HTTP/0.9 - 2
HTTP/0.9 One-line Protocol
원래 HTTP 초기에는 버전이 존재하지 않았다.
HTTP/0.9은 이후에 차후 버전과 구별하기 위해 0.9로 불리기 시작
극히 단순한 구조, 요청은 단일 라인으로 구성되며 리소스에 대한 경로로 가능한 메서드는 GET유일
Request
GET /example.html
Response
<HTML>
이것은 예제 페이지
</HTML>이후에는 HTTP 헤더가 없었는데 이는 HTML 파일만 전송 가능하며, 다른 유형의 문서는 전송 불가능했고 상태 혹은 오류 코드도 존재하지 않았다
HTTP/1.0
HTTP/0.9의 매우 제한적인 성격 때문에 이것을 보완하기 위해 브라우저와 서버 모두 융통성을 가지도록 확장
Request
GET /example.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
example
<IMG src="/example.gif">
</HTML>
Reponse
GET /example.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(image content)
위의 Request와 Response를 보면 알 수 있듯이,
- 버전 정보가 각 요청 사이내로 전송되기 시작 (메소드 라인에 버전이 붙음)
- 상태 코드 라인 또한 응답의 시작 부분에 붙어 전송되어, 브라우저가 요청에 대한 성공과 실패를 알 수 있고 그 결과에 대한 동작(특정 방법으로 그것의 로컬 캐시를 갱신하거나 사용하는 것과 같은) 가능
- HTTP 헤더 개념은 요청과 응답 모두를 위해 도입되어, 메타데이터 전송을 허용하고 프로토콜을 극도로 유연하고 확장 가능
- 새로운 HTTP 헤더의 도움으로 Content-Type 덕분에 평이한 HTML 파일들 외에 다른 문서들을 전송하는 기능이 추가
HTTP/1.1 - 표준 프로토콜
첫번째 표준 버전인 HTTP/1.1은 HTTP/1.0이 나온지 몇 달 안되서 1997년 초에 공개 됨
- 파이프라이닝을 추가하여, 첫번째 요청에 대한 응답이 완전히 전송되기 이전에 두번째 요청 전송을 가능케 하여, 커뮤니케이션 레이턴시를 낮춤
- 청크된 응답 또한 지원
- 추가적인 캐시 제어 메커니즘이 도입
- 언어, 인코딩 혹은 타입을 포함한 컨텐츠 협상이 도입
- 라이언트와 서버로 하여금 교환하려는 가장 적합한 컨텐츠에 대한 동의 가능
- Host 헤더 덕분에, 동일 IP 주소에 다른 도메인을 호스트하는 기능이 CORS을 지원
HTTP/2
위의 내용 대로 HTTP 1.1이 표준 프로토콜이지만 1.1의 단점을 보완하고자 HTTP 2가 탄생
- HTTP가 유선 상에서 표현 방법을 대치 하는 것
- 성능에 초점
- 최종 사용자가 대기 시간, 네트워크 및 서버 리소스 사용을 인식
- 하나는 브라우저에서 웹 사이트로의 단일 연결을 허용하는 것
두 프로토콜의 객관적인 성능비교 지표는 테스트 환경과 각각 테스트시 외부 인터넷 품질등의 영향으로 정확하게 알 수는 없지만, 일반적으로 HTTP/2를 사용만 해도 웹 응답 속도가 HTTP/1.1에 비해 15~50%가 향상
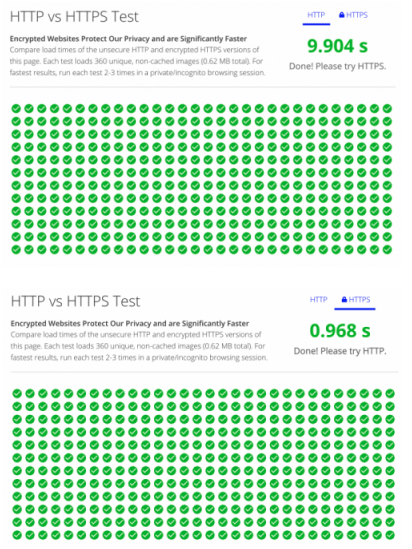
HTTP 1.1 동작 방식
- 기본적으로 Connectio당 하나의 요청을 처리하도록 설계
- 동시 전송 불가능, 요청과 응답이 순차적으로 처리
- HTTP 문서 안에 포함된 다수의 리소스(이미지, js, css)를 처리하려면 요청할 리소스 개수에 비례해서 Latency(대기 시간)이 길어짐
HTTP/1.1 한계
- HOL(Head of LIne) Blocking - 특정 응답의 지연
- Connection당 하나의 요청 처리를 개선할 수 있는 기법 중 파이프라이닝이 존재
- Connection을 통해서 다수개의 파일을 요청/응답 받을 수 있는 기법
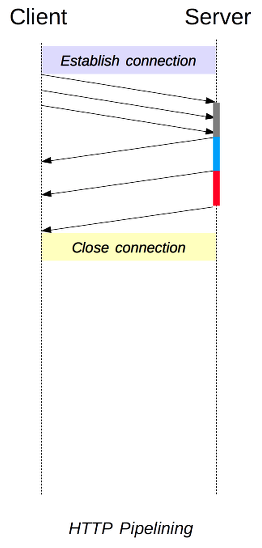
예제 스토리
하나의 TCP연결에서 3개의 이미지(1.jpg, 2.jpg, 3.jpg)를 요청하는 경우 HTTP 요청 순서 :
순서대로 1.jpg 이미지를 요청하고 응답 받고 다음 이미지를 요청하게 되는데 만약 1.jpg 이미지를 요청하고 응답이 지연되면 아래 그림과 같이 두, 세번째 이미지는 당연히 첫번째 이미지의 응답 처리가 완료되기 전까지 대기하게 되며 이와 같은 현상을 HTTP의 HOB(Head of Line Blocking) 이라 부르며 파이브라이닝 의 큰 문제점 중 하나이다.
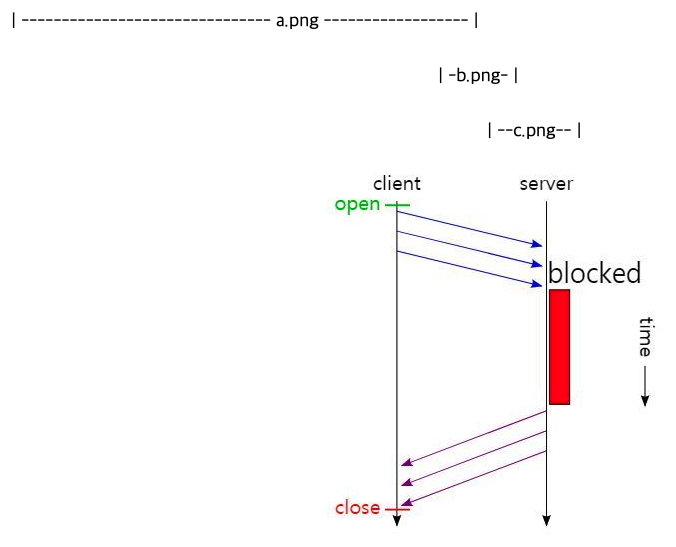
- RTT(Round Trip Time) 증가
- 일반적으로 하나의 Connection에 하나의 요청을 처리
- 요청별로 Connection을 만들게 되고 TCP 상에서 동작하는 HTTP 특성상 3-way Handshake가 반복적으로 일어나고 불필요한 RTT 증가와 네트워크 지연 현상을 초래해 성능을 저하 시킴
3-way Handshake란?
TCP는 장치들 사이에 논리적인 접속을 성립(establish)하기 위하여 three-way handshake를 사용
TCP 3 Way Handshake는 TCP/IP프로토콜을 이용해서 통신을 하는 응용프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미서로의 통신을 위한 관문(port)을 확인하고 연결하기 위하여 3번의 요청/응답 후에 연결
SYN - 동기화 (synchronize sequence numbers)
ACK - 응답 (acknowledgment)
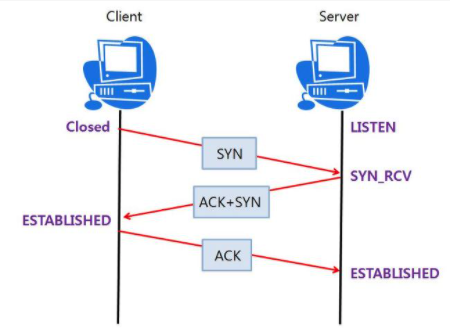
위의 그림을 보면서 이해해보자 먼저, Server에서 열려있는 포트는 LISTEN 상태이고 Client에서는 Closed 상태
- Client에서 Server에 연결 요청을 하기위해 SYN 데이터를 보낸다.
- Server에서 해당 포트는 LISTEN 상태에서 SYN 데이터를 받고 SYN_RCV로 상태가 변경(요청을 정상적으로 받았다는 대답(ACK)와 Client도 포트를 열어달라는 SYN 을 같이 보냄)
- Client에서는 SYN+ACK 를 받고 ESTABLISHED로 상태를 변경하고 서버에 요청을 잘 받았다는 ACK 를 전송(ACK를 받은 서버는 상태가 ESTABLSHED로 변경 => 이후 서로의 포트가 ESTABLSHED로 되면서 연결이 됨)
- 무거운 Header (Cookie)
- HTTP/1.1의 헤더에는 많은 메타 데이터들이 존재
- 매 요청 시 마다 중복된 Header 값을 전송하게 됨
- 전송하려는 값보다 헤더 값이 더 큰 경우도 존재
HTTP/1.1 한계 해결 방안
- Image Spriting
웹페이지를 구성하는 다양한 아이콘 이미지 파일의 요청 횟수를 줄이기 위해 아이콘을 하나의 큰 이미지로 만든다음 CSS에서 해당 이미지의 좌표 값을 지정해 표시 - Domain Sharding
요즘 브라우저들은 http/1.1이 단점을 극복하기 다수의 Connection을 생성해서 병렬로 요청을 보내기도 한다. 하지만 브라우저 별로 Domain당 Connection개수의 제한이 존재하고 이 또한 http/1.1의 근본 해결책은 아님. - Minify CSS/Javascript
http를 통해서 전송되는 데이터의 용량을 줄이기 위해 CSS, Javascript 코드를 축소하여 적용 - Data URI Scheme
Data URI Scheme은 HTML문서내 이미지 리소스를 Base64로 인코딩된 이미지 데이터로 직접 기술하는 방식이고 이를 통해 요청 수를 줄임 - Load Faster
스타일시트를 HTML 문서 상위에 배치, 스크립트를 HTML문서 하단에 배치
SPDY
- 위의 해결방안으로 근본적인 문제를 해결하지 못함
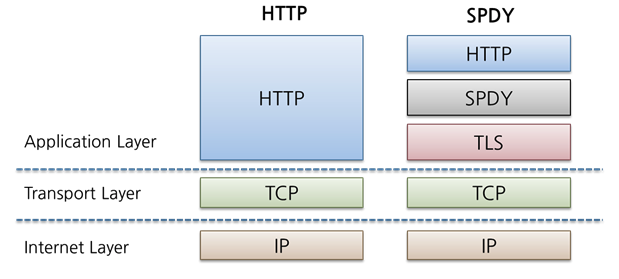
- 구글은 더 빠른 Web을 실현하기 위해 throughput 관점이 아닌 Latency 관점에서 HTTP를 고속화한 SPDY(스피디)라 불리는 새로운 프로토콜을 구현
- SPDY는 HTTP를 대치하는 프로토콜이 아니고 HTTP를 통한 전송을 재 정의하는 형태로 구현 SPDY는 실제로 HTTP/1.1에 비해 상당한 성능 향상과 효율성을 보여줬고 이는 HTTP/2 초안의 참고 규격이 됨
HTTP/2.0의 특징
-
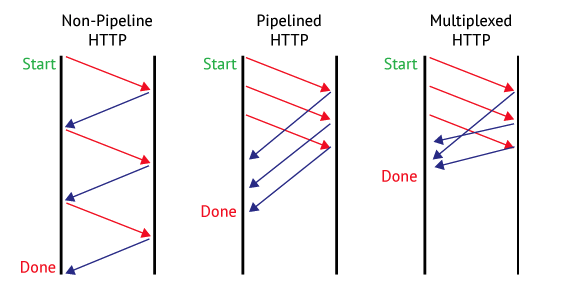
Multiplexed Streams
한 커넥션으로 동시에 여러개의 메세지를 주고 받을 있으며, 응답은 순서에 상관없이 stream으로 주고 받는다 HTTP/1.1의 Pipelining의 문제 개선
-
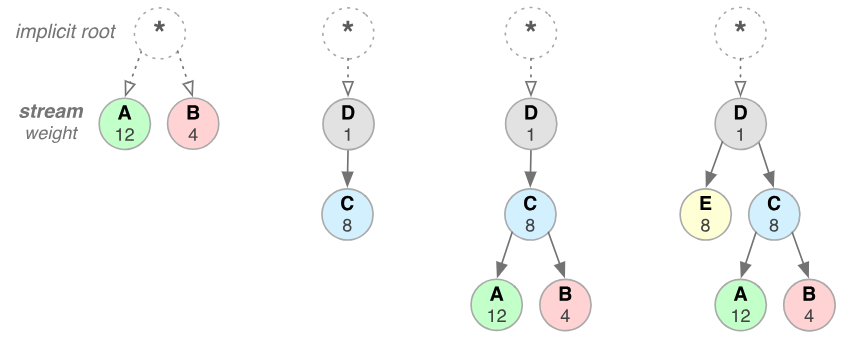
Stream Prioritization
예를 들면 클라이언트가 요청한 HTML문서안에 CSS파일 1개와 Image파일 2개가 존재하고 이를 클라이언트가 각각 요청하고 난 후 Image파일보다 CSS파일의 수신이 늦어지는 경우 브라우저의 렌더링이 늦어지는 문제가 발생하는데 HTTP/2의 경우 리소스간 의존관계(우선순위)를 설정하여 이런 문제를 해결
-
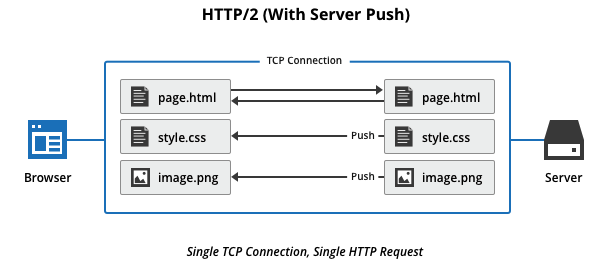
Server Push
서버는 클라이언트의 요청에 대해 요청하지도 않은 리소스를 마음대로 보냄
클라이언트가 HTML문서를 요청했고 해당 HTML에 여러개의 리소스(CSS, Image 등)가 포함되어 있는경우 HTTP/1.1에서 클라이언트는 요청한 HTML문서를 수신한 후 HTML문서를 해석하면서 필요한 리소스를 재 요청하는 반면 HTTP/2에선 Server Push기법을 통해서 클라이언트가 요청하지도 않은 (HTML문서에 포함된 리소스)리소스를 Push 해주는 방법으로 클라이언트의 요청을 최소화 해서 성능 향상
PUSH_PROMISE 라고 부르며 PUSH_PROMISE를 통해서 서버가 전송한 리소스에 대해선 클라이언트는 요청 x
- Header Compression
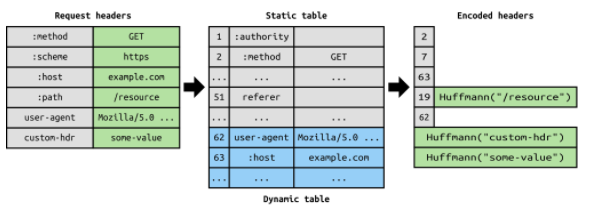
HTTP/2는 Header 정보를 압축하기 위해 Header Table과 Huffman Encoding 기법을 사용하여 처리하는데 이를 HPACK 압축방식이라 부르며 별도의 명세서(RFC 7531)로 관리
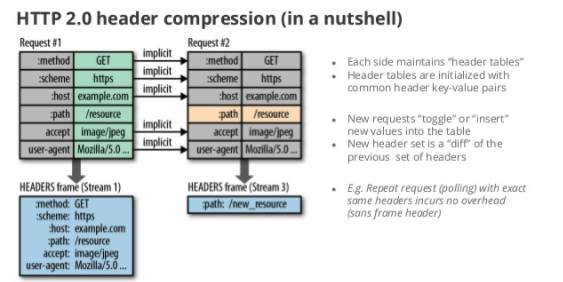
위 그림처럼 클라이언트가 두번의 요청을 보낸다고 가정하면 HTTP/1.x의 경우 두개의 요청 Header에 중복값이 존재해도 그냥 중복 전송하지만, HTTP/2에선 Header에 중복값이 존재하는 경우 Static/Dynamic Header Table 개념을 사용하여 중복 Header를 검출하고 중복된 Header는 index값만 전송하고 중복되지 않은 Header정보의 값은 Huffman Encoding 기법으로 인코딩 처리 하여 전송
HTTP Method

1. GET
GET [request-uri]?query_string HTTP/1.1
Host:[Hostname] 혹은 [IP]
---
요청받은 URI의 정보를 검색하여 응답
2. HEAD
HEAD [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
---
GET방식과 동일하지만, 응답에 BODY가 없고 응답코드와 HEAD만 응답
웹서버 정보확인, 헬스체크, 버젼확인, 최종 수정일자 확인등의 용도로 사용
3. POST
POST [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
Content-Lenght:[Length in Bytes]
Content-Type:[Content Type]
[데이터]
---
요청된 자원을 생성(CREATE)
새로 작성된 리소스인 경우,
HTTP헤더 항목 Location : URI주소를 포함하여 응답
4. PUT
PUT [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
Content-Lenght:[Length in Bytes]
Content-Type:[Content Type]
[데이터]
---
요청된 자원을 수정(UPDATE)
내용 갱신을 위주로 Location : URI를 보내지 않아도 됨
클라이언트측은 요청된 URI를 그대로 사용하는 것으로 간주
5. PATCH
PATCH [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
Content-Lenght:[Length in Bytes]
Content-Type:[Content Type]
[데이터]
---
PUT과 유사하게 요청된 자원을 수정(UPDATE)할 때 사용
PUT의 경우 자원 전체를 갱신하는 의미지만, PATCH는 해당자원의 일부를 교체하는 의미로 사용
6. DELETE
DELETE [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
---
요청된 자원을 삭제할 것을 요청함 (안전성 문제로 대부분의 서버에서 비활성)
7. CONNECT
CONNECT [request-uri] HTTP/1.1
Host:[Hostname] 혹은 [IP]
---
동적으로 터널 모드를 교환, 프락시 기능을 요청시 사용
8. TRACE
TRACE [request-uri] HTTP/ 1.1
Host: [Hostname] 혹은 [IP]
---
원격지 서버에 루프백 메시지 호출하기 위해 테스트용으로 사용
9. OPTIONS
OPTIONS [request-uri] HTTP/ 1.1
Host: [Hostname] 혹은 [IP]
---
웹서버에서 지원되는 메소드의 종류를 확인할 경우 사용POST와 PUT의 차이
POST는 보통 INSERT의 개념으로 사용되고, PUT은 UPDATE개념
POST는 멱등하지 않고 PUT은 멱등하다. 즉 동일한 자원을 여러번 POST 하면 서버자원에는 변화가 생기지만, 여러번 PUT하는 경우는 변화가 생기지 않는다.
예를들어 POST의 경우 클라이언트가 리소스의 위치를 지정하지 않는 경우 사용 (/dogs)
따라서, 아래와 같은 요청이 여러번 수행되는 경우 매번 새로운 dog가 생성되어 dogs/3, dogs/4 등 매번 새로운 자원이 생성(멱등하지 않음)
POST /dogs HTTP/1.1
{ "name": "blue", "age": 5 }
HTTP/1.1 201 Created반면 PUT의 경우는 클라이언트가 명확하게 리소스의 위치를 지정(/dogs/3)
아무리 많이 수행되더라도 리소스의 위치가 지정되어 새로운 자원이 생성되지 않으며 동일한 리소스(/dogs/3)를 수정하기 때문에 여러번 요청하더라도 멱등하다.
PUT /dogs/3 HTTP/1.1
{ "name": "blue", "age": 5 }PUT과 PATCH의 차이
PUT이 해당 자원의 전체를 교체하는 의미를 지니는 대신, PATCH는 일부를 변경한다는 의미를 지니기 때문에 최근 update 이벤트에서 PUT보다 더 의미적으로 적합하다고 평가받고 있음
PUT의 경우는 멱등하지만, PATCH의 경우는 멱등하지 않다. PUT은 전체 자원을 업데이트 하기 때문에 동일 자원에 대해서 동일하게 PUT을 처리하는 경우 멱등하게 처리된다. 반면 PATCH로 처리되는 경우 자원의 일부가 변경되기 때문에 멱등성을 보장할 수 없음
멱등성이란?
멱등(idempotent)의 의미는 같은 작업을 계속 반복해도 같은 결과가 나오는 경우를 의미한다. 동일한 자원에 대한 GET요청이라면 클라이언트에 반환되는 모든 응답은 동일해야 한다. 특정 자원에 대한 DELETE의 경우도 자원은 더이상 이용할 수 없어야 하며, DELETE요청을 다시 호출한 경우도 자원은 여전히 사용할 수 없는 상태야여 한다.
CORS(Cross-Origin Resource Sharing)이란?
추가 HTTP 헤더를 사용하여, 한 출처에서 실행 중인 웹 애플리케이션이 다른 출처의 선택한 자원에 접근할 수 있는 권한을 부여하도록 브라우저에 알려주는 체제
웹 애플리케이션은 리소스가 자신의 출처(도메인, 프로토콜, 포트)와 다를 때 교차 출처 HTTP 요청을 실행
사용되는 케이스
- XMLHttpRequest와 Fetch API 호출
- 웹 폰트(CSS 내 @font-face에서 교차 도메인 폰트 사용 시),
- WebGL 텍스쳐.
- drawImage()를 사용해 캔버스에 그린 이미지/비디오 프레임.
- 이미지로부터 추출하는 CSS Shapes
CORS 요청 예제
https://domain-a.com의 프론트 엔드 JavaScript 코드가 XMLHttpRequest를 사용하여 https://domain-b.com/data.json을 요청하는 경우
보안 상의 이유로 동일 출처 정책(same-origin policy)에 따라 브라우저는 스크립트에서 시작한 교차 출처 HTTP 요청을 제한
동일 출처 정책(Same-Origin policy)이란?
불러온문서나 스크립트가 다른 출처에서 가져온 리소스와 상호작용하는 것을 제한하는 중요한 보안 방식입니다. 이것은 잠재적 악성 문서를 격리하여, 공격 경로를 줄이는데 도움이 됩니다.
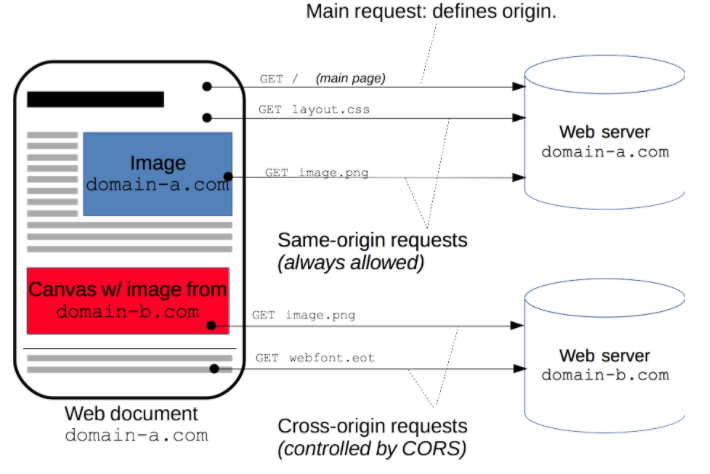
위의 그림의 상단 흐름처럼 XMLHttpRequest와 Fetch API는 동일 출처 정책을 따르기 때문에 JavaScript의 ajax 통신 시 자신의 출처와 동일한 리소스만 불러오는게 가능
즉, 하단 흐름처럼 다른 출처(도메인, 프로토콜, 포트)가 다른 리소를 불러오려면 그 출처에서 올바른 CORS 포함(CORS 허용 코드)를 포함한 응답을 보내야 함
CORS 해결 방법
1. 서버 쪽에서 cross-origin HTTP 요청을 허가
가장 간단한 설정 방법!
CORS 미들웨어를 사용한 요청 허가
const express = require('express');
const cors = require('cors');
const app = express();
// 위처럼 하면 모든 요청에 대해 허가하면 보안에 취약!
// 아래와 같이 해당 요청에 대해서만 허가 해줄 수 있다
보안적으로 취약해질 수 있겠죠?
const corsOptions = {
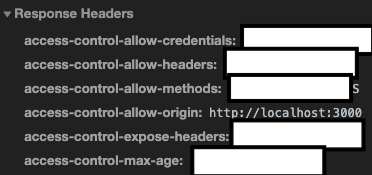
origin: 'http://localhost:3000', // 허락하고자 하는 요청 주소
credentials: true, // true로 하면 설정한 내용을 response 헤더에 추가 해줍니다.
};
app.use(cors(corsOptions)); // config 추가아래의 사진처럼 서버는 Access-Control-Allow-Origin 헤더를 다시 전송하여 요청을 허가
'*' 으로 응답을 했으니 모든 도메인에서 접근을 허용한다는 것을 알 수 있음

만약 원하는 도메인에서만 요청을 허용하고 그 이외의 요청을 거부하려면 아래 사진과 같이 localhost:3000에 대해서만 origin 설정을 해주면 된다
2. 클라이언트 쪽에서 크롬 익스텐션을 통한 허가
이것은 임시방편이므로 나중에 본격적인 서비스를 하려면 서버쪽에서 설정해 주는 것이 바람직하다
크롬 웹스토어에 가면 CORS 요청허가 확장 프로그램을 설치해서 설정해 주면 요청을 허가 할 수 있다
참고사이트
- https://developer.mozilla.org/ko/docs/Web/HTTP/CORS
- https://velog.io/@wlsdud2194/cors
- https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
- https://ijbgo.tistory.com/26
- https://mindnet.tistory.com/entry/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-22%ED%8E%B8-TCP-3-WayHandshake-4-WayHandshake
- https://javaplant.tistory.com/18
