python 모듈의 시작 지점
.py 확장자를 가진 파일을 실행하게 되면 기본적으로 name 값을 파일 명으로 가지게 된다. 그리고 시작 파일(main)만 디폴트로 main이라는 값을 가지게 되는데 이것으로 코드 상에서 현재 경로가 시작 지점인지 아닌 지를 판단할 수 있다.
if __name__ = "__main__":
...위와 같은 조건식을 통해 검사하는 것이 일반적인 관례인 것으로 보인다. 이렇게 검사를 하게 되면 현재 파일을 직접 실행한 경우에만(import한 경우를 배제할 수 있음) 조건문 아래의 코드들이 실행된다.
Referenced: https://dojang.io/mod/page/view.php?id=2448
XPath를 이용해 HTML에서 특정 element 찾기
XPath란?
W3C의 표준으로 XML(Extensible Markup Language)문서의 구조를 통해 경로(Path)위에 지정한 구문을 사용하여 항목을 배치하고 처리하는 방법을 기술하는 언어입니다. XML 표현보다 더 쉽고 약어로 되어 있으며, XSL변환(XSLT)과 XML지시자 언어(XPointer)에 쓰이는 언어로 XML 문서의 Node를 정의하기 위하여 경로식(Path Expression)을 사용하며, 수학 함수와 기타 확장 가능한 표현들이 있습니다.
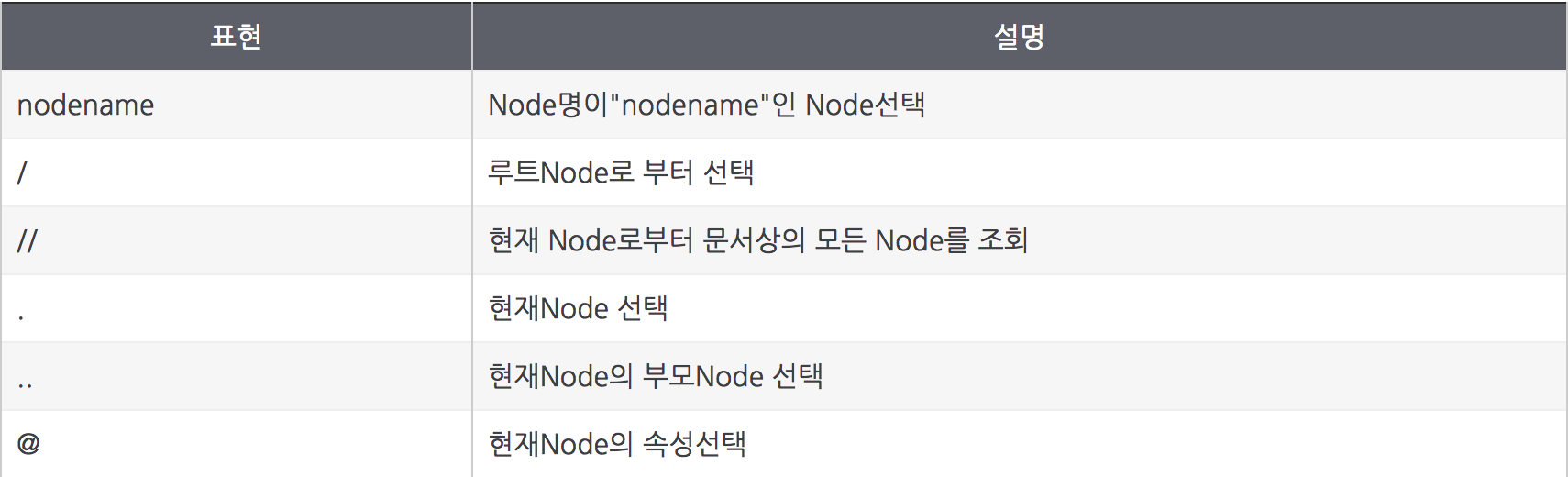
웹 크롤링에서는 HTML 상에서 필요한 정보를 간단한 경로식을 통해 간편하게 가져오기 위해 사용된다.
Chrome 개발자 모드에서 필요한 element를 우클릭하면 간단하게 해당 element의 XPath를 가져올 수 있기 때문에
small_category_div = small_category_dom.xpath('//div[@id="container"]/div[1]/div[5]/div/div/div/div')위 코드와 같이 xpath를 이용할 수 있는 함수가 있으면 가져온 XPath를 붙여 넣어 간편하게 사용할 수 있다.
Referenced: https://www.fun-coding.org/crawl_advance5.html, https://wkdtjsgur100.github.io/selenium-xpath/
