
이번엔 다중 컬럼 인덱스를 사용했을때 WHERE 문에 사용하는 컬럼의 순서는 중요한가? 에 대해 알아보겠습니다.
사전 지식
B-Tree
B-Tree 는 자가 군형 이진 검색 트리의 일종으로 여러 키를 각 노드에 저장할 수 있는 구조를 가지고 있습니다.
정의 및 특성
다중 키 저장: B-Tree 는 각 노드가 여러 개의 키를 저장할 수 있으며, 이로 인해 높이를 낮추고 검색 속도를 높이는 데 기여합니다. 각 내부 노드는 최대 n-1 개의 키와 n 개의 자식 노드를 가질 수 있습니다.
균형 유지: 모든 리프 노드는 동일한 깊이에 위치하여 균형을 유지합니다. 이 특성 덕분에 B-Tree는 검색, 삽입 및 삭제 작업에서 시간 복잡도가 O(log n) 을 보장합니다.
노드 구조
- 내부 노드: 키와 자식 노드를 포함하며, 각 키는 자식 노드 간의 범위를 정의합니다.
- 리프 노드: 실제 데이터가 저장되거나 참조되는 곳으로, 모든 리프 노드는 동일한 깊이에 위치합니다.
동작 방식
1. 검색
- 루트 노드에서 시작하여 현재 노드의 키와 비교합니다.
- 찾고자 하는 키가 현재 노드의 첫 번째 키보다 작으면 왼쪽 자식으로 이동하고, 그렇지 않으면 오른쪽 자식으로 이동하여 비교를 계속합니다.
2. 삽입
- 새로운 키를 리프 노드에 추가하고, 만약 해당 노드가 최대 키 수를 초과하면 분할(splitting) 작업을 수행합니다.
- 분할된 중간 키는 부모 노드로 올라가며, 이로 인해 트리가 균형을 유지합니다.
3. 삭제
- 삭제할 키가 리프 노드에 존재하는 경우 직접 삭제하며, 만약 내부 노드에 있다면 그 키를 대체할 후계자나 선행자를 찾아 대체한 후 삭제합니다.
- 삭제 후 최소 키 수 조건이 위반되면 형제와 병합 작업을 통해 균형을 유지합니다.
장점
-
효율적인 디스크 접근: B-Tree 는 디스크 접근 시간을 최소화하기 위해 설계되어있으며, 많은 양의 데이터를 한번에 처리할 수 있어 디스크 I/O 작업을 줄입니다.
-
높은 성능: 대량의 데이터를 처리하면서도 성능 저하 없이 빠른 검색 속도를 유지할 수 있습니다.
단점
-
구조 유지 비용: B-Tree는 데이터 삽입, 삭제 및 수정 시 균형을 유지해야 하므로 이 과정에서 추가적인 연산이 필요하여 성능 저하를 초래할 수 있습니다.
-
높은 메모리 사용량: B-Tree는 각 노드에 여러 키와 포인터를 저장하므로, 메모리 사용량이 증가할 수 있습니다. 특히, 데이터가 적고 키가 많은 경우에는 비효율적일 수 있습니다.
-
전체 스캔 시 비효율성: B-Tree에서 모든 데이터를 순회하려면 리프 노드까지 가야하므로, 모든 노드를 방문해야 합니다. 이로 인해 전체 데이터 스캔(full scan) 시 비효율성이 발생합니다.
-
부등호 연산의 비효율성: B-Tree는 부등호 (< , >) 연산에 최적화되어 있지 않기 때문에 이러한 연산이 자주 발생하는 경우 성능이 떨어질 수 있습니다. 부등호 연산은 특정 범위의 값을 찾기 위해 여러 노드를 방문해야 할 수 있으므로, 이로 인해 검색 시간이 증가할 수 있습니다.
-
키 중복 문제: B-Tree에서는 동일한 키가 여러 번 존재할 수 있으며, 이는 중복된 키를 처리하는 데 추가적인 복잡성을 초래합니다. 특히 중간 노드에서 키가 중복될 수 있어서 관리가 복잡해질 수 있습니다.
-
데이터 분포에 따른 성능 저하: 데이터의 분포가 고르지 않거나 특정 값에 집중되어 있는 경우, B-Tree의 성능이 저하될 수 있습니다. 예를 들어, 특정 범위의 값만 자주 조회되는 경우에는 인덱스의 효율성이 떨어질 수 있습니다.
다중 컬럼 Index
구조
-
여러 컬럼을 조합하여 하나의 B-Tree 구조로 생성됩니다.
-
첫 번째 컬럼을 기준으로 정렬되고, 그 다음 컬럼 순으로 정렬됩니다.
-
각 노드는 (컬럼1값, 컬럼2값..., 레코드 포인터) 형태로 구성됩니다.
검색 과정
1. 탐색: 첫 번째 컬럼 값으로 B-Tree를 탐색합니다.
2. 필터링: 첫 번째 컬럼 값이 일치하면, 두 번째 컬럼 값으로 추가 필터링 합니다.
3. 반복: 이 과정을 인덱스에 포함된 모든 컬럼에 대해 반복합니다.
4. 접근: 최종적으로 찾은 레코드 포인터로 실제 데이터 접근합니다.
정렬
- 인덱스 컬럼의 순서대로 자동으로 정렬됩니다.
- 첫 번째 컬럼 값이 같을 경우, 두 번째 컬럼 값으로 정렬되는 식으로 진행됩니다.
장점
-
복합 조건 검색 성능 향상: 여러 컬럼을 조합한 조건 검색 시 매우 효율적입니다.
-
인덱스 커버링: 인덱스만으로 쿼리를 처리할 수 있는 경우가 증가합니다.
-
정렬 및 그룹화 최적화: 인덱스 컬럼 순서로 정렬이나 그룹화 시 성능이 향상됩니다.
-
저장 공간 효율: 여러 단일 컬럼 인덱스 대신 하나의 다중 컬럼 인덱스를 사용하여 공간을 절약할 수 있습니다.
단점
-
유연성 제한: 컬럼 순서가 중요하며, 순서가 맞지 않으면 인덱스를 활용하지 못할 수 있습니다.
-
업데이트 비용 증가: 인덱스에 포함된 컬럼이 수정될 때마다 인덱스 업데이트가 필요합니다.
-
첫 번째 컬럼 의존성: 첫 번째 컬럼이 조건에 없으면 인덱스 효율이 떨어집니다.
-
범위 검색 제한: 범위 조건 이후의 컬럼들은 인덱스 활용도가 떨어집니다.
-
인덱스 설계의 복잡성: 적절한 컬럼 조합과 순서를 결정하는 것이 어려울 수 있습니다.
Explain With 다중 컬럼 인덱스
조건문에서의 순서가 인덱스 생성 순서와 다를 때 성능이 저하되는 이유는 B-Tree 의 구조와 검색 방식 때문입니다.
B-Tree 구조
- 멀티 인덱스는 첫 번째 컬럼 기준으로 정렬되고, 그 다음 컬럼 순으로 정렬됩니다.
CREATE INDEX idx_category_status ON campaign(category, status);- 위에서 만든 Index를 예로 보자면,
category로 정렬 후category가 같은 값 내에서status로 정렬됩니다.
Root
├── Node1 (Column1 Range)
│ ├── Leaf1 (Column2 Range)
│ └── Leaf2 (Column2 Range)
└── Node2 (Column1 Range)
├── Leaf3 (Column2 Range)
└── Leaf4 (Column2 Range)검색 과정
- B-Tree 는 루트에서 리프 노드까지 순차적으로 탐색합니다.
- 첫 번째 컬럼 값으로 시작해 순서대로 비교하며 내려갑니다.
효율성 저하 원인
- 인덱스 순서와 다른 조건 사용 시, 첫 번째 컬럼을 사용하지 않으면 전체 인덱스를 스캔해야 할 수 있습니다(full scan).
- 예) 인덱스에서
WHERE status = 'processing'인 쿼리가 발생하면category의 모든 값에 대해status를 검사해야 합니다.
성능 영향
- 불필요한 인덱스 스캔으로 I/O 작업이 증가합니다.
- 조건 필터링 효율이 떨어져 더 많은 데이터를 검사해야 합니다.
최적화 제한
- 데이터베이스 옵티마이저가 효율적인 실행 계획을 세우기 어려워집니다.
그렇다면 진짜로 컬럼 순서를 바꿧을때도 데이터를 찾는 실행계획이 달라질까?
테이블
create table campaign
(
id bigint auto_increment
primary key,
category varchar(255) not null,
status varchar(255) not null,
type varchar(255) not null,
name varchar(255) not null,
jd_id bigint null,
banner_id bigint null,
retail_price int not null,
discount_rate int null,
discount_amount int null,
sale_price int not null,
start_date datetime not null,
end_date datetime not null,
created_time datetime not null,
updated_time datetime null
);
create index idx_category_stats
on campaign (category, status);실행 계획
EXPLAIN SELECT * FROM campaign WHERE category = 'SHOP' AND status = 'processing';
EXPLAIN SELECT * FROM campaign WHERE status = 'processing' and category = 'SHOP';인덱스 순서대로 실행계획을 실행했을때
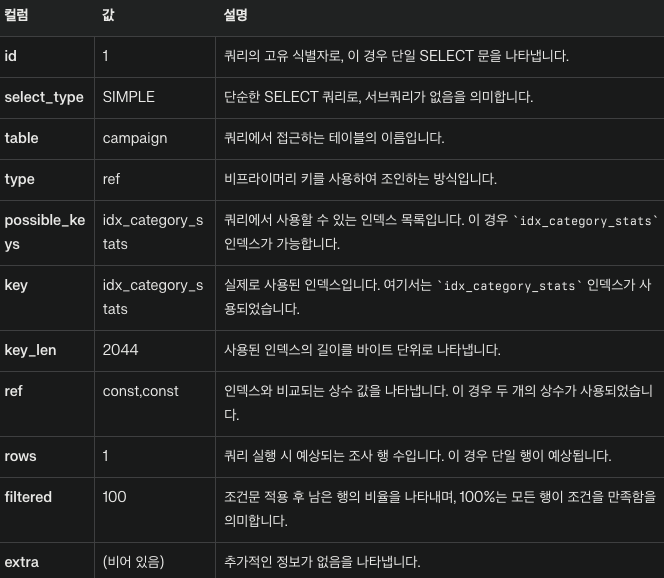
인덱스 순서를 반대로 실행계획을 실행했을때
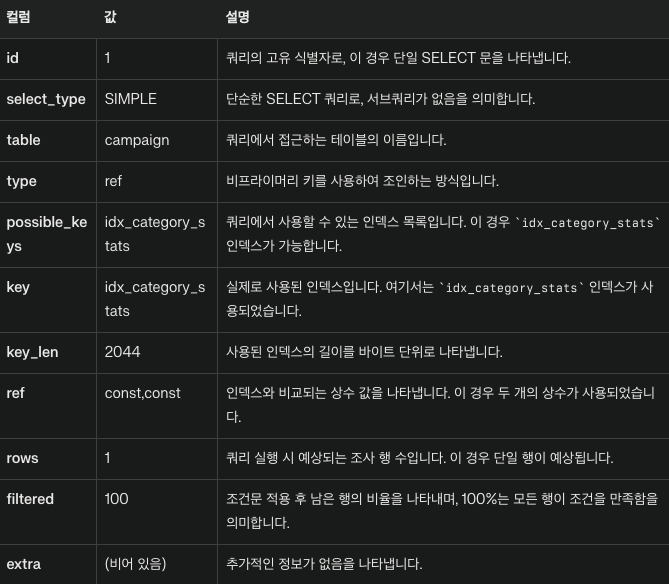
이미지를 보면 차이가 있을까요?
네 이상하게도 차이가 없습니다.
분명 다중 컬럼 Index 를 사용하면 순서가 중요하다고 하였는데 이상합니다.
그 이유는 MySQL 의 옵티마이저가 최적화를 진행하여 쿼리를 실행할 때 가장 효율적인 실행 계획을 선택합니다.
다중 컬럼 인덱스에서 옵티마이저의 동작 방식
1. 인덱스 구조 분석: 옵티마이저는 테이블의 인덱스 구조를 분석합니다. 복합 인덱스인 idx_category_stats 가 (category, status) 순서대로 생성되어 있음을 인식합니다.
2. 조건 평가: WHERE 절의 조건을 평가하여 사용 가능한 인덱스를 식별합니다. 이 경우 category 와 status 모두 조건에 사용되어있으므로, 복합 인덱스를 활용할 수 있다고 판단합니다.
3. 최적 실행 계획 선택: 옵티마이저는 인덱스의 실제 순서 (category, status) 를 고려하여 가장 효율적인 실행 계획을 선택합니다. WHERE 절의 조건 순서와 관계없이 인덱스의 실제 구조에 맞춰 최적화를 수행합니다.
왜 순서가 중요하지 않지?
1. 인덱스 구조 인식: 옵티마이저는 인덱스의 실제 구조를 알고 있으므로, WHERE 절의 조건 순서와 관계 없이 인덱스를 효과적으로 사용할 수 있습니다.
2. 조건 재배열: 필요한 경우 옵티마이저는 내부적으로 조건의 순서를 재배열하여 인덱스를 최적으로 활용합니다.
3. 통계 정보 활용: MySQL은 테이블과 인덱스의 통계 정보를 활용하여 가장 효율적인 실행 계획을 선택합니다.
옵티마이저 최적화 방법
옵티마이저가 최적화하여 쿼리를 최적화 하여 실행한다는데 어떻게 최적화를 시키지?
1. 인덱스 스캔 방식 선택: 옵티마이저는 인덱스 스캔 방식 (인덱스 범위 스캔, 인덱스 풀 스캔 등) 을 선택합니다.
2. 선택도 고려: 각 컬럼의 선택도(Selectivity) 를 고려하여 가장 효율적인 순서로 조건을 적용합니다.
3. 실행 비용 추정: 다양한 실행 계획의 비용을 추정하고 가장 낮은 비용의 계획을 선택합니다.
그렇다면 하나씩 조회 했을때는 어떻게 나올까
EXPLAIN SELECT * FROM campaign WHERE category = 'SHOP';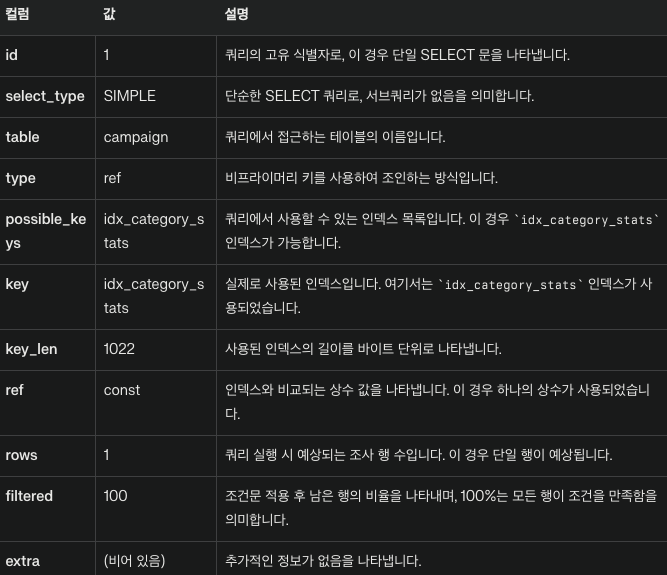
EXPLAIN SELECT * FROM campaign WHERE status = 'processing';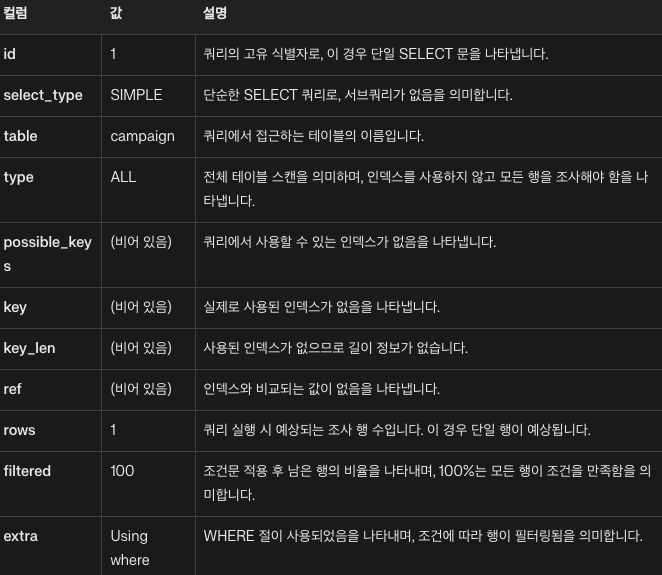
이제 결과가 서로 다르게 나오게 되는데 그이유는 무엇인지 알아봐야겠죠.
복합 인덱스인 idx_category_stats 는 (category, status) 순으로 생성되어있습니다.
인덱스의 구조는 다음과 같은 특성을 가집니다.
1. 왼쪽 우선 원칙: 복합 인덱스는 왼쪽에서 오른쪽 순차적으로 구성됩니다. 즉, category 가 첫 번째 컬럼이고 status가 두 번째 컬럼입니다.
2. 부분 인덱스 사용: 복합 인덱스의 왼쪽 부문만 사용하는 쿼리도 해당 인덱스를 활용할 수 있습니다.
성능 차이의 이유
- 인덱스 구조: 복합 인덱스는
(category, status)순서로 정렬되어 있습니다.category값으로 먼저 정렬된 후 같은category내에서status로 정렬됩니다. - 왼쪽 우선 원칙: MySQL 은 복합 인덱스의 왼쪽부터 순차적으로 사용합니다.
category만 조회할 때는 인덱스의 첫 부분을 사용할 수 있지만,status만 조회할 때는 인덱스를 효과적으로 사용할 수 없습니다. - 옵티마지어의 판단:
status만으로 조회할 때, 옵티마이저는 인덱스를 사용하는것 보다 전체 테이블 스캔이 더 효율적이라고 판단합니다. 이는status값의 분포와 전체 데이터 양을 고려한 결정입니다. - 선택도(Selectivity):
category가status보다 선택도가 높다고 가정했을 때, MySQL은category조회에 인덱스를 사용하는 것이 더 효율적이라고 판단합니다.- 그렇다면 왜 MySQ 에서
category가 선택도가 더 높다고 가정을 햇을까?- 데이터 분포
- 중복 데이터 비율:
category컬럼의 값이 상대적으로 적은 중복을 가지면, 선택도가 높아집니다. 예를 들어, 특정 카테고리 값이 전체 데이터의 일부만 차지하고 있다면, 해당 카테고리로 조회할 때 많은 행이 선택될 수 있습니다. - 카디널리티:
category가 가지는 고유한 값의 수(NDV, Number of Distinct Values)가 많다면, 선택도가 높아질 가능성이 큽니다. 반면status가 가지는 고유한 값이 적다면, 선택도가 낮아질 수 있습니다.
- 중복 데이터 비율:
- 쿼리 패턴
• 자주 사용되는 조건: 쿼리에서 자주 사용되는 조건으로category가 포함된다면, 옵티마이저는 이 컬럼의 선택도를 높게 평가할 수 있습니다. 예를 들어, 특정 카테고리에 대한 쿼리가 빈번하게 발생하면, 해당 카테고리에 대한 인덱스 활용이 더 효과적일 것으로 판단합니다. - 통계 정보
• MySQL 통계: MySQL은 테이블과 인덱스에 대한 통계 정보를 유지합니다. 이 통계는 각 컬럼의 카디널리티와 분포를 기반으로 하여 옵티마이저가 쿼리를 최적화하는 데 사용됩니다. 예를 들어,category의 통계 정보가 업데이트되어 높은 카디널리티를 나타내면, 옵티마이저는 이 컬럼을 더 신뢰하고 효율적으로 사용할 수 있다고 판단합니다.
- 데이터 분포
- 그렇다면 왜 MySQ 에서
그렇다면 category만 조회했을때와 동일하게 status 컬럼을 검색해도 인덱스를 사용할 수 없나?
1. 단일 인덱스 생성
- 가장 간단한 방법으로는
status컬럼에 대해 별도의 단일 인덱스를 생성하는 방법입니다.
CREATE INDEX idx_status ON campaign(status);이렇게 INDEX를 설정하고 쿼리를 실행하면 옵티마이저는 idx_status 인덱스를 사용하여 빠르게 결과를 반환할 수 있습니다.
2. 조건부 인덱스 (Partial Index)
MySQL 에서는 조건부 인덱스를 직접 지원하지 않지만, 특정 값에 대한 인덱스를 만들고 싶다면, 이를 위해 별도의 테이블을 사용하는 방법이 있습니다.
예를 들어, status 가 processing 인 경우만을 위한 테이블을 만들고 해당 테이블에 인덱스를 설정할 수 있습니다.
- 1. 테이블 분리: Processing 과 Done 이라는 두 개의 테이블을 만들어 Processing 테이블에는 status 가 processing 인 데이터만 저장하고 나머지는 Done 테이블에 저장합니다.
- 2. 인덱스 추가: 인덱스 추가: Processing 테이블에 대해 필요한 인덱스를 추가
- 3. 데이터 이동: 상태가 변경된 데이터는
Processing에서Done으로 이동합니다.
CREATE TABLE Processing (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
category VARCHAR(255) NOT NULL,
status VARCHAR(255) NOT NULL,
...
);
CREATE TABLE Done (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
category VARCHAR(255) NOT NULL,
status VARCHAR(255) NOT NULL,
...
);CREATE INDEX idx_processing ON Processing(status);3. bit 필드 사용
상태가 제한된 경우 (예: 두 가지 상태만 존재하는 경우), 문자열 대신 bit 필드를 사용하는 것도 고려할 수 있습니다.
예를 들어, 상태가 0 또는 1로 이루어진 데이터로 표현할 수 있다면 데이터 크기를 줄이고 조회 성능을 향상시킬 수 있습니다.
ALTER TABLE campaign ADD COLUMN status_bit TINYINT(1);이후, 상태를 bit로 변환하여 쿼리를 작성
SELECT * FROM campaign WHERE status_bit = 1; -- processing4. 쿼리 최적화
쿼리를 최적화하여 인덱스 사용을 유도하는 방법도 있습니다. 예를 들어, 여러 조건을 결합하여 사용할 때 인덱스의 순서를 조정하거나, 필요 시 옵티마이저에게 특정 인덱스를 사용하도록 지시할 수 있습니다.
SELECT * FROM campaign USE INDEX (idx_status) WHERE status = '22';요약
1. B-Tree 구조: 다중 컬럼 인덱스는 B-Tree 구조를 기반으로 하며, 첫 번째 컬럼을 기준으로 정렬된 후 순차적으로 다음 컬럼들이 정렬됩니다.
2. 인덱스 순서의 중요성: 이론적으로는 인덱스 생성 순서와 WHERE 절의 조건 순서가 일치해야 최적의 성능을 낼 수 있습니다.
3. 옵티마이저의 역활: MySQL의 옵티마이저는 쿼리를 분석하고 최적의 실행 계획을 선택합니다. 이 과정에서 WHERE 절의 조건 순서와 관계없이 효율적인 인덱스 사용을 가능하게 합니다.
4. 부분 인덱스 활용: 복합 인덥스의 왼쪽 부분만 사용하는 쿼리도 해당 인덱스를 효과적으로 활용할 수 있습니다.
5. 선택도(Selectivity)의 영향: 컬럼의 선택도는 인덱스 효율성에 큰 영향을 미칩니다. 높은 선택도를 가진 컬럼이 인덱스의 첫 번째 컬럼으로 오는 것이 일반적으로 더 효율적입니다.
6. 인덱스 최적화 방법: 단일 인덱스 추가, 조건부 인덱스 사용, 비트 필드 활용, 쿼리 최적화 등 다양한 방법으로 인덱스 성능을 개선할 수 있습니다.
