
책을 읽고 중요한 부분을 적어놓음
1장 데이터 과학과 파이썬 소개
1.1 데이터 과학이란?
- 빅 데이터란 다양한 형태의 데이터가 빠른 속도로 대량 생성되는 것
- 데이터 과학은 최근 AI 시대의 도래와 더불어 AI의 기반이 되는 데이터 분석과 활용이 중요해지면서 주목받고 있음
- 데이터 과학으로 처리되는 빅 데이터는 크기(Volume), 다양성(Variety), 속도(Velocity)라는 3V로 정의
- 크기 : 활용 대상이 되는 데이터의 크기를 의미. 데이터의 크기는 시대가 발전하면서 계속 급증하고 있기 때문에 빅 데이터가 되기 위한 크기를 정의하는 것이 쉽지 않음. 또한 크기에 대해서는 산업별, 영역별, 지역별로 차이가 있으며 때로는 언론에서 간혹 언급하는 PB(Peta Bytes)나 ZB(Zetta Bytes)보다 적은 크기의 데이터도 빅 데이터로 고려하는 경우가 있음.
- 다양성 : 빅 데이터는 다양한 형태를 가진다는 특징이 존재. 데이터의 형태는 크게 3가지로 구분 가능. CSV파일이나 RDB(관계형 DB)와 같이 구조화되어 있는 정형 데이터와 JSON 형태의 반정형 데이터, 그리고 구조화되어 있지 않은 비정형 데이터로 구분. 이와 같은 데이터의 다양성은 빅 데이터가 생성되는 다양한 출처에서 기인.
- 속도 빅 데이터는 빠르게 생성됨으로 이러한 생성 속도도 특성으로 고려할 수 있음. 온라인 게임처럼 실시간으로 생성되는 데이터, 동영상 같은 스트리밍 데이터도 빅 데이터 영역에 포함되므로 데이터의 생성 속도는 중요하게 고려됨. 빠르게 생성되는 빅 데이터에 대한 신속한 처리와 분석도 큰 이슈.
- 앞의 정의에서 볼 수 있듯이 빅 데이터는 본질적으로 '데이터'. 그렇기에 빅 데이터를 잘 이해, 활용하려면 데이터 과학이 중요
- 데이터 과학을 하기 위한 기법인 데이터 마이닝(data mining)은 데이터에서 유의미한 트렌드와 패턴 규칙을 발견하고자 대량의 데이터에서 자동화 혹은 반자동화 방법으로 데이터를 탐색하고 분석하는 과정
- 데이터 마이닝이란 대용량의 데이터를 분석해서 이해하고 앞으로의 사건에 대한 예측까지를 목표로 함. 즉, 데이터의 관계, 패턴, 규칙 등을 찾아내어 이를 체계적이고 통계적으로 모형화하여 이전에는 알지 못했던 유용한 지식을 발견하는 일련의 과정을 의미.
- 예를 들어 신용 평점 시스템의 신용평가모형 개발, 사기 탐지 시스템, 장바구니 분석, 최적 포트폴리오 구축, 웹 로그 분석, 소셜 미디어 분석을 통한 선거 전략 수립 등과 같이 다양한 산업과 분야에서 많이 사용
- 데이터 과학은 데이터를 기반으로 현상을 해석, 솔루션을 제시. 예를 들어 온라인 마케팅 용어로 그로스 해킹(Growth Hacking)이 있음. 그로스 해킹은 데이터를 기반으로 마케팅에 정량적으로 접근하고 의사 결정하는 것을 의미.
- 물론 데이터가 현실을 충분히 반영하지 못한다면, 모형도 현실을 충분히 반영 불가능할 위험이 존재. 그래서 데이터 수집부터 편향(bias)가 발생하지 않도록 주의, 분석할 때도 현실 관점에서 데이터를 균형있게 이해하도록 주의
- 이 뒤는 파이썬과 사용법에 대한 설명.
1.2 선형대수, 미분과 적분 확률 통계의 필요성
- 데이터를 다루는 데이터 과학에서는 값이 정량화되어 기록되기 때문에 이러한 정령화된 '값'을 다루는 것이 상당히 중요. 그에 따라 수학접 접근과 이해의 중요성이 부각됨
- 17세기 뉴턴이 미적분학을 발견한 이래 집합과 논리가 중요시되며 힐베르트, 괴델등 다양한 수학자들이 수학을 발전시킴. 이때 집합 이론이 발전. 집합 이론은 숫자, 벡터, 함수 등을 표현해 정의를 도입, 서로 간의 관계를 연구. 이 과정에서 정리(theorem), 보조정리(lemma), 따름정리(corollary) 등이 도입. 이렇게 많은 이론 수학이 발전되면서 자신들의 문제를 조금 더 간결히 표현 가능, 해결할 수 있게 되었고 많은 성과로 이어짐.
- 그 후 수집된 데이터에 대한 수학적 접근이 본격적으로 이뤄지는 통계적 방법이 빠른 속도로 발전. 결국 데이터 과학은 '숫자'를 다루는 분야이므로, 수학적 접근은 데이터를 바탕으로 문제를 정의하고 논리적으로 해결하는데 큰 역할을 함. 다양한 분야가 맞물려 돌아가는 데이터 과학에서 특히 가장 중요한 세 가지는 수학적 접근의 기반이 되는 '수학'과 데이터를 요약하고 파악하게 하는 '통계', 불확실한 현상을 표현할 수 있는 '확률'.
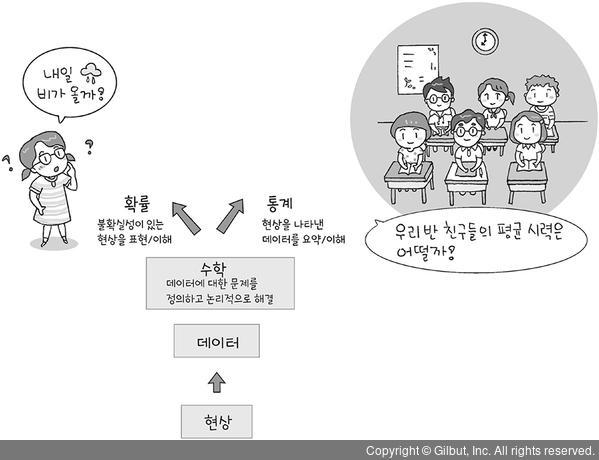
▲그림 1-21 데이터 과학에서의 수학적 접근 - 수학, 확률, 통계는 데이터 과학의 여러 컴퓨팅 기법과 머신 러닝, 딥러닝의 바탕. 데이터를 다루는 학제적인 영역에서 일종의 '공용어' 역할을 하기도 함. 다양한 분야를 다루는 만큼 데이터 과학은 여러 분야와 협업이 필수적인데, 이때 의사소통을 가능케 함.
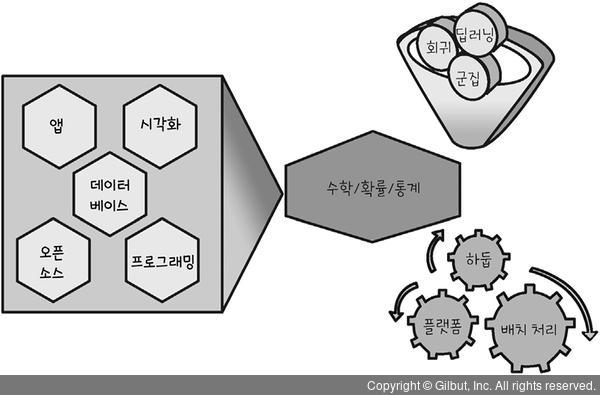
▲그림 1-22 다양한 분야와 협업을 가능케 하는 수학, 확률 통계
1.3 그리스 문자와 연산 기호.
데이터 과학을 시작함에 있어 가장 먼저 접하는 난관은 바로, 재미있게도 그리스 문자를 일고 이해하는 것이다. 처음 봤을 때는 암호처럼 느껴질지 모르겠지만, 자주 사용되는 문자를 읽고 그 의미를 이해할 수 있다면 데이터 과학의 다음 단계로 나아가는 데 큰 도움이 될 것이다.
그리스 문자
α와 β는 주로 계수(coefficient)나 기울기(slope) 등을 나타내는 데 사용된다. χ는 카이제곱 통계량에서 많이 사용되며, δ는 거리를 나타내는 데 사용되기도 한다. ω는 가중치를 나타낼 때, ρ는 상관관계 통계량을 나타낼 때 사용되며, σ는 표준편차를 나타낼 때 많이 사용된다(대소문자를 구분하는 것에 주의하자).
▼ 표 1-1 그리스 문자
| 대문자 | 소문자 | 이름 | 대문자 | 소문자 | 이름 |
|---|---|---|---|---|---|
| Α | α | alpha(알파) | Ν | ν | nu(뉴) |
| Β | β | beta(베타) | Ξ | ξ | xi(크시) |
| Γ | γ | gamma(감마) | Ο | ο | omicron(오미크론) |
| Δ | δ | delta(델타) | Π | π | pi(파이) |
| Ε | ε | epsilon(엡실론) | Ρ | ρ | rho(로) |
| Ζ | ζ | zeta(제타) | Σ | σ | sigma(시그마) |
| Η | η | eta(에타) | Τ | τ | tau(타우) |
| Θ | θ | theta(세타) | Υ | υ | upsilon(입실론) |
| Ι | ι | iota(이오타) | Φ | φ | phi(피) |
| Κ | κ | kappa(카파) | Χ | χ | chi(카이) |
| Λ | λ | lambda(람다) | Ψ | ψ | psi(프사이) |
| Μ | μ | mu(뮤) | Ω | ω | omega(오메가) |
연산기호
표 1-2에 자주 사용하는 연산 기호만 선별해 작성하였다. 이중에서 ≤ 와 ≥는 부등호 연산자이고, ≠는 같지 않음을 의미한다. ≅는 거의 같음을 나타내는 연산 기호이고, ∝는 ~에 비례함을 나타낸다. √는 근호(square root)라고 하며 제곱했을 때 근호 안의 수가 나오는 값을 찾아준다. ∀은 for all이라는 뜻으로 모든 값을 의미하며, E를 거꾸로 쓴 것과 같은 연산자인 ∃(Exists)는 어떤 값이 존재한다는 것을 알려준다.
▼ 표 1-2 연산 기호
| 기호 | 설명 | 기호 | 설명 |
|---|---|---|---|
| ≤ | 작거나 같다. | ∪ | 합집합 |
| ≥ | 크거나 같다. | ∩ | 교집합 |
| < | 작다. | ⊂ | 부분 집합 |
| > | 크다. | Δ | 증분 |
| ∞ | 무한대 | ∑ | 합계 |
| ≠ | 같지 않다. | ∏ | 곱 |
| ≅ | 거의 같다. | ∝ | 비례 |
| ∀ | 모든(for all) | ∂ | 편미분 |
| ∃ | 존재한다. | ∫ | 적분 |
 | 존재하지 않는다. | √ | 근호 |
| ∈ | 원소를 포함한다. | ∴ | 결괏값 |
물론 한 번에 모든 그리스 문자와 연산 기호를 다 알 수는 없지만, 아마도 중요한 문자와 기호 몇 개는 익숙해졌을 것이다. 데이터 과학을 접하는 도중에 궁금한 그리스 문자나 연산 기호가 있다면 다시 여기로 돌아와 확인하자.
데이터와 변수의 이해
- 데이터는 어떠한 값의 모음. 어떻게 모여있는지에 따라 크게 정형 데이터, 반정형 데이터, 비정형 데이터로 나눌 수 있음.
- 데이터 과학에서는 이 중에서 정형 데이터를 많이 사용.반정형 데이터나 비정형 데이터를 다룬다 하더라도 결국은 정형화하여 분석. 여기서 말하는 정형 데이터는 행과 열이 있는 형태로 값을 모아 놓은 데이터를 의미
▼ 표 1-3 이동 통신사 고객 데이터를 행과 열로 표현한 결과
이름 성별 나이 거주지 직업 요금 데이터 사용량 휴대폰 선호도 AAA F 20 서울 회사원 55,000 3GB LG BBB F 19 인천 자영업 45,000 9GB 삼성 CCC M 25 김포 회사원 35,000 1GB 샤오미 DDD F 42 대전 회사원 75,000 4GB LG EEE F 27 서울 자영업 65,000 2GB 소니 FFF M 20 서울 회사원 55,000 3GB LG GGG M 43 서울 자영업 45,000 9GB 삼성 HHH M 25 대전 회사원 95,000 11GB 샤오미 III F 42 김포 회사원 45,000 3GB LG JJJ F 27 인천 자영업 45,000 4GB 소니
- 위와같이 행과 열로 잘 구분한 형태의 데이터를 정형(structured) 데이터라 부름.
- 정형 데이터의 각 열은 성격의 값을 나타냄. 즉, 성별 열은 성별만, 요금 열은 사용 요금만 나타나게 되는데, 성별이나 요금은 사람에 다라 다르므로 고정되어 있는 값은 아님.
- 이 각 열을 변수라 부르도록 함.
- 지금 요금의 열의 경우에는 모두 수치 값인 요금만 들어가는데, 이 값을 양적 자료(quantitative data) 또는 계측 자료(metric data) 라고 함.
- 이러한 수치 값은 사칙 연산이 가능하다는 특징이 있으며 그렇기에 합계, 평균, 최댓값, 최솟값, 분산 등으로 데이터를 요약하고 정리할 수 있음.
- 반면에 성별 열의 경우 값들이 수치 값이 아님. 성별 값으로는 남자나 여자를 갖고, M과 F로 표현하였는데. 이런 양적으로 측정되지 않는 값들을 질적자료(qualitative data) 또는 비계측 자료(nonmetric data)라고 부름.
- 이런 질적 자료들을 범주형(categorical data) 라고도 부름. 거주지나 성별이 해당됨.
- 거주지와 성별의 경우 순서가 없지만, 예를 들어 '수/우/미/양/가'와 같은 값이 사용되면 이는 질적 자료임과 동시에 순서가 있는 값이 됨. 이처럼 순서가 있는 범주형 자료는 순서 자료(ordinal data)라고 함. 순서가 없는 범주형 자료를 명목 자료(nominal data) 라고 함
- 단, 순서자료임에도 사칙 연산을 할 수 없는 점을 유의해야 함
- 이런 질적 자료들을 범주형(categorical data) 라고도 부름. 거주지나 성별이 해당됨.
- 다음 표에서 DDD 한 사람, 각 정형 데이터의 행을 관측치 또는 관측된 개체(observation, case, individual, object)라고 부름.
- 또한 다음 표에서 거주지와 같은 같은 기준으로 측정한 열을 개체의 속성이라 할 수 있으며, 앞서 말했듯이 변수라 부르기도 함.
- 변수는 상황에 따라 다른 이름을 가질 수 있음. 그리고 의미도 조금 다를 수 있지만, 자료 형태로 봤을 때 대부분 열에 해당. 그리고 앞서 살펴본 바와 같이 변수에는 그 값에 따라 양적 변수, 질적 변수 등이 있음
- 이때 우리가 주의깊게 봐야할 것은 종속변수. 통칭 Y 변수. 이 변수는 다른 변수에 의해 영향을 받는 변수인데 분석에 있어 우리가 알고 싶은 값을 나타냄.
- Y 변수에 영향을 주는 변수를 독립 변수, 설명 변수라 하며, X 변수라고도 부름. 이 변수는 종속 변수에 영향을 주는 의미
- 변수는 상황에 따라 다른 이름을 가질 수 있음. 그리고 의미도 조금 다를 수 있지만, 자료 형태로 봤을 때 대부분 열에 해당. 그리고 앞서 살펴본 바와 같이 변수에는 그 값에 따라 양적 변수, 질적 변수 등이 있음
이후에는 파이썬 실습, R 실습을 하게됨.
