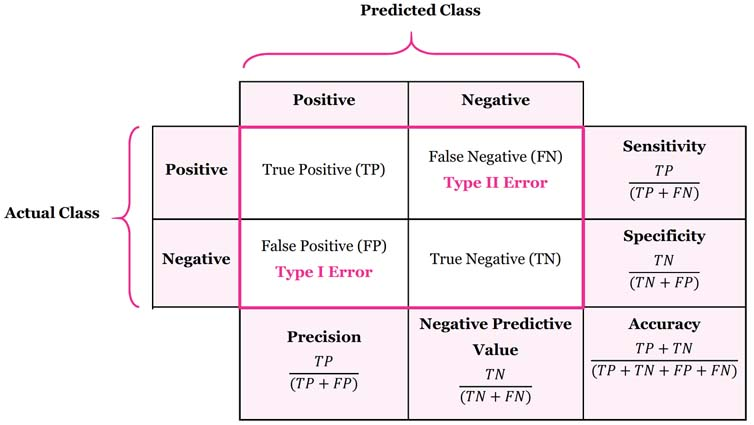
Confusion Matrix
True Positive: 실제로 양성인 것을 양성으로 판단한 것
False Negative: 실제로 양성인 것을 음성으로 잘못 판단한 것(모델이 찾아내지 못함)
False Positive: 실제로 음성인 것을 양성으로 잘못 판단한 것(모델이 이상한 것을 찾아냄)
True Negative: 실제로 음성인 것을 음성으로 판단한 것
torch.eval()과 torch.no_grad()의 사용
1. model.eval()는 Dropout, Batchnorm등의 기능을 비활성화 시켜 추론 모드로 조정해 주는 역할을 수행 (메모리와는 관련 없음)
2. torch.no_grad()는 autograd engine을 비활성화 시켜 필요한 메모리를 줄어주고 연산속도를 증가시키는 역할
3. torch.no_grad()함수가 model.eval() 함수처럼 dropout을 비활성화 시키진 않음
4. Inference중에 memory leak이 발생하면 해결책으로 torch.no_grad()함수를 추가할 수 있음
Referenced: https://yuevelyne.tistory.com/10
IoU(Intersection over Union) 구하기
IOU는 Computer Vision 분야에서 객체 검출이 정상적으로 되었는지 확인하는 용도로 사용된다.
일반적으로 IOU가 50%이상인 경우 객체를 그래도 정상적으로 검출했다고 보고 있으며 높은 정확도가 요구될 경우 이 보다 높은 IOU 수치를 필요로 할 수 있다.

def getIOU(box1, box2):
# box = (x1, y1, x2, y2)
box1_area = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
box2_area = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# obtain x1, y1, x2, y2 of the intersection
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# compute the width and height of the intersection
w = max(0, x2 - x1 + 1)
h = max(0, y2 - y1 + 1)
inter = w * h
iou = inter / (box1_area + box2_area - inter)
return ioux1, y1이 항상 x2, y2보다 왼쪽에 있으므로 x1 \< x2, y1 \< y2가 성립함을 알 수 있다.
따라서 각 box에 대해 (x1, y1)의 최댓값, (x2, y2)최솟값을 구하게 되면 항상 fold rect의 좌표를 구할 수 있게 된다.
Referenced: https://minimin2.tistory.com/144
OpenCV imread() 한글 오류
opencv에서는 기본적으로 영어 이외의 언어를 지원하지 않는 것으로 보인다. 아래의 코드와 같이 경로에 한글이 있거나 한글 이름의 파일을 읽으려고 하면 바로 오류가 발생한다. 또한 imshow()를 할 때, 윈도우 이름을 한글 명으로 할 때는 제대로 이미지를 표시하지 못하는 버그가 존재한다.
import cv2
image = cv2.imread('./한글.jpg', cv2.IMREAD_UNCHANGED)
cv2.imshow('한글', image)
cv2.waitKey()한글 경로 오류 발생 Traceback
Traceback (most recent call last):
File "c:\Users\USER\VSCworkspace\pyqt5\test.py", line 4, in \<module>
cv2.imshow('한글', image)
cv2.error: OpenCV(4.5.1) ..\modules\highgui\src\window.cpp:376: error: (-215:Assertion failed) size.width>0 && size.height>0 in function 'cv::imshow'
하지만 아래의 코드처럼 한글을 사용하지 않으면 오류 없이 이미지를 read할 수 있다.
import cv2
image = cv2.imread('./hangul.jpg', cv2.IMREAD_UNCHANGED)
cv2.imshow('hangul', image)
cv2.waitKey()OpenCV 사각형 그리기
opencv에서는 retangle() 함수를 이용해서 이미지에 원하는 색깔의 박스를 만들 수 있다.
이는 머신러닝 시각화에서 자주 사용되며 객체 탐지 시 해당 객체의 letf_top, right_bottom 좌표를 이용해 간단하게 이미지에 그려 넣을 수 있다.
색깔, 선 굵기, 선 타입을 매개 변수로 전달할 수 있는데, 색깔은 (255, 255, 255)와 같이 RGB 색상의 수치를 전달해주면 되고 굵기는 int형으로 줄 수 있다. 마지막으로 선 타입을 설정할 수 있는데 cv2.LINE_4, cv2.LINE_8, cv2.LINE_AA와 같은 값을 전달해 주면 된다. 여기서 타입이란 곡선을 표현하는데 선 굵기에 따라서 경계선을 세밀하게 묘사할 것인지 투박하게 묘사할 것 인지를 나타낸다. AA는 가장 세밀한 Anti Alias를 의미하고 4, 8은 Alias의 정도를 의미하는 것 같다.
def drawBBox(self, image, person_list):
for person in person_list:
cv2.rectangle(image, (person['box'][0], person['box'][1]), (person['box'][2], person['box'][3]), ACTUAL_COLOR, 2, cv2.LINE_AA)
return cv2.cvtColor(image, cv2.COLOR_BGR2RGB)그런데 이제 중요한 점은 image를 return할 때에는 반드시 OpenCV에 의해 BGR로 변환된 이미지를 RGB형식으로 다시 변환해 주어야 한다는 것이다.
Referenced: https://copycoding.tistory.com/146
OpenCV CaptureVideo()
OpenCV에서는 로컬 또는 스트리밍에서 제공하는 비디오 데이터를 실시간으로 읽어 들일 수 있다.
import cv2
videoCapture = cv2.VideoCapture('C:/Users/USER/Desktop/테스트 사진/수집데이터/MVI_8409.MP4')
while True:
if self.videoCapture.isOpened():
(self.status, self.frame) = self.videoCapture.read()위 코드와 같이 파일의 경로 또는 URI를 매개변수로 전달하게 되면 그 아래에 while문을 통해 순차적으로 읽을 수 있다. 이때 status와 frame 정보를 반환하는데 status는 현재 VideoCapture 객체에 의해 정상적으로 frame 데이터를 읽고 있는 중인지 아닌지를 알 수 있어 if문으로 status가 True일 때만 frame을 읽으면 준비된 모든 프레임을 수집할 수 있게 된다.
OpenCV getTextSize()
OpenCV는 이미지 위에 각종 도형 및 텍스트를 그리는 기능을 지원한다. 따라서 텍스트를 삽입할 때에는 그 위치를 조절할 수 있어야 하는데 폰트마다 다른 크기를 가지는 텍스트를 어떻게 모든 경우에 알맞은 위치에 그려 넣을 수 있을까?
textSize = cv2.getTextSize(text=str(act_class_info[0]), fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1, thickness=1)
print(textSize) # ((61, 22), 10)위 코드를 확인하면 이 문제를 쉽게 해결할 수 있다. cv2.getTextSize()를 이용하면 현재 텍스트, 폰트, 크기, 굵기를 모두 적용했을 때 화면에 그려질 텍스트의 크기를 미리 가져올 수 있다. 이 방법이 좋은 점은 이렇게 폰트, 크기, 굵기를 미리 계산만 해주면 모든 경우에 알맞는 위치에 텍스트를 삽입할 수 있다는 것이다. 만약 폰트를 바꾸게 된다면 fontFace의 값을 바꿔주기만 하면 적절한 위치에 삽입된다.
return value는 ((가로, 세로) 베이스라인)과 같은 형식으로 전달된다.
베이스라인에 대한 설명은 참조 문헌에 남긴다.
Referenced: https://stackoverflow.com/questions/46266776/what-is-the-opencv-font-base-size-for-cvhersheyfonts, https://mesign.tistory.com/16
Human Pose Tip
필자는 기존에 Human Pose Detection 프로젝트를 진행할 때에 skeleton에 대한 landmarks, keypoints에 대해 코드 내에 사용되는 부분이 적어 리팩토링에 대한 필요성을 느끼지 못했는데, 혹시나 코드 내에서 이러한 내용이 여러 곳에서 사용된다면 json 파일로 만들어 필요할 때마다 불러오는 방법도 괜찮은 것 같다. landmarks에 대한 정의가 잘 안 바뀔 것 같지만 생각보다 조금씩 변경할 필요가 많이 있다. 따라서 코드에 산재되어 있는 변경 위험 요소들을 json과 같은 파일로 관리함으로써 결합도를 낮추는 방법을 고려해보자.
with open('human_pose.json', 'r') as f:
human_pose = json.load(f)TensorRT
TensorRT는 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU 상에서의 Inference 속도를 수십 배까지 향상시켜 Deep Learning 서비스 TCO (Total Cost of Ownership) 를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진입니다.
- TensorRT는 Tensorflow와 PyTorch와 같은 대부분의 딥러닝 프레임워크에서의 사용을 지원한다.
- 대부분의 Nvidia GPU 환경에서 적용하여 사용할 수 있다.
- C++, Python 언어의 API 레벨에서 TensorRT의 사용을 지원하기 때문에 간편하게 이용할 수 있다.
위 내용들은 Nvidia에서 TensorRT에 대한 공식 소개 내용이다. 이외에도 Tensor Optimization, Quantization & Precision Calibration, Graph Optimization 등 모델 최적화를 위한 Solution을 설명하는 내용들이 줄을 잇는다. 결정적으로 Nvidia에서 이러한 기능을 제공하는 이유는 자신들의 GPU를 이용해 딥러닝 기반의 산업용 소프트웨어를 실행할 때 이점을 주기 위함이다. 실제로 실시간 영상 객체 분류를 수행하려면 상당한 컴퓨팅 파워와 시간이 필요하다. 이런 문제를 획기적으로 해결해주는 것이 TensorRT라고 보면 되겠다.
하지만 단점으로는 TensorRT는 아시다시피 nvidia GPU에서만 동작할 수 있다. (개 중에서 Tensor Core를 포함하는 GPU만 가능)이러한 한계로 인해 다른 GPU를 사용하는 경우에는 해당 GPU 제조사에서 제공하는 모델 최적화 솔루션을 적용해야 할 것이다.
Referenced: https://blogs.nvidia.co.kr/2020/02/19/nvidia-tensor-rt/, https://blog.si-analytics.ai/33
