[논문 리뷰] A two-stage explainable artificial intelligence approach for classification-based job cycle time prediction
Paper Seminar
목록 보기
8/18
Abstract
- 최근 작업의 소요 시간을 정확하게 예측하기 위해 DL 기반의 방법론이 제안되고 있다. 그러나 이러한 방법론은 사용자가 이해하고 소통하기 어렵기 때문에 수용하기 어렵다. 이러한 문제를 해결하기 위해 본 연구에서는 분류 기반 작업 주기 예측 방법을 보다 잘 설명하기 위해 2단계 XAI 접근법을 제안한다. 먼저 Job을 여러 개의 클러스터로 나눈 다음 분류 결과를 설명하기 위해 Scatter radar diagram을 설계한다. 이는 기존의 XAI 기법에 비해 더 많은 요구 사항을 충족하여 해석을 용이하게 한다. 그런 다음 각 크러스터에 대해 클러스터 내 Job의 주기 시간을 예측하기 위한 인공신경망을 구축한다. 이후 Random forest로 예측 메커니즘을 근사화시킨다. 이렇게 하면 처음 몇 개의 의사 결정 규칙이 대부분의 정보를 제공할 수 있으며 사용자는 모든 규칙을 알 필요가 없다.
Introduction
- Job의 Cycle time을 정확하게 예측하는 것은 제조 시스템에서 중요한 작업이다. 그러나 제조 시스템의 복잡성으로 인해 예측은 어려운 과제이다. 지금까지 다양한 Deep learning 기반 Job cycle time prediction이 제안되었지만, 인공지능에 대한 충분한 배경 지식이 없는 공장 작업자의 경우 이해하거나 의사소통하기가 쉽지 않아 이러한 방법의 수용 가능성이 제한된다. XAI는 이러한 문제를 해결하기 위한 개념으로 AI Application의 해석 가능성 또는 효과를 개선하는 것을 목표로 한다. 본 연구의 Motivation은 분류 기반 Job cycle time prediction의 설명 능력을 개선하는 것이다. 분류 기반 방법론은 K-means, FCM, SOM, CART 등의 분류 방법을 사용하여 작업을 여러 개의 클러스터로 분할한다. 그런 다음 각 클러스터에 대해 인공 신경망을 구축하여 Job cycle time prediction을 수행한다.
기존 방법론의 단점
- Clustering 결과에서 Cluster 간 Job의 상대적 위치를 알기 어렵고, 이는 Clustering 결과의 합리성을 확인하는 데 도움이 되지 않는다.
- 인공신경망을 설명하기 위한 단순한 XAI 기법으로는 정확한 설명을 할 수 없는 경우가 많다.
- Random forest로 인공신경망의 예측 메커니즘을 설명하는 것은 간단하고 정확하지만, 결정 규칙이 너무 많으면 User에게 혼란을 줄 수 있다.
극복 방법
- 상대 위치 측정 그래프, Radar chart, Segment distance diagram의 특성을 결합한 Scatter radar diargram은 Cluster 간 Job의 상대적 위치를 시각화하기위해 설계되었다.
- Random forest에서 생성된 의사 결정 규칙을 User가 쉽게 이해할 수 있도록 재구성하는 체계적인 절차가 수립되었다. 기본적으로 더 정확한 규칙이 먼저 User에게 제공되고 다른 규칙은 나중에 수정 사항으로 배치된다. 이러한 방식으로 처음 몇 개의 의사 결정 규칙이 대부분의 정보를 제공할 수 있다.
Classification process와 결과를 설명하기위한 XAI 기법들
-
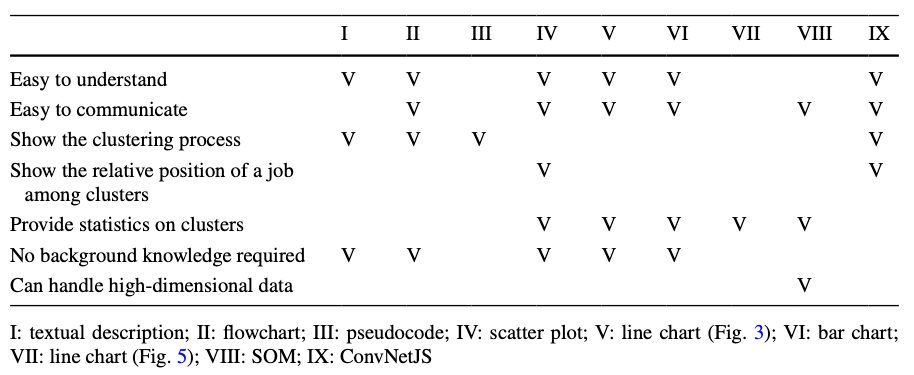
Classification process를 설명하기 위해 Text 설명, 순서도, Psuedocode와 같은 XAI 기법이 일반적으로 사용되어왔으며, ConvNetJS와 같은 애니메이션 기반 XAI 기법이 적용되어 인공신경망을 이용한 분류 과정과 결과를 설명하는 데 사용되기도 하였다. 또한, Elbow method에서는 Line chart가 최적의 Cluster 수를 결정하는 데 도움이 되며, 이로부터 관성 감소를 무시할 수 있게 된다. 고차원 데이터의 경우, SOM은 인접한 Cluster 간의 거리를 표시하는 시각화 도구를 제공한다.
-
위의 표는 기존에 제안된 XAI 기법들이 7가지 요건들을 얼마나 충족시켰는지 정리한 표이다. 현존하는 대부분의 XAI 기법은 최대 5가지 요건만 충족할 수 있는 수준이라는 것을 알 수 있다.
인공신경망을 설명하기위한 XAI 기법들
- Text 설명과 네트워크 구성 다이어그램을 사용하여 인공신경망의 작동을 설명하는 것이 일반적이다. 또한 CNN의 경우 ConvNetJS 등의 애니메이션 기반 기법이 훈련 과정을 설명하는 데 적용되었다. 또한, 인공신경망의 작동 메커니즘을 근사화하는 기법이 다양하게 등장하였는데, 그 중 Random forest를 이용한 접근 방식이 XAI 기법의 요건 중 대부분을 충족한다.
Methodology
Explaining the classification result using a scatter radar diagram
- 분류 기반 Job cycle time prediction은 우선 Job을 Clustering한다. 이를 위해 k-means, FCM, SOM, CART 등을 적용할 수 있다.
- 분류 방법 중 k-means를 사용한 방법을 예시로 들자면, 우선 클러스터 수 k를 결정하고 클러스터에 Job을 무작위로 할당한다. 그 다음 각 Cluster에 Center를 계산한다. 이후, Job과 각 Cluster의 Center 사이의 거리를 측정하고 Cluster 내 SSD의 합을 계산한다. 그런 다음, Z값이 수렴하면 중지하고 그렇지않으면 Cluster 중심 사이의 거리를 측정하는 단계로 돌아간다. 새로 들어온 Jobdml Cycle time을 예측할 때는 해당 데이터를 Cluster center의 데이터와 비교한 다음 가장 가까운 Cluster에 할당한다.

- 위 그림은 새로운 데이터가 Clustering된 것을 Scatter radar diagram을 통해 시각화한 것인데, 화살표가 굵을수록 해당 Cluster에 더 가깝다는 의미이다. 이러한 XAI 기법은 이해하기 쉽고 의사 소통이 쉬우며, 화살표의 굵기를 통해 Cluster 간 Job의 상대적 위치를 표시한다. 또한, 배경 지식이 필요치 않고 고차원 데이터를 처리할 수 있다.
Explaining the prediction mechanism using RF with re-organized rules
- Clustering 이후, 각 Cluster에 대해 Job cycle time을 예측하기 위해 인공신경망을 구축한다. 인공신경망의 Input에는 Job j의 속성과 생산 조건이 포함된다. Input은 pre-processing을 통해 범위를 표준화하고, 차원을 줄이고, 변수 간의 종속성을 제거할 수 있다. 제안된
제안된 방법론r은 이러한 Input을 직접적이고 쉽게 해석할 수 있는 방식으로 Output에 연결하는 것이다. - Sum of squared error를 Loss function으로하여 학습을 진행하며, 인공신경망의 Input과 Output 간의 관계를 효과적으로 표현하기 위해 SSE 측면에서 높은 근사 정확도를 얻을 수 있는 Random Forest를 적용한다.
- Random forest의 근사된 예측값과 인공신경망의 예측값 사이의 SSE를 최소화하는 과정을 통해 Random Forest로 인공신경망을 설명하려한다. 이때, Forest기반이기 때문에 여러 결정 규칙이 동시에 적용되어 혼란을 야기할 수 있다. 이 문제를 해결하기 위해 제안 방법론에서는 RF의 결정규칙을 재구성한다.
Case study
- 제안 방법론의 적용 가능성을 설명하기 위해 DRAM 제조 공장의 Job cycle time을 예측했다. JCT를 예측할 때 6가지 생산조건과 작업 속성이 고려되었다.
- k-means로 Clustering을 수행하고, 인공신경망으로 Job cycle time을 예측한 다음, RF로 예측 메커니즘을 근사하였다. 성능 평가 지표로 MAE, MAPE, RMSE를 사용하였다.
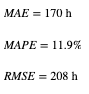
위 성능은 5개의 Cluster 중 첫 번째 Cluster의 예측값에 대한 성능을 나타낸 것이다.
Discussion
- 100번째 작업에 대해 Job cycle time prediction을 수행했을 때, MAE = 53.7h / MAPE = 4.1% / RMSE = 69.4h의 성능이 도출되었다.
- 추가적으로, Explanation methods끼리 비교 결과 Random Forest가 인공신경망의 예측값을 제일 정확하게 근사하는 것을 볼 수 있었다.
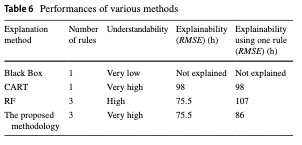
- 위 표는 다양한 예측 메커니즘 근사 방법론들을 비교 실험한 결과표인데, CART와 제안한 방법론 모두 예측 결과에 대한 이해도를 극대화 하였지만, CART는 예측값의 부정확한 근사로 인해 Explainability가 떨어지는 단점이 있다. 또한, 제안 방법론은 여러 의사 결정 규칙 중 하나의 규칙만 참조했을 때 이해도가 높은 방법론 중 가장 높은 설명력을 달성하였다.
Conclusion
- 분류 기반 인공신경망 방법은 Job cycle time prediction에 널리 사용되어 왔다. 그러나 이러한 방법론은 배경지식이 부족한 공장 작업자에게는 이해나 전달이 쉽지 않아 실용성에 한계가 있다. 이 문제를 해결하기 위해 본 연구에서는 2단계 XAI 접근법을 제안한다. 제안 방법론이 다른 비교 모델들 보다 Job cycle time prediction에 대한 이해도나 설명력을 높여줌을 보였다.
개인적인 생각
- 저자가 인공신경망을 최적화하는 게 본 논문의 목표가 아니라는 언급을 하긴 했지만, 성능 지표가 너무 안좋은게 아닌가 하는 생각이 든다. 분명 Discussion에는 가장 좋은 Job에 대한 결과를 보여주었을텐데 그렇게 만족스럽지 못한 결과를 보인다고 생각한다. 제조 현장에서 예측 시간이 하루나 이틀 차이나는 것은 생산 효율에 큰 차이를 불러올 것이기 때문이다. 따라서 제안 모델이 이해도와 설명력을 높이려다 더 중요한 성능을 놓친 연구가 아니었나 하는 생각이 든다.

Researcher
정리가 잘 된 글이네요. 도움이 됐습니다.