Paper Link: https://arxiv.org/abs/2210.03347
Github: https://github.com/google-research/pix2struct
Abstract
- 이전 연구와는 다르게 순수하게 이미지에 포함된 언어를 인식하는 문제를 해결하고자 한다.
- Pix2Struct는 웹페이지 스크린샷을 단순화한 HTML로 파싱하는 것을 학습해서 pre-train 모델을 생성했다.
- OCR(optical character recognition), 언어 모델링, 이미지 캡션 등을 포함
- pretrained model은 9개 작업 중 6개 부문(documetns, illustrations, user interfaces, and natural iamges)에서 sota를 달성
downstream task: 최종적으로 해결하고자 하는 작업, 일반적으로 pre-train 이후에 특정 목적으로 추가적인 분류 및 예측 모델을 학습하는 것을 의미
https://chan-lab.tistory.com/31
1 Introduction
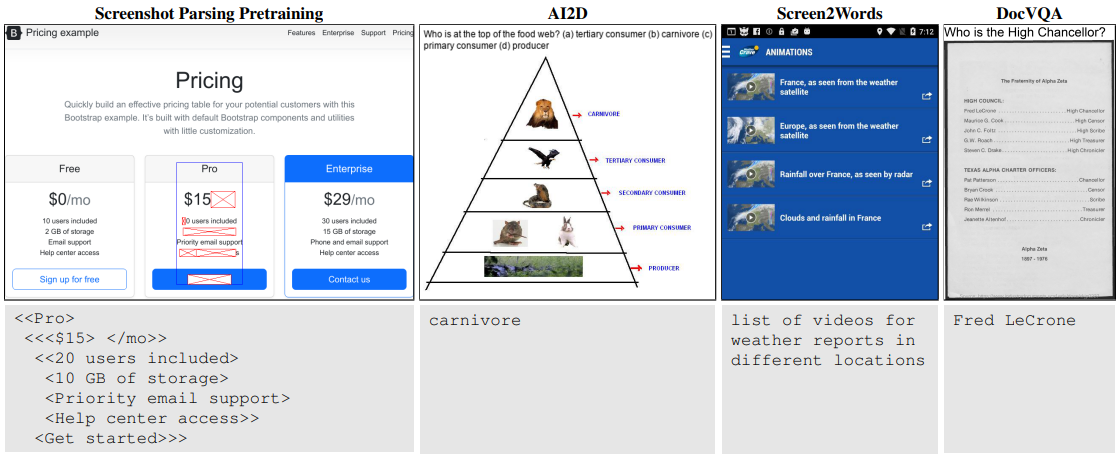
- 이전의 특정 도메인을 타겟으로한 시각-언어 이해 모델과 다르게 다양하고 보편적인 상황에서 사용할 수 있는 모델을 소개
- 웹 HTML 데이터를 기반으로한 스크린샷 파싱 모델을 제안
- 가변 입력 크기의 Vision Transformer와 언어와 비전 입력을 매끄럽게 통합하는 fine-tuning 기법을 소개
2 Method
2.1 Architecture
-
Pix2Struct는 Vision Transformer(ViT)기반의 이미지 인코더, 텍스트 디코더임
-
기존 ViT는 입력 이미지를 고정 크기 해상도로 변형하기 때문에 종횡비 왜곡 및 다운 스트림 작업 시 고해상도 전이 학습에 어려움이 있을 수 있음

-
따라서 Pix2Struct는 입력 이미지의 최대 patch 수를 추출할 수 있도록 확대 축소를 수행
-
해상도 변화에 대한 대처로 input patch에 대한 2차원 위치 임베딩을 사용
2.2 Pretraining
사전 학습 목표
입력 이미지의 의미적 구조를 나타낼 수 있도록 하는 것
- 웹 페이지의 스크린샷 + HTML 소스 수집
- HTML DOM 트리를 압축하고, 가장 큰 트리에 맞추어 시퀀스 길이를 효율적으로 조절할 수 있음
- BART와 유사하게 텍스트의 50%를 마스킹함으로써 학습에 이용함

- C++과 같은 파싱되지 않은 텍스트 이미지를 텍스트로 복원하는 것은 OCR과 유사
- Python, Java와 같이 파싱된 텍스트를 복원하는 것은 masked Language 모델과 유사
2.3 Warming Up with a Reading Curriculum
Curriculum Learning
딥러닝 및 머신러닝 모델을 학습 시, 볼륨이 큰 데이터의 경우 일반적으로 데이터를 배치 단위로 나누어서 입력된다. 하지만 이 때 데이터의 학습 순서는 고려하지 않고 무작위 순서로 입력된다. Curriculum Learning은 인간이 학습하는 프로세스를 모방하여 쉬운 난이도의 데이터를 먼저 학습하고, 점차 어려운 데이터를 학습하는 학습 전략을 채택하여 모델의 학습 수렴 속도와 성능에서 성과를 보이는 연구 분야이다.

Pix2Struct에서는 모델이 단순히 읽는 것을 학습하는 warmup을 이용해 (1)pretrain이 더 안정적이고 빠르게 수렴 (2)더 나은 finetuning의 2가지 효과를 얻을 수 있었음
2.4 Finetuning
| Dataset | Domain | Description |
|---|---|---|
| OCR-VQA | Illustrations | 책 표지의 VQA |
| ChartQA | Illustrations | 차트(테이블 데이터의 시각화)의 VQA |
| AI2D | Illustrations | 과학 도표의 VQA |
| RefExp | UIs | 자연어 질의에 일치하는 UI 구성 요소 감지 |
| Widget Captioning | UIs | 화면에 있는 UI 구성 요소 캡셔닝 |
| Screen2Words | UIs | 기능을 설명하는 UI 화면 캡셔닝 |
| TextCaps | Natural images | 텍스트가 포함된 자연 이미지 캡셔닝 |
| DocVQA | Documents | 스캔된 문서의 VQA |
| InfographicsVQA | Documents | 고해상도 인포그래픽의 VQA |
위 표에 있는 데이터셋을 전처리해서 도메인에 해당하는 기능을 수행하도록 학습
VQA(Visual Question Answering)
OCR-VQA, ChartQA, DocVQA, InfographicsVQA와 같은 VQA 형식의 경우 Question을 input Image의 상단에 헤더로 렌더링해서 Question과 Image를 한번에 읽어낼 수 있도록 전처리하였음.
3 Experimental Setup
3.1 Benchmarks
(a) DocVQA 및 InfographicVQA의 평균 정규화 Levenshtein 유사도 (ANLS)
(b) AI2D, RefExp 및 OCR-VQA의 정확도 (EM)
(c) ChartQA의 완화된 정확도(RA)
(d) 생성 작업에 대한 CIDEr
3.2 Implementation and Baselines
pretraining
Base Model과 Large Model 두 가지 종류의 모델을 학습
- Base Model: transformer 12개, 282M개의 파라미터
- Large Model: transformer 18개, 1.3B개의 파라미터
Warmup
BooksCorpus (Zhu et al., 2015)렌더링 텍스트를 이용, 최대 입력 시퀀스: 128패치
Base Model Pretrain
- batch size: 3072
- step: 270k
- input size: 1024 patches
- optimizer: Adafactor
Large Model Pretrain
- batch size: 1024
- step: 170k
- input size: 1024 patches
- optimizer: Adafactor
cosine decay from 0.01 to 0
4 Results
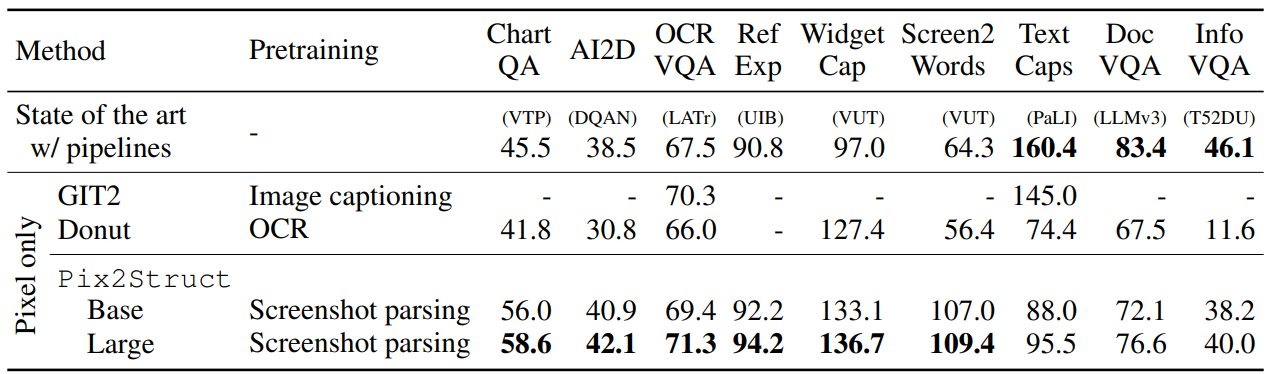
기존 Sota 대비 ChartQA, AI2D, OCRVQA, RefExp, WidgetCap, Screen2Words와 같은 도메인에서 성능 향상을 확인할 수 있다.
Referenced: http://dmqm.korea.ac.kr/activity/seminar/338
