우선 제목처럼 에러는 아니다!! 하지만 이 문제를 발견했을 당시 나에겐 큰 에러였다..
누군가 같은 문제를 만났을 때 정확한 원인을 알고 문제를 검색할거 같지 않아서 제목으로 어그로를 끌어보았다.
핵심을 간단하게 짚고 가자면 한글이라고 다 같은 한글이 아니다.
글보단 사진으로 확인해보자!!
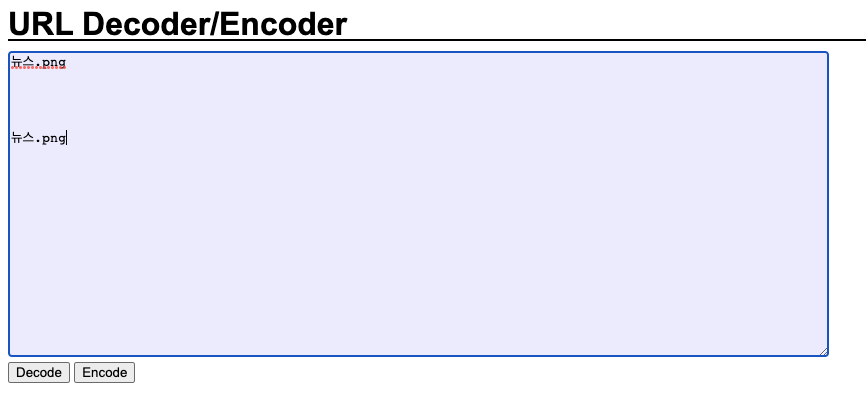
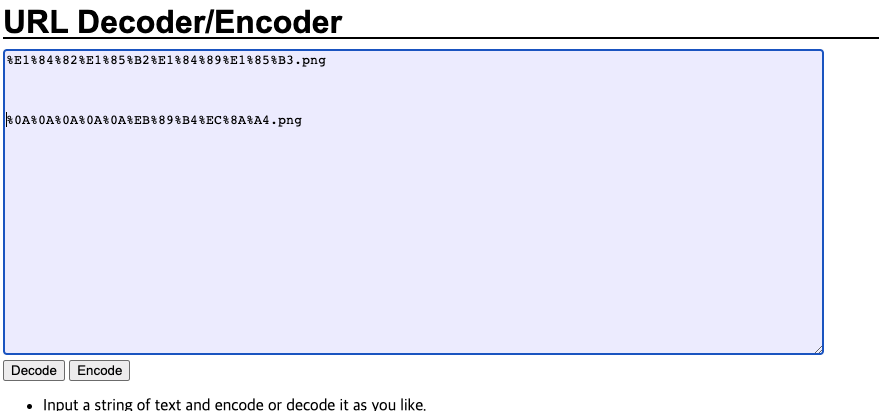
분명 같은 뉴스.png라는 한글인데 인코딩이 다르게 된것이 보이는가..?
이것이 예상하지 못한 결과를 반환하게 하는 원인이였다. 이제 두 결과가 다른 이유에 대해서 알아보자!!
컴퓨터에서는 한글을 두 가지로 구분할 수 있다. 조합형 / 완성형이다.
바쁘다 바빠 현대 사회 핵심 사진만 보고 넘어가자
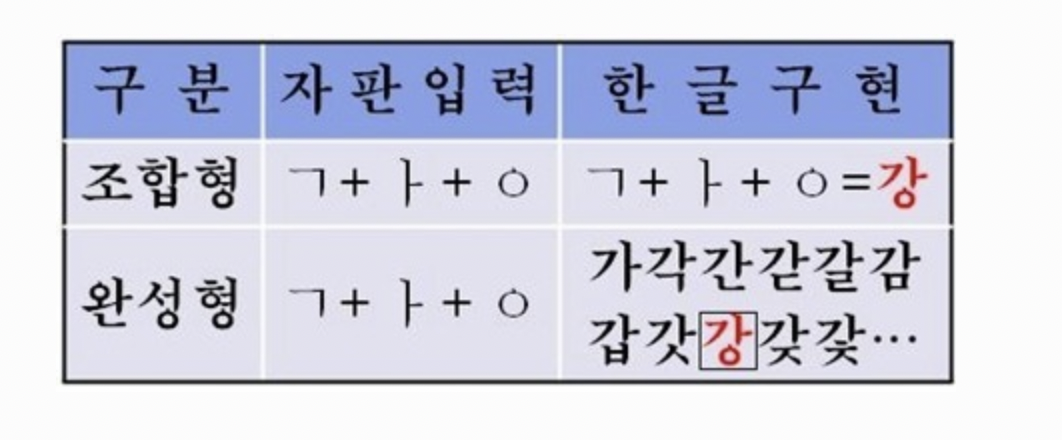
사진을 보면 차이를 단번에 알 수 있다. 맥북은 조합형을 지원한다.
S3에 사진 제목이 들어갈 때 완성형을 지원하는 윈도우로 저장을 하고 만약, 파일이름으로 S3에 저장된 파일을 찾는 API가 있다면 의도치 않은 결과(뉴스라는 파일이 실제론 존재하지만 내가 맥에서 뉴스라는 이름으로 검색을 했을 시 없다는 결과)가 나올 수 있다.
이것에 대해 확실히 알 수 있는 것은, 맥을 쓰는 친구가 바보라는 이름의 파일을 윈도우를 쓰는 나에게 파일을 보내준다면 'ㅂㅏㅂㅗ' 라는 이름으로 내 pc에 저장된다.
한글을 사용할때는 항상 이런 점을 주의하면서 사용하자!!
추가 문제점.
Swagger와 Postman의 인코딩 차이점.
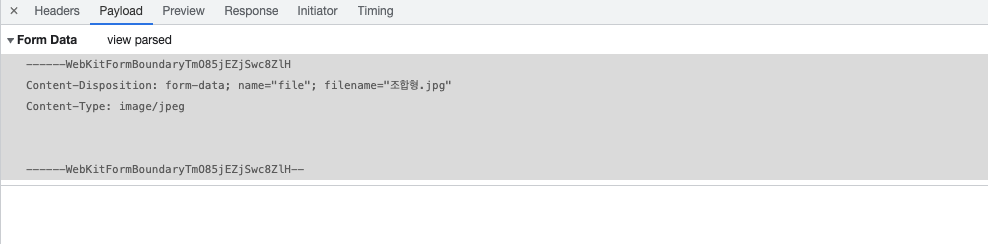
위 사진이 SWAGGER
둘의 차이가 보이시나요??
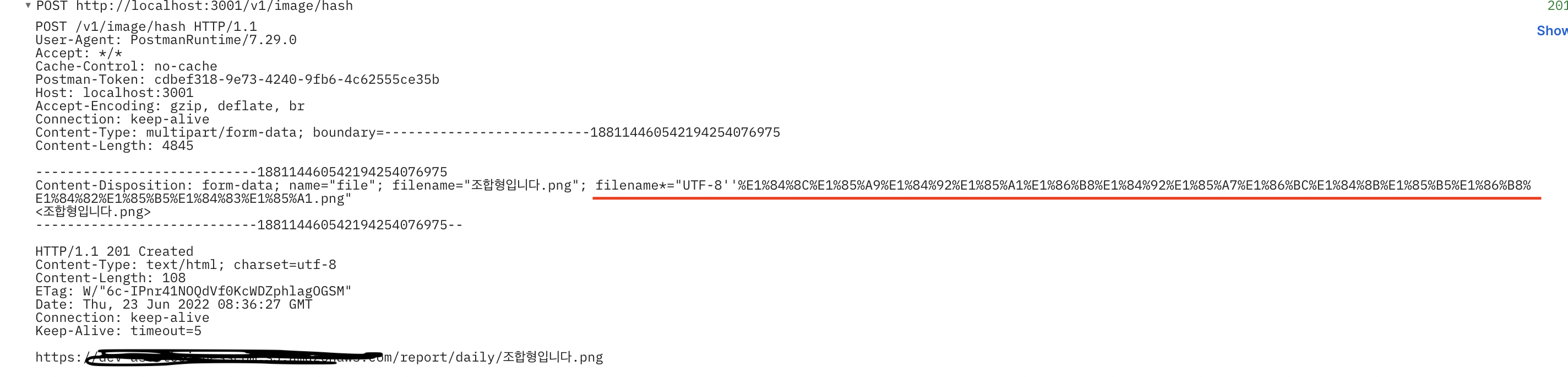
filename*='UTF-8' 포스트맨은 인코딩형식을 지정해주지만 SWAGGER는 그냥 원본 그대로를 전해줍니다.
이것의 이유는 브라우저 측에서 헤더의 "파일 이름" 부분에 있는 그대로 이름을 전달합니다.
"filename" 사용과 관련된 또 다른 문제는 브라우저의 formdata는 filename='UTF-8'을 사용하지 않으며 RFC7578에 보면 value of the "name" parameter is the original field name from구문이 있습니다.
이것의 의미는 utf-8이 이전 동작과 일치하도록 해석하거나 인코딩에 대한 가정을 하지 않기 위해 원시 문자열을 전달하는 것.이 아닐까 싶습니다.
또한, 클라이언트는 RFC5987 에 정의된 형식(인코딩된 단어)을 사용하여 non-latin1 헤더 매개변수 값을 전송해야 합니다 . 그들이 그것을 보내지 않으면 값은 latin1로 인코딩된 것으로 간주됩니다.
해결 방법으로는 Buffer.from(filename, 'latin1').toString('utf8')을 해주시면 됩니다.
busboy 0.x 버전은 포스트맨이 한글이 깨지고 swagger는 깨지지 않는다. busboy 1.x 버전은 swagger가 깨지고 포스트맨이 깨지지가 않는데 이 것은 busboy가 0.x 버전은 내부적으로 file이름이 들어왔을 때
Buffer.from(filename, 'latin1').toString('utf8')이런 동작이 있었던 것 같다. 그래서 postman에서는 인코딩되서 들어오기 때문에 다시 인코딩하는 과정에서 뭔가 이상해져 파일 이름이 Swagger에서만 정상 동작하고 Postman에서는 비정상 동작을 했던 것 같다. 그리고 현재 1.x 버전은 이런 작업이 빠져있어 Postman에서는 정상동작하고 Swagger에서는 비정상 동작을 하는것 같다. 그래서 위에 적어준대로 file.originalname = Buffer.from(filename, 'latin1').toString('utf8')을 해주고 파일 이름을 본다면 스웨거에서는 정상동작 포스트맨에서는 비정장 동작을 하는 것을 알 수 있다. 포스트맨에서는 여전히 utf8로 인코딩해서 보내니 이것이 busboy 내에서 아무 동작을 하지 않고 swagger에서 정상동작하기 위해 latin1으로 인코딩하는 과정에서 latin1이 한글 인코딩이 되지 않기 때문에 이상한 글자가 되버리는 것 같다.
busboy 내부는 아직 뜯어보질 않아서 잘 모르겠지만 내 추측은 그렇다!!
또한, 이 과정에서 같은 한글이라도 인코딩을 보면
encodeURIComponent를 이용해서 Nest에서 인코딩을하면 %ED%8C%8C%EC%9D%BC%EC%A1%B4%EC%9E%AC%EC%97%AC%EB%B6%80이 되고
포스트맨이 인코딩해서 보내주는 값이 %E1%84%91%E1%85%A1%E1%84%8B%E1%85%B5%E1%86%AF%E1%84%8C%E1%85%A9%E1%86%AB%E1%84%8C%E1%85%A2%E1%84%8B%E1%85%A7%E1%84%87%E1%85%AE와 같이 되는데 이 차이는 모르겠다.
두 가지 전부 디코딩 해보면 같은 결과값이지만 두 개의 차이가 있다. 이 부분을 알아봐야겠다.

혹시 그 뒤로 어떻게되었나요?