AE(오토인코더)
https://kr.mathworks.com/discovery/autoencoder.html
개념 설명
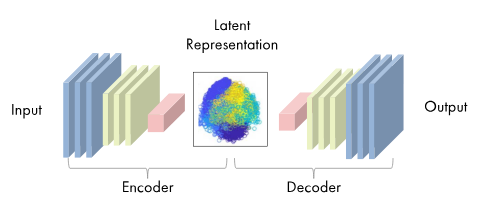
오토인코더는 생성형 딥러닝 모델 구조 중 하나로 인코더와 디코더로 이루어져 있다.
- 인코더: 이미지 같은 고차원 입력 데이터를 저차원 임베딩 벡터로 압축
- 디코더: 임베딩 벡터를 원본 도메인으로 압축 해제
- 잠재 공간: latent space 또는 임베딩 공간이라고 도 하며, 원본 데이터를 더 작은 차원의 정보 공간에 매핑하고 매핑된 임베딩을 바탕으로 원본 데이터를 재구성할 수 있음
VAE(변이형 오토인코더)
VAE의 구조
https://taeu.github.io/paper/deeplearning-paper-vae/
AE와의 차이점
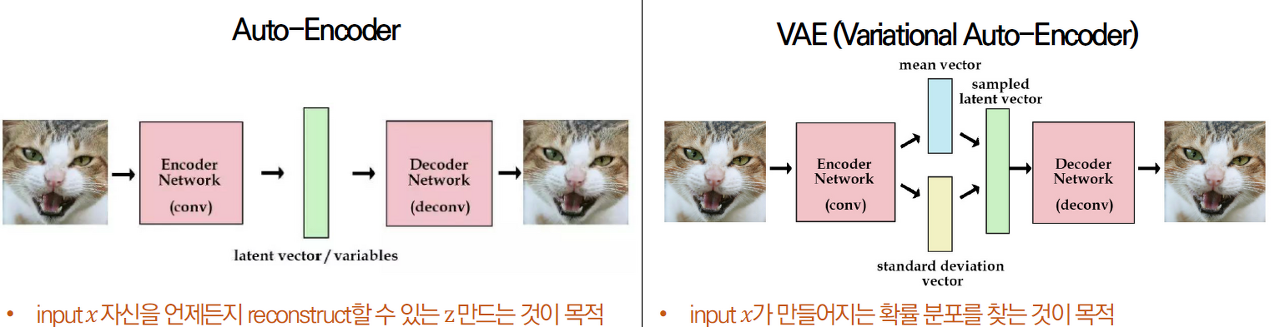
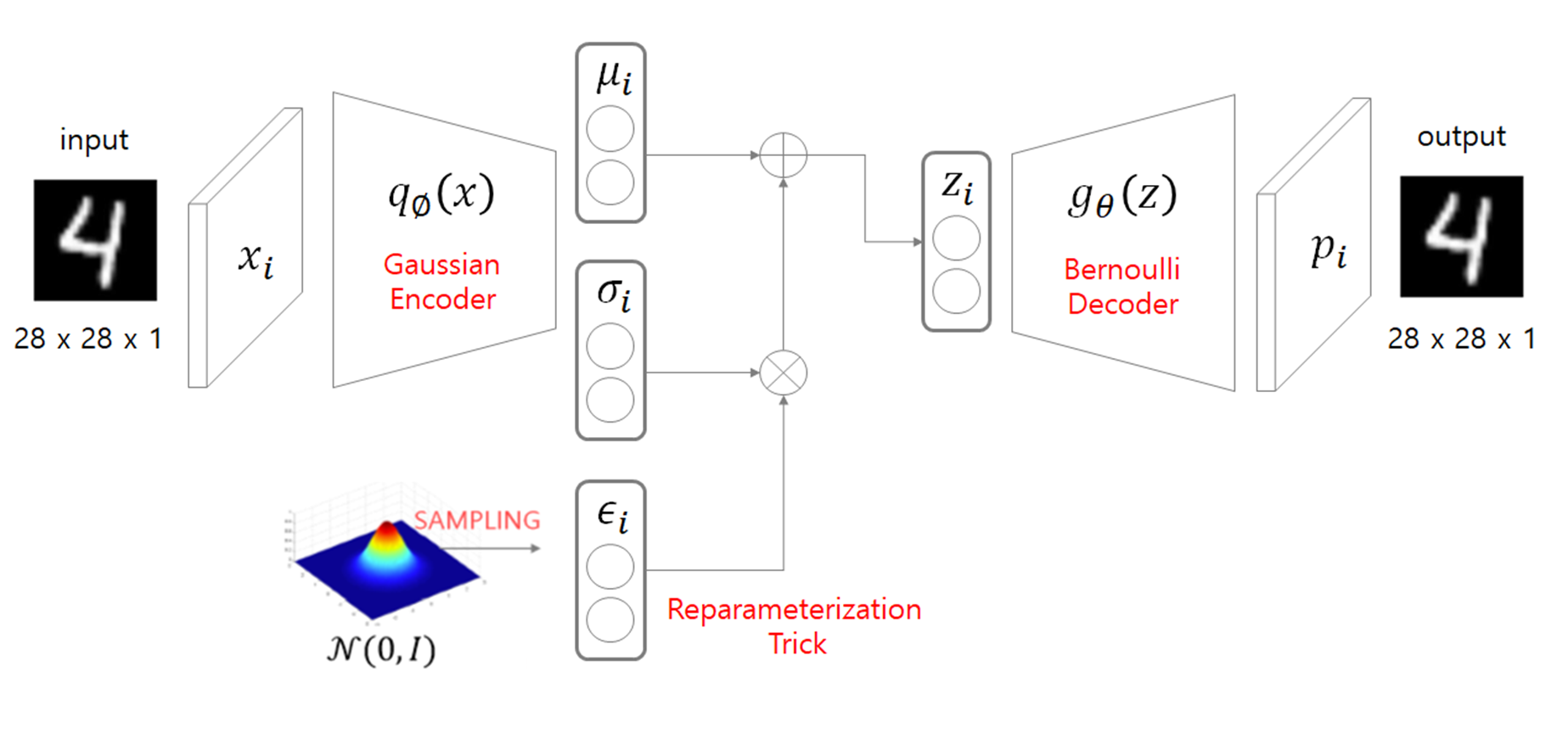
AE에서는 단순히 인코더 output인 임베딩 벡터를 임베딩 공간에 매핑하였지만
VAE의 경우 인코더 output으로 n개 차원의 평균과 표준편차를 반환 후
표준 정규 분포로 생성된 텐서에 표준편차를 곱하고 평균을 더하는 샘플링을 거치게 됨
위 과정을 reparameterization trick이라고 하며 인코더와 디코더를 나누어 학습하지 않고 한번에 학습을 할 수 있도록 함.
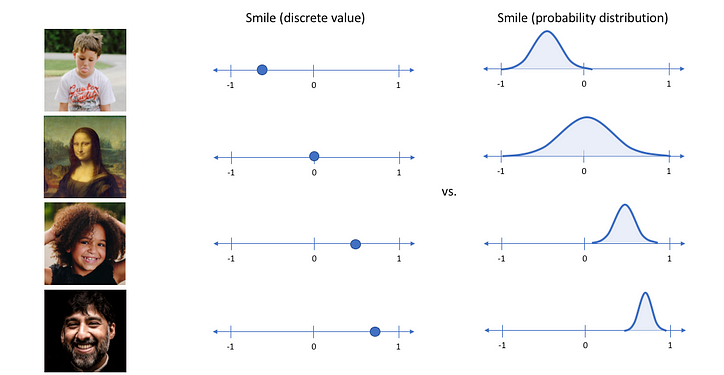
아래의 이미지의 왼쪽은 AE의 임베딩 벡터, 오른쪽은 VAE의 샘플링 분포이다.
Jeremy Jordan
임베딩 벡터는 특정 값으로 매핑이 되는 반면 샘플링 분포는 확률적으로 분포되어 있는 것을 확인할 수 있음
-> 이 말은 즉 정규분포를 따르기 때문에 같은 input에 대해 비교적 비슷한 데이터가 생성되지만 항상 무작위의 데이터가 생성된다는 내용이다.
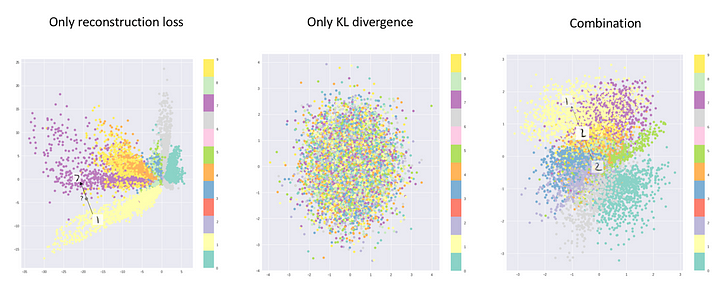
왼쪽 그림은 일반적인 AE의 latent space를 시각화한 이미지이다.
가운데 그림은 KL-Divergence만을 Loss 함수로 사용하여 학습을 진행한 VAE의 latent space를 시각화한 이미지이다.
오른쪽 그림은 앞서 설명한 두 가지 loss 함수를 모두 사용한 일반적인 VAE latent space이다.
이를 통해 일반적인 VAE의 경우 AE와 다르게 임베딩이 적절히 정규화되어 원하는 output을 적절하게 생성할 수 있는 디코더를 학습할 수 있는 것을 알 수 있다.
VAE를 이용한 데이터 증강 원리
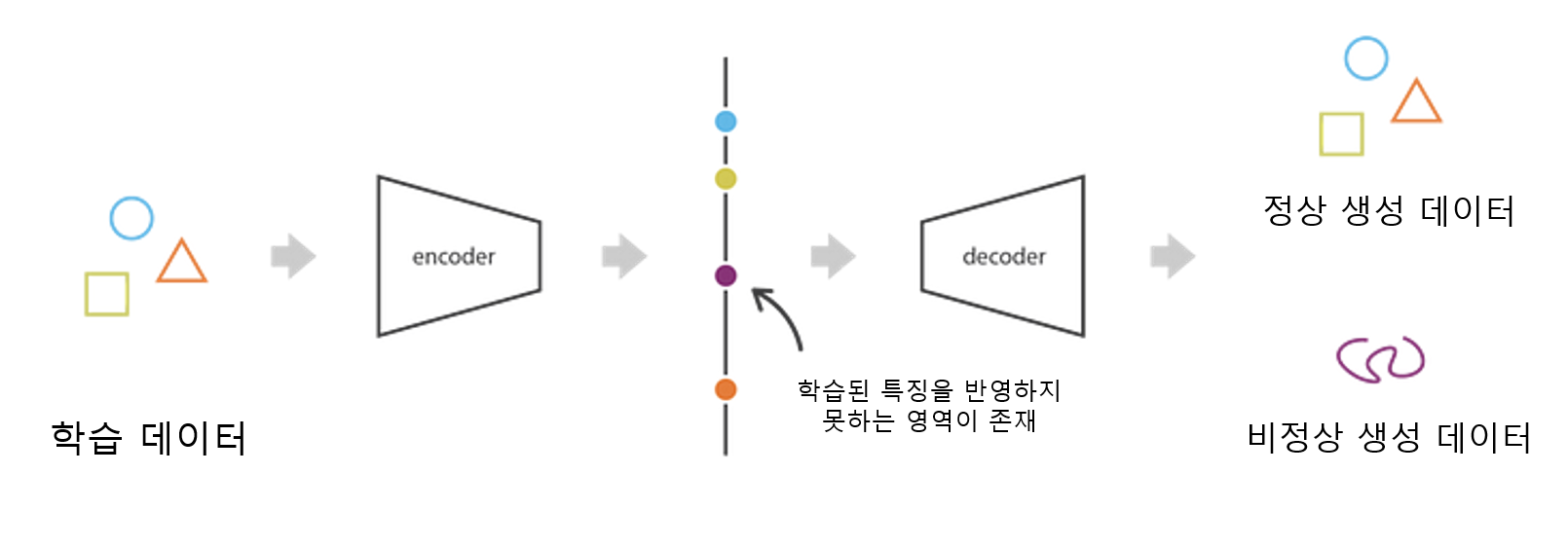
AE의 문제점에 대한 설명
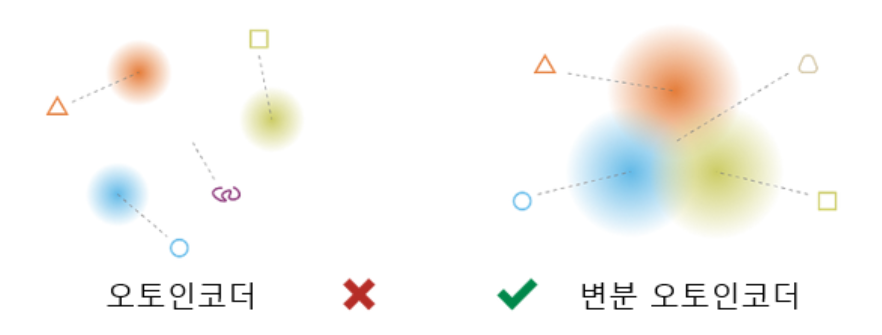
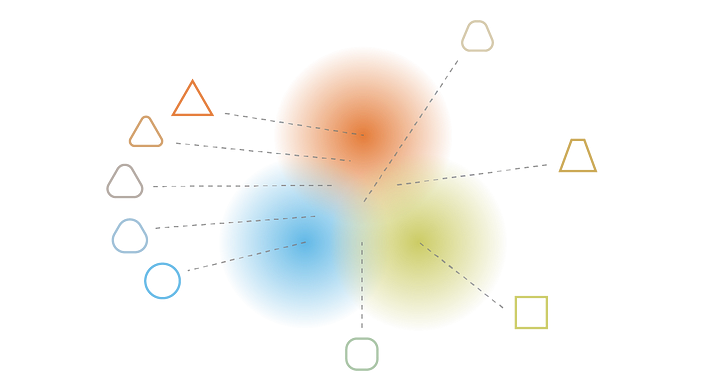
https://ichi.pro/ko/vae-variational-auto-encoder-leul-sayonghan-saengseong-modelling-277371603749134
AE의 경우 1번 이미지와 2번 이미지의 왼쪽 그림을 통해 확인할 수 있듯이 잠재 공간(latent space)에 정규화하여 매핑되지 않아 각 특징 데이터들이 적절하게 섞인 데이터를 생성할 수가 없음을 알 수 있다.
VAE의 경우 2번 이미지의 오른쪽 그림과 3번 이미지에서 확인할 수 있듯이 각 특징 데이터들이 잠재 공간(latent space)에 정규화하여 매핑되어 여러 특성이 적절히 결합된 데이터를 생성할 수 있게 된 것을 확인할 수 있다.
위 차이를 통해 AE는 실제 데이터와 유사하면서 다양한 데이터를 생성하기 어려운 점을 알 수 있고 VAE를 이용해 데이터를 생성할 때, 실제 데이터에는 존재하지 않지만 유사한 데이터를 생성할 수 있음을 알 수 있다.
증강 데이터 성능 평가 방법
- 피어슨 상관계수를 이용한 방법

봉현수, 오민식, 유전자 발현량 데이터 증대를 위한 Conditional VAE 기반 생성모델, 방송공학회논문지 제28권 제3호, 2023년 5월 (JBE Vol.28, No.3, May 2023) - UMAP을 이용한 다차원 데이터 시각화

UMAP은 Uniform Manifold Approximation and Projection의 약자로 다차원 공간의 데이터를 그래프 형식으로 변환한 뒤, 더 작은 차원으로 projection하여 시각화가 가능하다.
UMAP 이외에도 t-SNE, PCA 등으로도 시각화가 가능하지만, UMAP이 다차원 데이터를 압축하는데 제일 효과적인 것으로 알려져 있다.
GAN(생산적 적대 신경망)
개념 설명
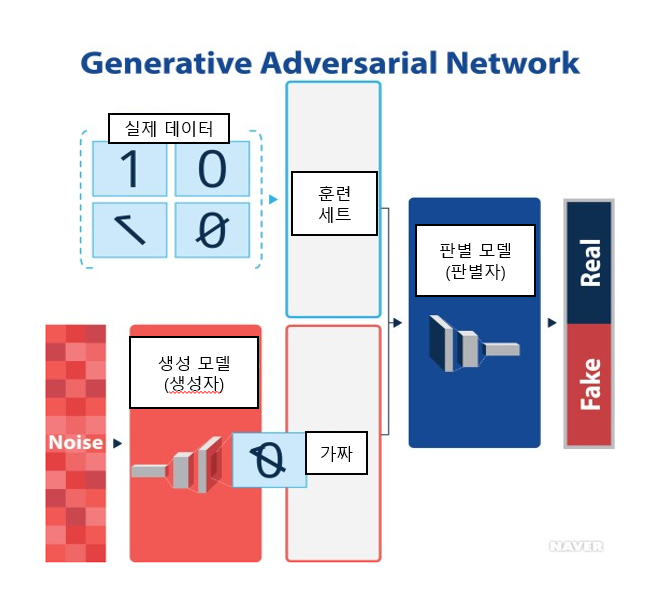
https://terms.naver.com/entry.naver?docId=5917559&cid=66682&categoryId=66682
학습 데이터에 대한 라벨이 필요하지 않은 비지도 학습 모델
생성 모델과 판별 모델이 서로 경쟁하며 데이터를 생성 및 판별하는 모델을 의미한다. 궁극적으로는 생성 모델과 판별 모델의 성능이 지속적으로 향상되다가 판별 모델이 더 이상 실제 데이터와 생성 데이터를 구분할 수 없는 상태가 되면 학습을 종료한다.
이렇게 학습된 생성 모델은 실제 데이터의 분포에 가까운 데이터를 생성하게 된다.
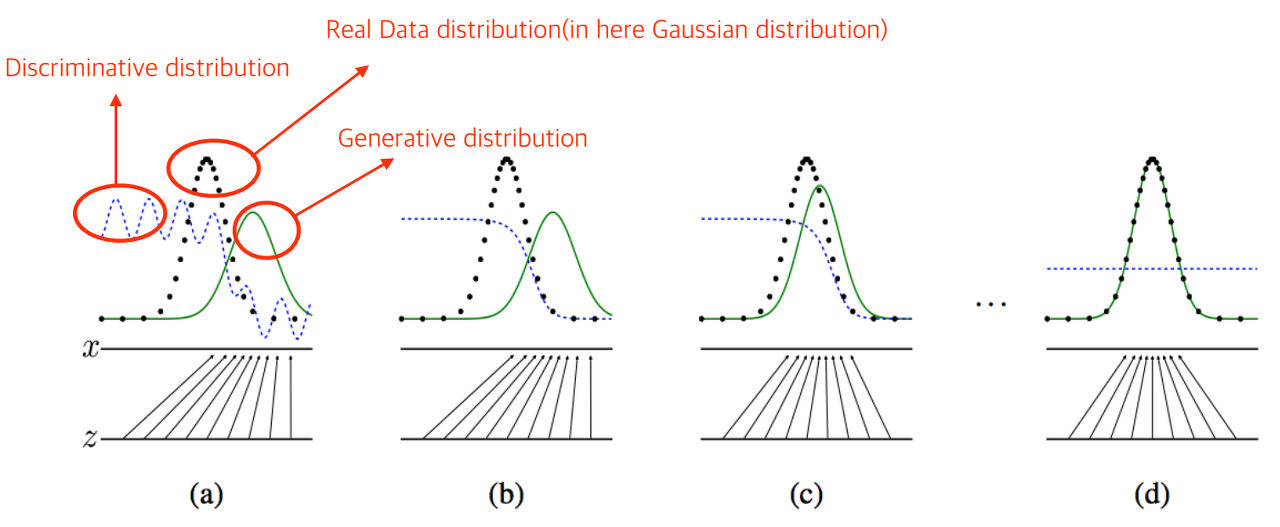
- KLD(Kullback-Leibler Divergence)
KLD는 두 확률 분포 간의 차이를 측정하는 지표. GAN에서는 주로 생성된 분포와 실제 데이터 분포 간의 차이를 최소화하는 데 활용됨. - JSD(Jessen-Shannon Divergence)
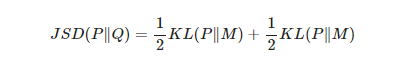
KLD의 문제는 비대칭적이라는 것. KL(P|Q)KL(P|Q)와 KL(Q|P)KL(Q|P)의 값이 서로 다르기 때문에 이를 “거리”라는 척도로 사용하기에는 애매한 부분이 존재하며 JSD는 이러한 문제를 해결할 수 있는 방법
VAE와 GAN의 차이점
GAN (Generative Adversarial Network):
장점:
- 뛰어난 생성 능력: GAN은 매우 실제와 유사한 이미지를 생성하는 데 강점이 있습니다. 생성자와 감별자의 경쟁을 통해 고품질의 합성 데이터를 만들 수 있습니다.
- 높은 차원의 데이터 생성 가능: GAN은 고해상도 및 복잡한 데이터를 생성하는 데 효과적입니다. 예를 들어, 고해상도의 이미지나 다양한 종류의 데이터를 생성하는 데 적합합니다.
단점:
- 모드 붕괴(Mode Collapse): GAN은 때때로 특정한 이미지나 패턴만을 생성하는 모드 붕괴 현상이 발생할 수 있습니다.
- 훈련의 불안정성: GAN은 훈련이 어려운 경향이 있어 적절한 하이퍼파라미터 튜닝과 안정적인 훈련이 필요합니다.
VAE (Variational Autoencoder):
장점:
- 확률적 잠재 변수: VAE는 확률적 잠재 변수를 사용하여 데이터의 다양한 특성을 잘 캡처할 수 있습니다.
- 재구성 오차 최소화: VAE는 잠재 변수의 확률 분포를 학습하며, 재구성 손실을 최소화하여 다양한 데이터를 생성하는 데 중점을 둡니다.
- 훈련의 상대적인 안정성: GAN에 비해 훈련이 상대적으로 안정적이며, 모드 붕괴와 같은 문제가 적게 발생할 수 있습니다.
단점:
- 생성 능력의 한계: GAN에 비해 VAE의 생성 능력은 낮을 수 있습니다. 더 일반적인 특성을 갖는 이미지를 생성하는 데 한계가 있을 수 있습니다.
- 낮은 해상도: 고해상도 이미지나 복잡한 데이터에 대한 생성 능력이 GAN보다 낮을 수 있습니다.
