정확하고 효율적으로 주석을 달기에는 많은 비용이 들고 어렵다. 반면, rough한 label은 훨씬 더 쉽게 획득할 수 있으므로 이를 이용하는 부분에서 발생하는 문제를 해결하기 위해 MaskCon이라는 Contrastive learning 방법을 제안한다. 이 방법은 Finer labelling 문제를 해결하기 위해 Coarse-labelled dataset을 활용하는 것이다. 보다 구체적으로, Contrastive learning Framework 내에서 각 sample에 대해 다른 sample에 대한 coarse label과 해당 sample에 대한 soft-label을 생성하는 방식이다. 제안 방법론은 coarse label에 의한 sample distance를 기반으로 soft-label을 제안한다. 이를 통해 sample간 관계와 coarse label을 모두 활용할 수 있다.
Introduction
- Deep learning의 Supervised learning은 대규모의 고품질 Dataset에 의존하며, 많은 시간과 노동력이 소요된다. 이러한 의존성을 피하기 위해 다양한 학습 Framework가 제안되고 연구되어 왔다. Self-supervised learning은 여러 pretext를 통해 의미 있는 Representation을 학습하는 것을 목표로 하며, Semi-supervised learning은 일반적으로 일부만 label이 달린 Dataset을 고려하며, pseudo labelling, 정규화 등이 일반적으로 사용된다. 또한 noisy labelled data를 사용한 학습도 점점 더 많은 관심을 받고 있다.
- 본 논문에서는 coarse-labelled Dataset으로 Finer representation을 학습하는 문제를 고려한다. 저자들은 Self-supervised contrastive learning의 새로운 학습 체계인 MaskCon을 제안한다. 이 방법은 각 sample과 Dataset의 다른 sample 간의 관계를 고려하여 학습하는 것을 목표로 한다. 특히, sample 자신과의 관계는 항상 positive로 간주하며 다른 sample과의 관계를 추정하기 위해 해당 sample의 augmentation과 다른 sample을 대조하여 soft-label을 도출하고 coarse-label을 기반으로 생성된 Mask를 활용하여 이를 개선한다. MaskCon은 CIFAR100, ImageNet-1K, CIFARtoy를 비롯한 여러 Dataset에서 State-of-the-art에 비해 상당한 개선을 달성했다.
Methodology
-
본 논문의 제안 방법은 동일한 coarse class 내의 모든 sample에 동일한 가중치를 부여하는 대신, 동일한 fine label을 가진 sample을 강조하고 다른 sample의 중요도를 낮추는 것을 목표로 한다. 이를 위해 sample간의 관계를 직접 활용하는 MaskCon 기법을 도입한다.
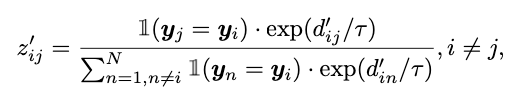
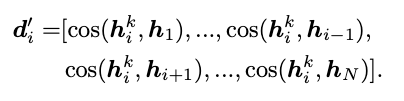
-
위 수식에서 Zij는 다른 sample에 대한 sample간 관계를 나타내는 것으로 자기 자신에 대한 key view projection hk와 자신을 제외한 전체 Dataset의 {h1, ..., hN}을 활용하여 해당 값을 계산한다. 이때, 자신과 다른 coarse label을 가진 sample j를 제외하는 Mask를 사용한다.
-
동일한 coarse label의 모든 sample들을 positive로 간주하는 것은 정보가 왜곡될 여지가 있지만, 동일한 coarse label이 없는 sample은 negative로 확실하게 식별할 수 있고 Zij에 대한 noise가 줄어드는 효과를 가진다.
-
이후, Zsupcon과 비교하여 feature space의 유사성에 따라 동일한 coarse label의 sampledp weight를 재조정한다. Masked contrastive loss를 Lmaskcon으로 표시하며 Grafit과 CoIns 방법론과 같이 각 Loss에 가중치를 부여하는 방식을 적용한다.
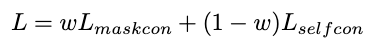
Experiments
- 본 논문의 실험 비교모델로는 Grafit, CoIns, Moco, SupCon을 사용하였고, Dataset으로 CIFARtoy & 100, ImageNet-1K, Stanford Cars19를 사용하였다.
- Finer label이 있는 Test dataset에서 다양한 비교모델을 평가하기 위해 recall@K metric을 사용한다. 각 Test image는 먼저 Test set에서 Top-k개의 가장 가까운 neighbor를 검색하고, 이들 중 동일한 Finer label이 하나 이상 존재하면 1을, 그렇지 않으면 0을 받는다. Recall@K는 모든 Test image에 대해 이 점수의 평균을 구한다.
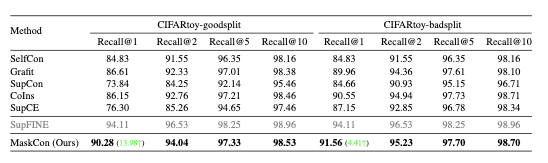
-
Coarse labelling과정으로 CIFAR10 Dataset에서 장난감 Dataset을 수동으로 생성한다. 10개의 원래 Class에서 8개의 하위 집합을 선택한다. 실험에서는 잘 분류한 coarse label이 존재하는 goodsplit과 잘못 분류한 coarse label이 존재하는 badsplit 두가지 경우로 실험을 진행하였다.
-
위 표에서 볼 수 있듯이 본 논문의 제안방법이 두 가지 경우 모두 최고의 성능을 달성하였다.
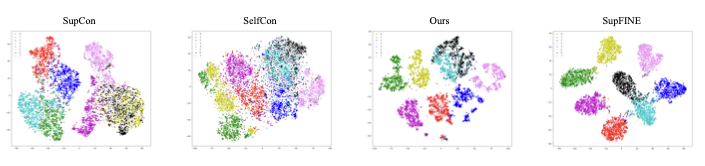
-
위 그림은 goodsplit Dataset에서 모든 Test sample의 학습된 Representation을 시각화한 것이다. Supervised Contrastive learning과 Self-supervised Contrastive learning으로 학습된 Representation은 각각 sample을 under-clustering하고 over-clustering하는 경향이 있다. 이와 대조적으로 MaskCon은 Fine label만으로 학습한 4번째 결과와 일치하는 더 작고 선명한 Cluster를 얻었다.
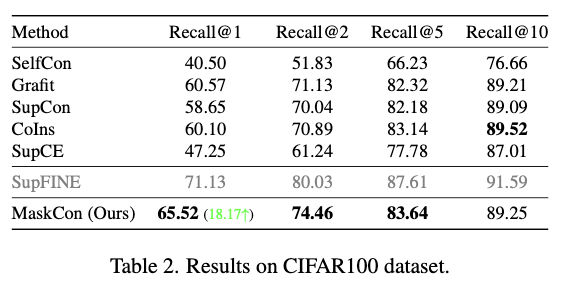
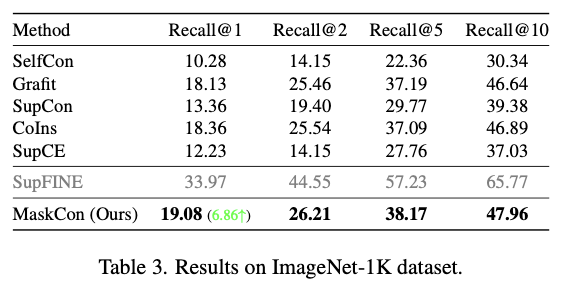
- 위 두개의 표는 각각 CIFAR100과 ImageNet-1K dataset에 대한 실험결과를 나타낸 것으로, 거의 모든 비교모델에서 MaskCon이 더 나은 성능을 보이는 것을 알 수 있다.
Discussion
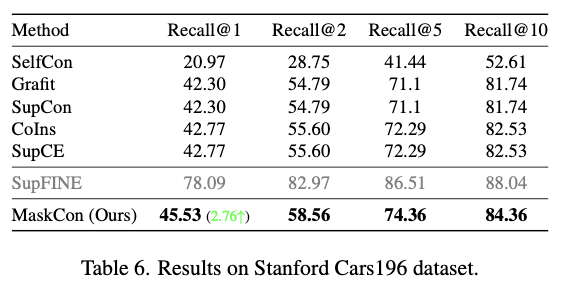
- 관련 분야의 최신 method와 비교했을 때, MaskCon은 모든 실험에서 최고의 결과를 얻었다. 보다 구체적으로는 CIFAR dataset에서는 제안 방법론이 Finer label이 있는 dataset으로 학습한 SupFINE의 결과에 근접한 반면, Stanford Cars19 dataset에서는 그 격차가 크다. 이는 제안 방법론의 Base인 Self-supervised contrastive learning에서 data augmentation 방법이 dataset의 정보를 파괴할 수 있다는 사실이 밝혀졌고, 이러한 사실이 성능에 영향을 미쳤기 때문이라고 생각된다. 저자들은 이러한 문제를 해결하는 것이 향후 연구 방향이라고 밝히고 있다.
Conclusion
- 본 논문에서는 coarse label을 가진 Dataset로 세분화된 정보를 학습하기 위한 MaskCon 방법론을 제안하였다. Coarse label과 Instance 판별을 활용하여 sample 간 관계를 더 잘 추정하며 CIFAR Dataset을 비롯한 여러 Dataset에서 MaskCon이 Baselines에 비해 일관되게 성능 우위를 점한다는 것을 실험적으로 검증한 연구라고 할 수 있다.
