물리적 데이터 모델링
논리적 데이터 모델링에서 만든 TABLE들을 구체적인 Database 솔루션(제품)에 맞는 현실적인 TABLE들로 만드는 것이다.
관계형 데이터베이스에서 실제 데이터가 어떻게 저장될지를 정의하는 과정
간단히 말해서, 데이터베이스의 성능, 보안, 확장성을 고려하여 데이터베이스 시스템에 맞게 테이블을 만들고, 인덱스를 생성하며, 데이터 저장 방식을 결정하는 과정이다.
역정규화(denormalization)
정규화된 데이터를 다시 덜 정규화된 상태로 변경하는 과정
데이터베이스의 성능을 높이기 위해 데이터를 중복 저장하거나 여러 테이블을 하나로 합치는 작업
1. 컬럼을 조작해서 JOIN 줄이기
JOIN은 아주 비싼 작업이다. JOIN이 많이 일어나면 과부화 발생.

위의 테이블 들에서 MySQL에 해당하는 tag의 이름을 조회하려면 JOIN을 해야한다.
역정규화 이전 쿼리
SELECT tag.name
FROM topic_tag_ralation AS TTR
LEFT JOIN tag
ON TTR.tag_id = tag.id
WHERE topic_title = 'MySQL';JOIN을 줄이기 위해 topic_tag_relation 테이블에 tag_name 컬럼을 추가
=> 중복이 생기지만 JOIN 없이 데이터를 가져올 수 있다.

역정규화 후 쿼리
SELECT tag_name
FROM topic_tag_relation
WHERE topic_title = 'MySQL';2. 컬럼을 조작해서 계산 줄이기

author 별로 topic의 개수를 조회하고자 한다.
역정규화 이전 쿼리
SELECT author_id, count(author_id)
FROM topic
GROUP BY author_id;GROUP BY 같은 집계함수를 사용하는 작업이 빈번해지면 비싼 작업이 된다.
계산을 줄이기 위해 author 테이블에 topic_count 컬럼을 추가
=> 값을 불러오기만 하면 돼서 출력하기 저렴하지만 topic_count를 유지시켜야 하는 어려움이 있음
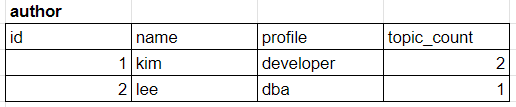
역정규화 후 쿼리
SELECT id, topic_count
FROM author;
