What
- 페이징이란?
✍🏻 페이징은 책 페이지처럼 데이터를 묶음으로 분리하는 과정
- 종류
- 오프셋 페이징
-
OffSet: 어디 부터 시작해서 가져올것인지? -
Limit: 몇개를 가져올 것인지?SELECT * FROM ${table_name} ORDER BY ${Column} **OFFSET 10 LIMIT 5** -
보통 offset 페이징은 프론트 엔드에서 이렇게 표현됩니다.
페이지 버튼과 함꼐 쓰이며 버튼을 클릭함으로써 페이지를 휙휙 넘길 수 있습니다.

-
- 오프셋 페이징
- 커서 페이징
-
Cursor - 사전적의미
사전적 의미 : 데이터베이스 커서는 일련의 데이터에 순차적으로 액세스할 때 검색 및 "현재 위치"를 포함하는 데이터 요소
DB 의미 : 특정 SQL 문장을 처리한 결과를 담고 있는 영역을 가리키는 일종의 포인터 입니다. -
실시간 데이터와 대량의 데이터(페이스북, 슬랙 , 트위터 등)을 다루는 웹사이트에서 쓰이는 페이징 방법으로써, 프론트에서 무한 스크롤(인스타 그램, 페이스북처럼 하단으로 계속 스크롤 되는 페이징 방식)을 지원

-
Why [왜 cursor 인가?]
✍🏻 실시간 데이터를 효율적으로 다룰수 있다는 점입니다.
왜냐하면 커서는 데이터를 정적으로 유지할 것을 필요로 하지 않기 때문입니다.
즉, 새로운 데이터가 추가되거나 제거될 수 있는 상황에서 사용자들에게, 그 데이터들은 정상적으로 조회될 수 있을 것입니다.
우수한 실시간 데이터 처리 능력
✍🏻 오프셋은 단순히 레코드를 조회하기 전에 데이터베이스가 건너 뛰는 레코드의 수다.
즉, 요청한 데이터를 바로 조회하는 것이 아니라, 이전의 데이터를 모두 조회하고 그 ResultSet에서 오프셋을 조건으로 잘라내는 것 입니다.
- 오프셋 쿼리 예시
SELECT *
FROM (
SELECT ROWNUM() over (ORDER BY timestamp) rnum
, A.*
FROM table A
ORDER BY timestamp
)
WHERE ROWNUM BETWEEN 6 AND 10-
timestamp를 정렬 기준으로 전체 데이터의 행번호를 출력하고 이 번호를 기준으로 잘라내는 것입니다.
-
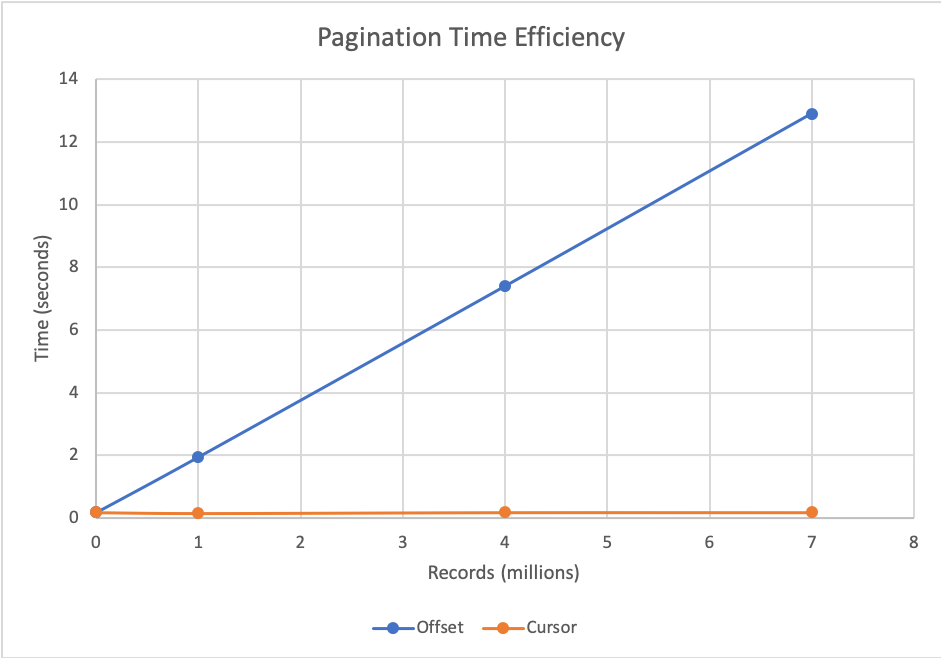
이건 오프셋 숫자가 커질수록 큰 문제가 됩니다. 다량의 데이터를 테스트 하는 부분에서 아주 큰 차이를 보입니다.
또 고려해봐야 할 것들
✍🏻
마지막 페이지를 이용할 확률은 얼마정도 될까?0%는 아니겠지만, 매우 작을 것이다.그렇지만 굳이 7백만개의 데이터가 아니더라도, 그래프에서 확인 할 수 있듯이 오프셋 페이징의 시간복잡성 O(N), O(offset+limit) 때문에 오프셋이 커질수록 시간이 증가해 UX는 감소합니다. 반면 커서 페이징의 경우는 O(1), O(limit)로 항상 일정합니다.
따라서 전보다 페이지 로딩이 느려진 것같은 느낌이 든적이 있다면, 아마도 그건 오프셋 페이징의 비효율성 때문입니다 ‼️
누락되지 않는 데이터 - 사용자의 기대 부응
-
Offset 페이징 예시 - sns에서 최근 피드 3개의 피드가 올라왔다.
**사용자에게 보여지는 페이지당 데이터 구성** ==== 1 페이지 ======= A B F ==== 2 페이지 ====== G H I ==== 3 페이지 ====== . . . sns에서 최근 피드 3개의 피드가 올라왔다. ==== 1 페이지 ======= A B C [new] ==== 2 페이지 ====== D [new] E [new] F ==== 3 페이지 ====== G H I -
해당 데이터의 새로운 삽입 으로 현재 보고 있는 2페이지에서 3페이지로 갈 떄 똑같은 데이터가 보이게 될 수 있다. 사용자는
?할 수 도 있습니다. -
삽입 외로 삭제가 이루어질 경우도 비슷합니다.
-
실제적으로 사용될 쿼리 예시
SELECT * FROM table ORDER BY timestamp OFFSET 0 LIMIT 3 SELECT * FROM table ORDER BY timestamp OFFSET 3 LIMIT 3 SELECT * FROM table ORDER BY timestamp OFFSET 6 LIMIT 3 SELECT * FROM table ORDER BY timestamp OFFSET 9 LIMIT 3 -
Cursor 페이징 예시 - sns에서 최근 피드 3개의 피드가 올라왔다.
**사용자에게 보여지는 페이지당 데이터 구성** ==== 1 페이지 ======= A B F ==== 2 페이지 ====== G H I ==== 3 페이지 ====== . . . sns에서 최근 피드 3개의 피드가 올라왔다. ==== 1 페이지 ======= A B F ==== 2 페이지 [다음 데이터 요청 가져옴] ====== G H I ==== 3 페이지[다음 데이터 요청 가져옴]====== . . . -
왜 삽입된 데이터들을 안불러올까?
-
오프셋은 매번 항상 데이터들을 모두 가져와서 선별을 하지만, 커서는 지정된 기준 이외에는 전체 데이터를 뒤적거리지 않고 특정 조건 이후에 있는 데이터들만 선별해서 가져옵니다.
‼️ SELECT * FROM table WHERE cursor > timestamp ORDER BY timestamp LIMIT 5
쿼리 결과에 대한 스코프
✍🏻 커서 페이징도 단점이 존재하므로 잘 고려해야한다.[신경쓸게 엄청 많다.]
제한된 정렬 기능
- Firstname과 Lastname을 기준으로 정렬한 테이블 하나를 가정 해봅니다.
- 이 경우는 커서 페이징에 구현에 문제를 발생시킨다. 왜냐하면 커서 페이징 정렬의 요구사항 중 하나는 정렬할 컬럼에 중복된 값이 존재하면 안되고,
순차적이어야 한다는 것 입니다. 커서 페이징을 사용하려면"**이 레코드** 다음 레코드를 조회해줘"라고 할 수 있는 특정 지점을 커서로 지정할 수 있어야 합니다.
이런 요구사항 때문에, 대부분의 커서 페이징은 timestamp 컬럼을 기준으로 한다. 왜냐하면 작은 단위의 timestamp는 순차적이고 고유하기 때문입니다.
Firstname은 순차적일 수는 있지만 고유하지는 않습니다. 우리는 김, 박, 최씨를 적어도 100명은 알고 있습니다. 그래서 이런 경우 커서는 고유한 레코드가 아닌 전체 레코드 집합을 가리킬 수도 있습니다. 따라서 커서를 구현한 방법에 따라 데이터를 건너 뛰거나 중복될 수 있습니다.
회원 테이블의 경우 정렬 기준으로 이메일이 더 좋을 수 있습니다. 고유하고 순차적 이라고 볼 수 있기 때문입니다.
그러나 요구사항이 Lastname 또는 Firstname으로 정렬하는 것이라면 커서 페이징이 적합하지 않을 수 있습니다. 이름과 성을 연결하거나 여러 열의 튜플을 사용하여 고유한 열을 만들 수 있지만 이로 인해 커서 페이징이 오프셋 페이징보다 훨씬 느려질 수도 있습니다. SQL문에서 연결 및 튜플 비교는 모두 시간복잡도 O(N), O(전체 데이터) 를 가지기 때문입니다.
-
커서를 잘못 쓰는 경우 포포몬쓰의 저하
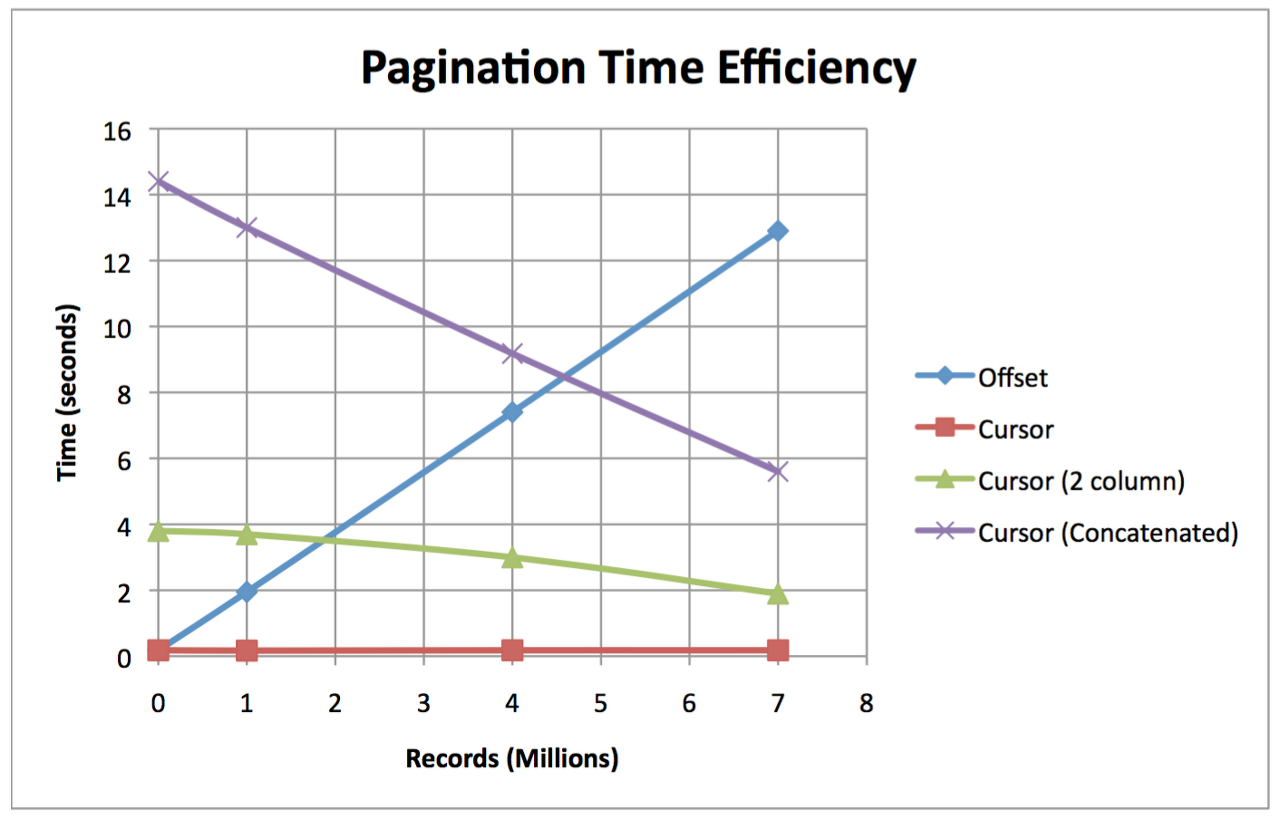
- 실제로, 커서 페이징이 오프셋 페이징보다 첫번째 페이지를 훨씬 느리게 조회했습니다. 직관적으로 이해되지 않을 수 있지만
Cursor(Concatenated)가 우하향 하는 이유는 레코드가 많아 질수록 SELECT 하는 레코드가 적기 때문입니다.
How
Offset
- 스프링 jpa에 제공하는 Pageable 객체 사용
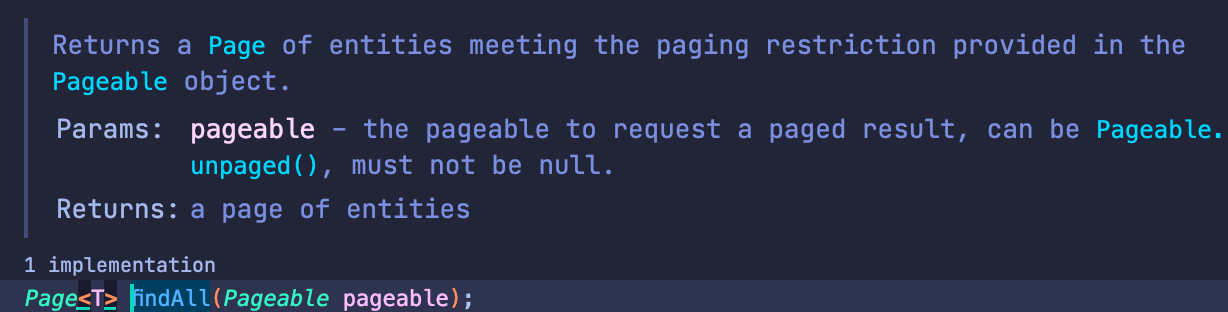
- Pageable 구현체에는 PageRequest라는 객체가 존재합니다.
-
해당 PageRequest는 해당 페이징에 필요로 하는 것들이 있습니다.
-
몇개씩 보여줄 것인지(
limit) 어디 페이지(offset은 아니지만 연관이 있음.)를 볼것인지?에 대한 정보가 필요합니다. -
클라이언트로 부터 사이즈와 페이지 정보를 받습니다.
-
PageRequest 객체를 생성합니다.
public static PageRequest of(int page, int size, Sort sort) { // 페이지는 0부터 시작한다! 사용자는 1,2,3 이지만 컴퓨터 세계는 0번째부터 존재함을 인지해야 한다. return new PageRequest(page, size, sort); }
-
Pageable 객체는 많은 편의 기능들을 제공합니다.
- 페이지 번호
- 전 페이지 존재 여부 등등…
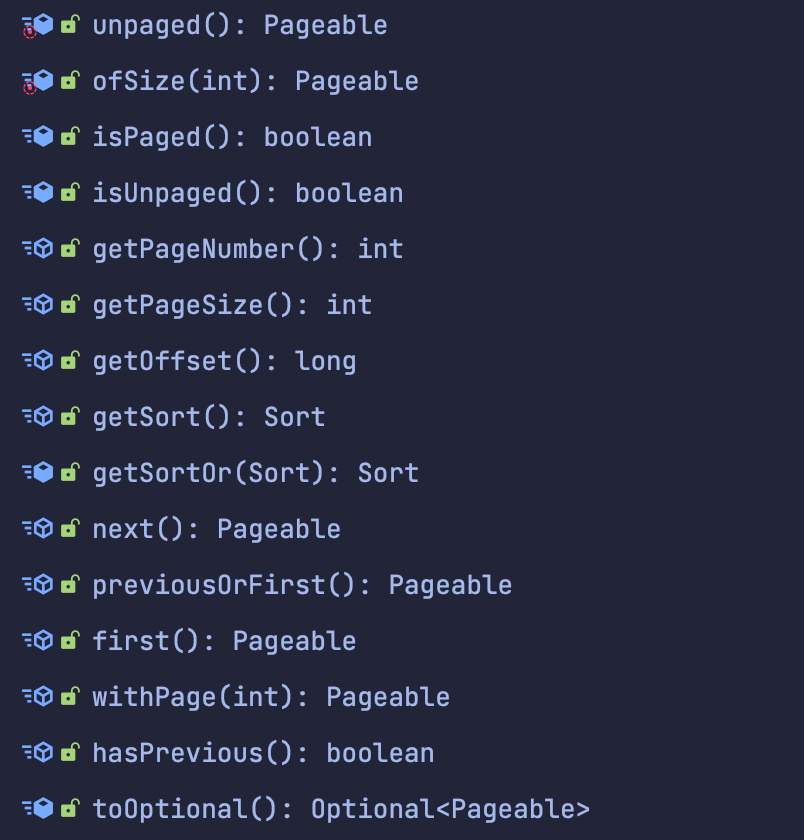
추가적으로 이것보다 UI에서는 현재 페이지들의 번호가 필요하니 따로 커스텀 해야합니다!
Cursor
- 페이지를 처음 진입했을 때는 별도의 페이징을 하지 않고 일정 개수만큼 조회합니다.
- 조회한 데이터 중 마지막 데이터의 커서값을 조회 데이터와 함께 프론트에 넘겨줍니다.
- 다음 데이터를 조회할 때에는 백엔드에게 커서 값과 함께 “이 커서 값 이후의 데이터를 N개 조회 해주세요" 라고 요청 보냅니다.
- 백엔드는 커서 값 이후의 데이터를 조회합니다.(Member를 id 역순으로 조회, 최근 커서가 id = 10일 경우)
- ex) SELECT m From Member m WHERE id < 10 ORDER BY id DESC LIMIT 6;
❗️ Cursor 방식 페이징 사용 시 주의점
- 데이터 유실에 주의 하세요 ‼️
중복이 발생하는 컬럼을 커서로 사용 시 데이터 손실이 발생할 수 있습니다.
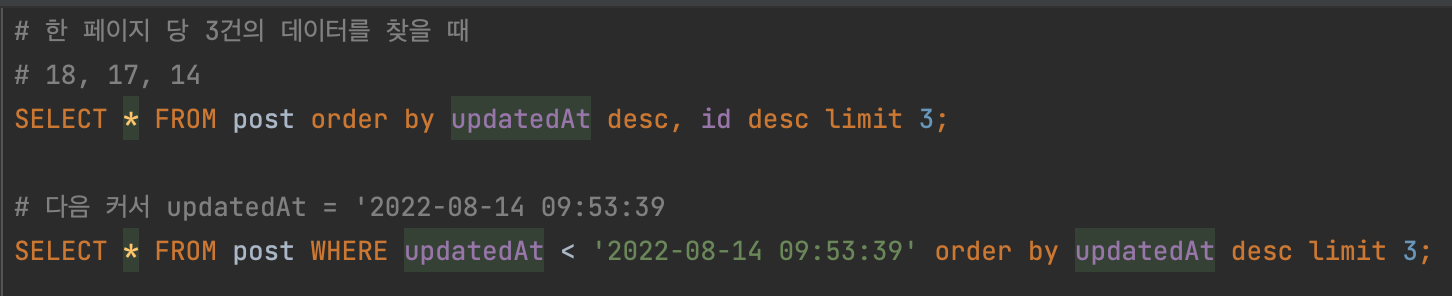
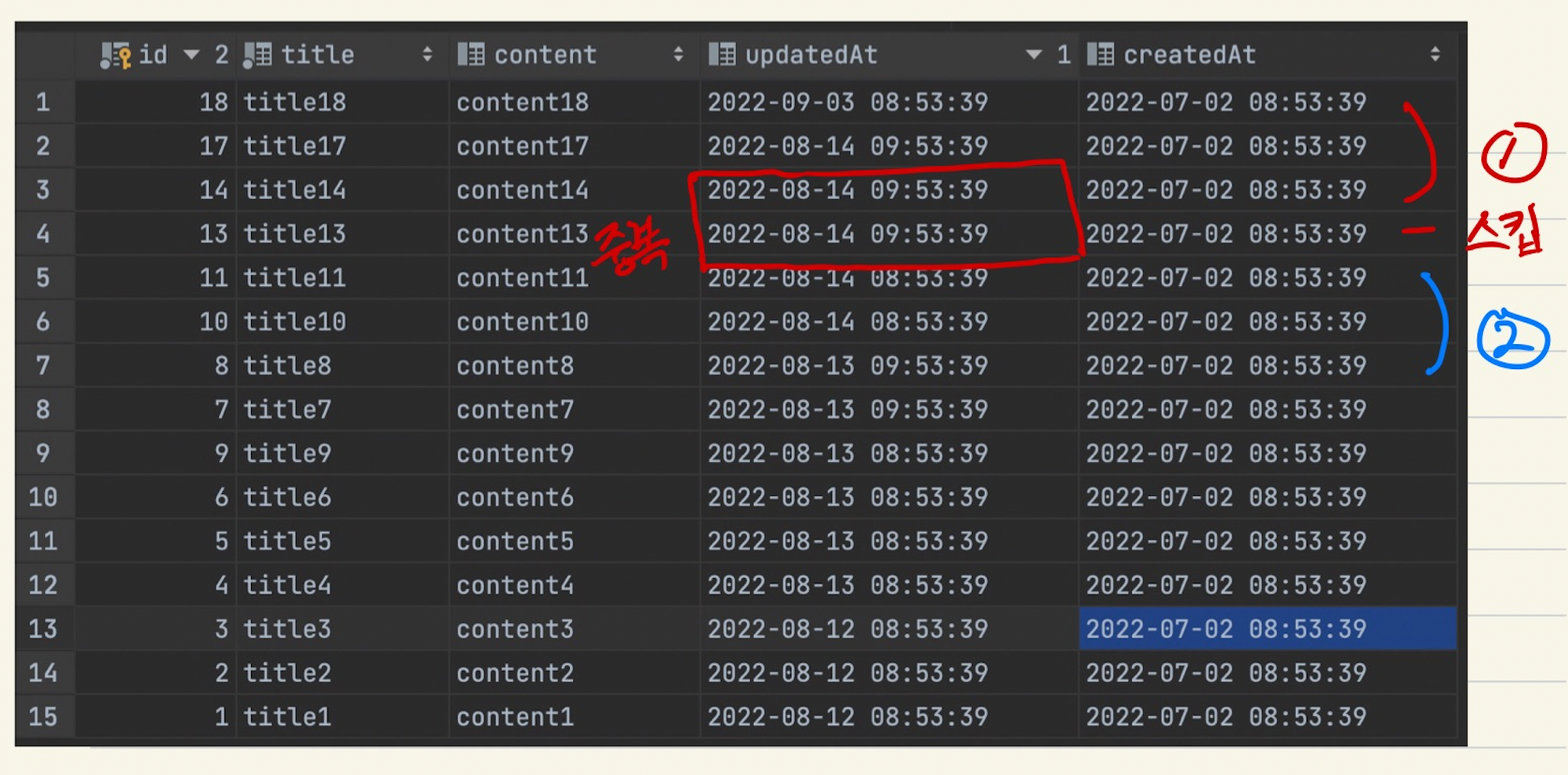
처음 id가 18, 17, 14인 데이터를 불러 왔고 커서 값은 ‘2022-08-14 09:53:39’ 가 됩니다.
이제 다음 페이지를 불러올 경우에는 ‘2022-08-14 09:53:39’ 보다 전 시간의 데이터를 불러올 겁니다.
하지만 id가 13인 데이터도 마찬가지로 updatedAt이 ‘2022-08-14 09:53:39’ 이므로 스킵하게 됩니다.
잘못된 페이징으로 데이터 유실이 발생한 것입니다. 이러한 문제를 해결하기 위해서는 중복되더라도 다른 컬럼과 함께 사용해 두번째 규칙을 정해야합니다.
다른 컬럼과 결합해 사용할 때에는 쿼리에 각별히 주의해야합니다. 컬럼을 두 개 이상 사용한다해도 쿼리가 정확하지 않는다면 올바른 페이징을 할 수 없습니다.
아래와 같이 수정일이 최신인 순으로 페이징해 출력하는 상황을 가정합니다. updatedAt이 같을 경우엔 중복되지 않는 값인 pk(id)를 역순으로 정렬 해 쿼리에 조건을 추가 합니다.
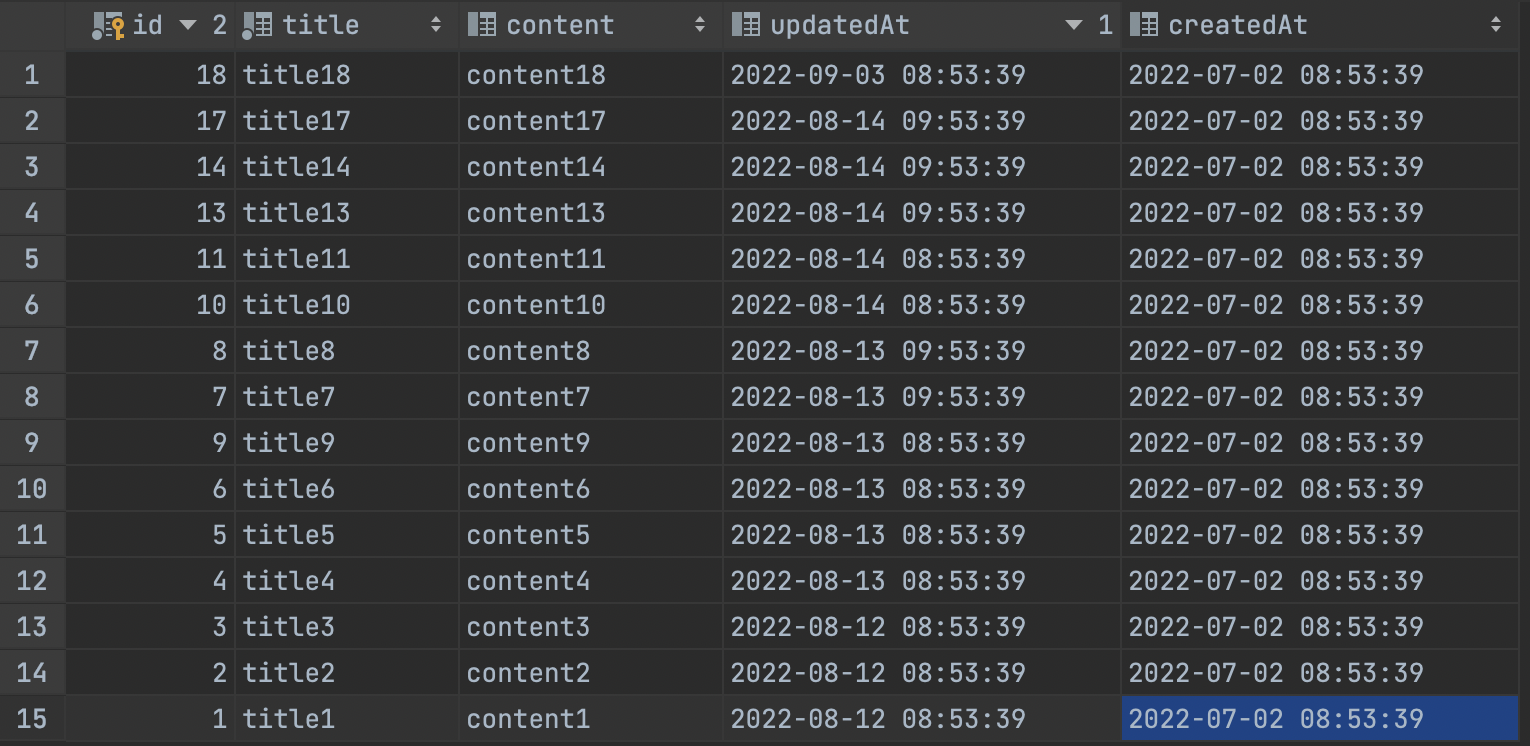
- 쿼리를 잘 짜야합니다! ‼️
3개씩 페이징 한다고 가정 했을 때, 제가 처음 작성했던 쿼리는 다음과 같습니다. 얼핏 봤을 때에는 문제 없이 페이징 되는 듯 해 보였습니다.
SELECT * FROM post WHERE id < ${cursorId} and updatedAt <= ${cursorUpdatedAt}
order by updatedAt desc, id desc limit 3;# 처음 데이터 3개 불러오기 (마지막 데이터 id = 14, updatedAt = 2022-08-14 09:53:39
SELECT * FROM post order by updatedAt desc, id desc limit 3;
# 다음 페이징
# cursor -> id = 14, updatedAt = 2022-08-14 09:53:39
# 13, 11, 10
SELECT * FROM post WHERE id < 14 and updatedAt <= '2022-08-14 09:53:39'
order by updatedAt desc, id desc limit 3;
# 다음 페이징
# cursor -> id = 10, updatedAt = 2022-08-14 08:53:39
# 8, 7, 9
SELECT * FROM post WHERE id < 10 and updatedAt <= '2022-08-14 08:53:39'
order by updatedAt desc, id desc limit 3;
⚠️ 하지만 이 쿼리에는 문제점이 있었습니다. id는 항상 내림차순이 아닙니다.
일부의 게시물을 Update 하는 상황을 가정해 보겠습니다.
여러 게시물들을 수정해 다음 순서와 같이 데이터가 배치된 경우를 예로 들겠습니다.
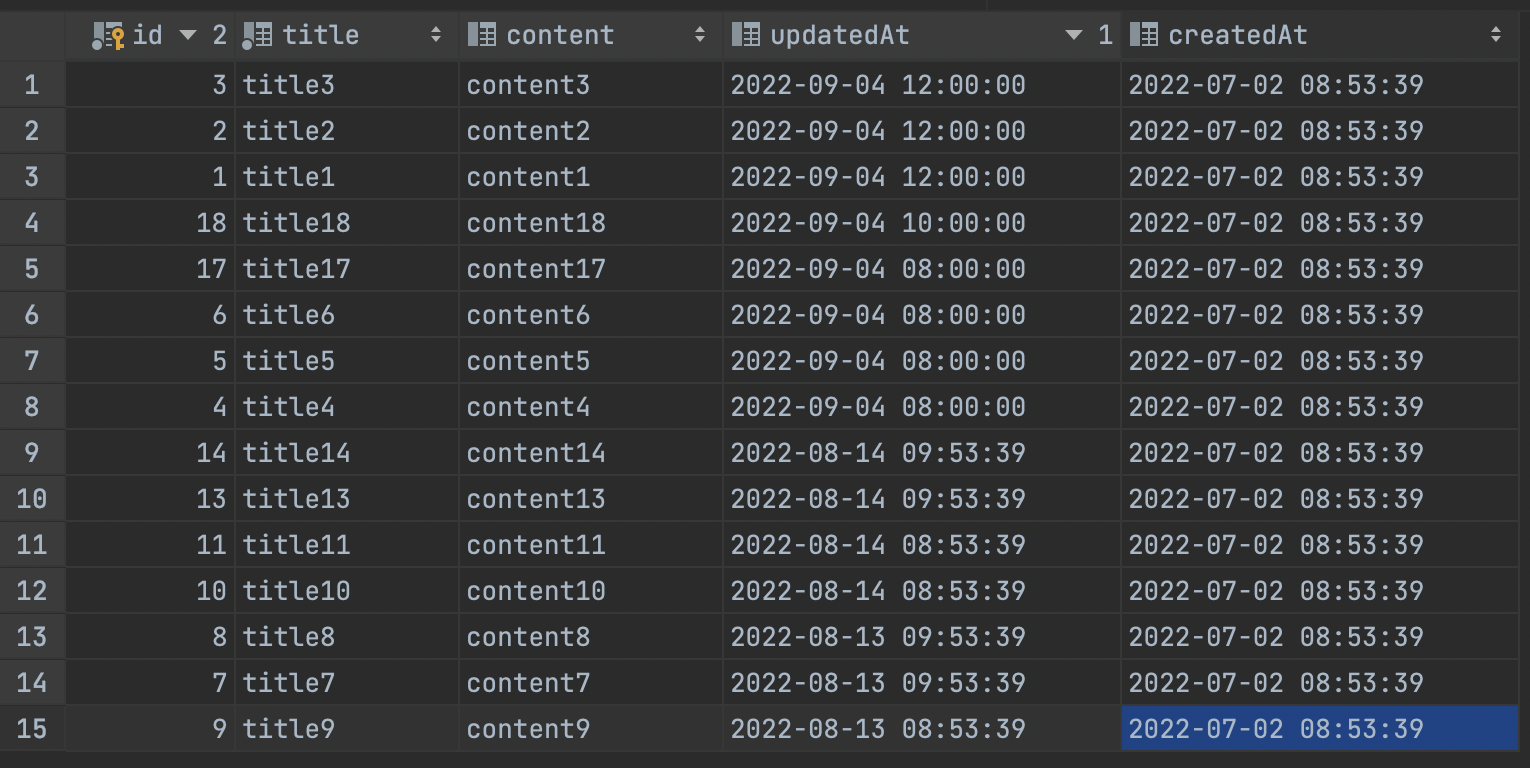
자세히 살펴보겠습니다.
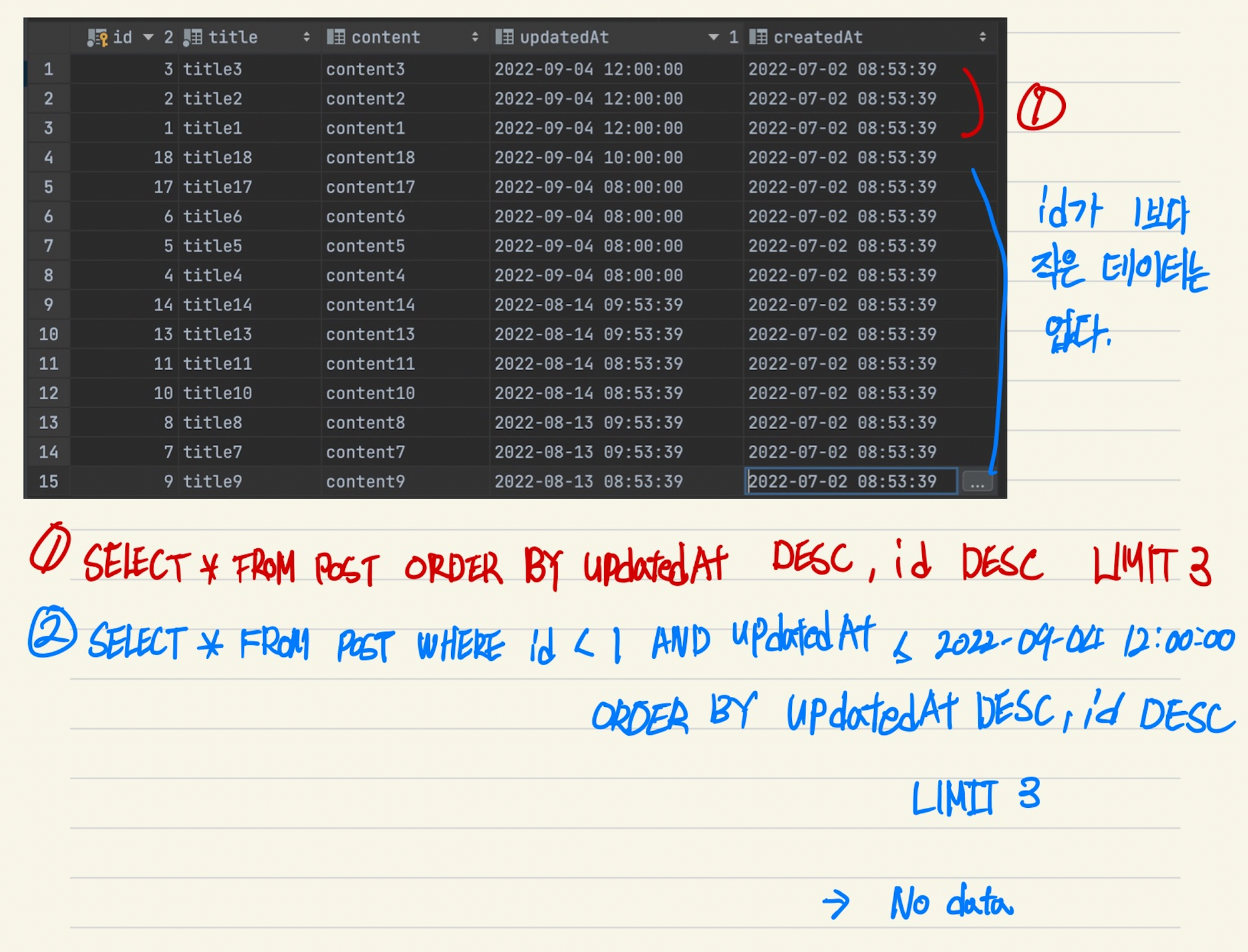
첫번째 페이징 후 커서는 updatedAt = 2022-09-04 12:00:00, id = 1을 가르킵니다. 다음 데이터를 불러올 때는 id가 1보다 작은 데이터가 없으므로 다른 데이터들을 조회할 수 없습니다.
기존 쿼리로는 다음 데이터를 불러올 수가 없습니다! 문제가 있어 보이죠? 쿼리는 다음과 같이 작성해야 합니다.
SELECT *
FROM post
WHERE updatedAt < ${cursorUpdatedAt}
or (id < ${cursorId} and updatedAt == ${cursorUpdatedAt}
ORDER BY updatedAt DESC, id DESC LIMIT 3;쿼리를 변경해서 다시 자세히 보겠습니다.

-
처음 3개의 데이터를 불러옵니다 cursor 는 id = 1, updatedAt = 2022-09-04 12:00:00 입니다.
-
그 다음은 updatedAt < 2022-09-04 12:00:00 조건으로 id가 18, 17, 6 … 인 값이 조회되고
2022-09-04 12:00:00:00과 중복되는 데이터가 없으므로 다음으로 넘어갑니다
이제 cursor는 id = 6, updatedAt = 2022-09-04 08:00:00입니다.
-
다음으로 updatedAt < 2022-09-04 08:00:00 조건으로 3-a 부분이 조회됩니다.
cursor updatedAt보다 작은 데이터들입니다.
id < 6 AND updatedAt = 2022-09-04 08:00:00 조건으로 3-b 부분이 조회됩니다.
cursor updatedAt과 같지만 id가 더 작은 것 들입니다.
중복 문제가 해결 되었습니다.
REFER
.jpg)