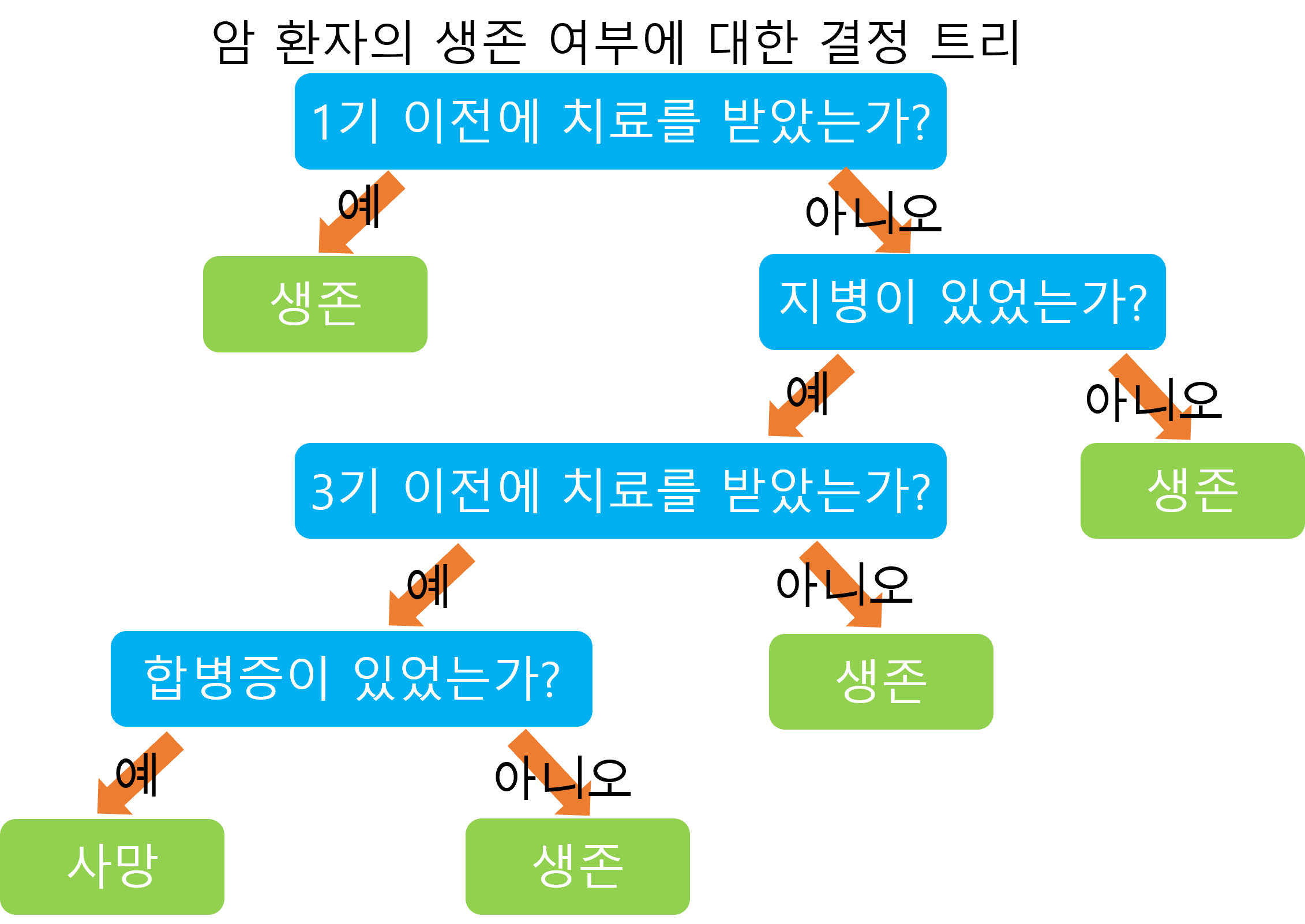
결정 트리(Decision Tree)

- 예/아니오로 답할 수 있는 질문들의 답을 따라가면서 데이터를 분류하는 알고리즘
- 결정 트리는 질문과 답으로 이루어져 있다.
(위 그림에서는 하늘색이 질문, 연두색이 분류에 해당한다.)- 박스 하나하나를 노드(node)라고 한다.
- 맨 위의 질문 노드를 root node, 트리의 가장 끝에 있는 노드를 leaf node라 한다.
- 결정 트리에서 leaf node들은 예측값을, 나머지 node들은 질문을 가지고 있다.
- 하나의 속성에 대해서 여러 번 질문할 수 있다.
결정 트리의 장점
- 데이터를 분류하는 방법이 직관적이다.
- 쉽게 해석할 수 있다.(어떤 속성이 중요하게 사용되었는지 알 수 있다.)
지니 불순도(Gini Impurity)
- 지니 불순도는 데이터 셋 안에 서로 다른 분류들이 얼마나 섞여있는지를 나타낸다.
- 결정 트리에서 각 노드(질문)의 위치를 결정하는 척도(손실 함수 같은 역할)
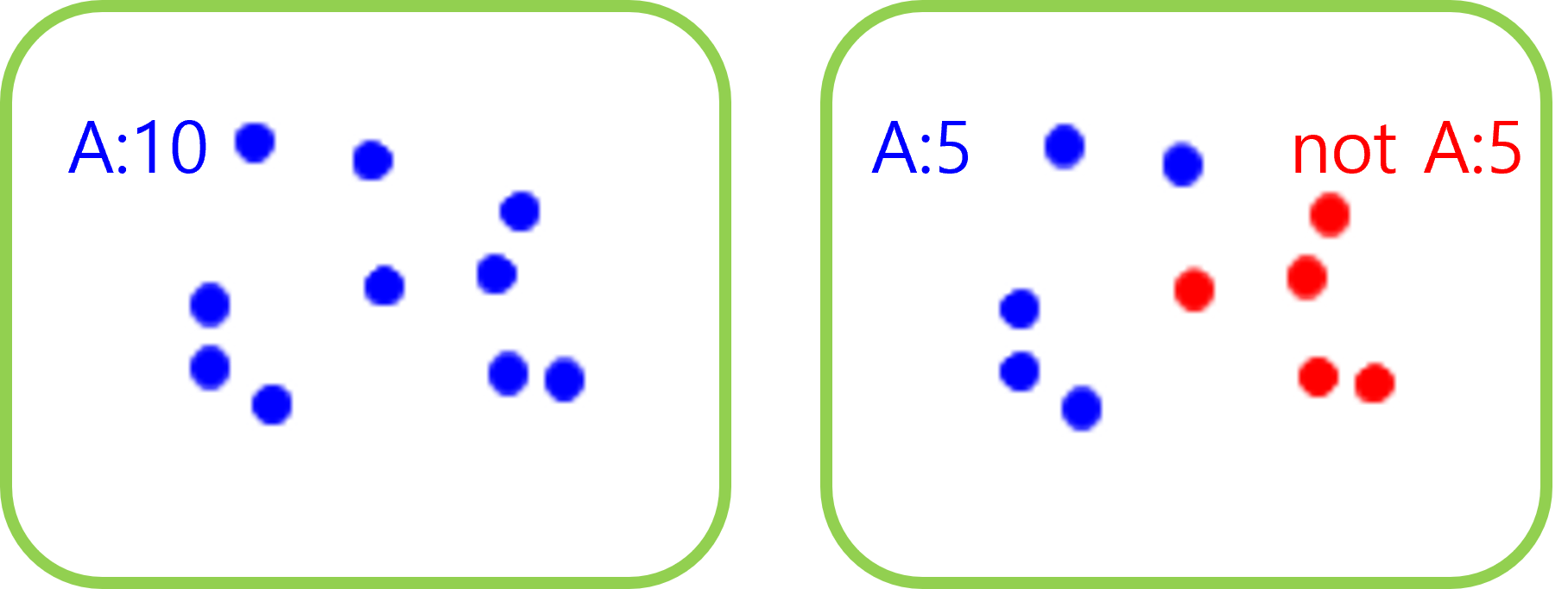
- 지니 불순도()가 낮을수록 데이터가 순수하다. (데이터가 단조롭다.)
지니 불순도가 높을수록 데이터가 불순하다. (다양한 데이터가 섞여있다.)- 위 그림에서 왼쪽의 경우 지니 불순도가
- 위 그림에서 왼쪽의 경우 지니 불순도가
결정 트리 만들기
노드 평가하기
- 지니 불순도를 기준으로 가장 좋은 노드를 고른다.
- 지니 불순도가 높다 질문 노드
- 지니 불순도가 낮다 분류 노드
분류 노드 평가하기
- 좋은 분류 노드는 학습 데이터를 예측의 정확도가 높아야 한다.
분류는 해당 데이터에서 가장 많은 분류로 결정된다.
데이터 셋이 순수할수록(지니 불순도가 낮을수록) 좋다.
질문 노드 평가하기
- 좋은 질문 노드는 데이터를 잘 나눠서 아래 노드들이 분류하기 쉽게 만든다.
질문으로 나뉜 데이터 셋이 순수할수록(지니 불순도가 낮을수록) 좋다.
(질문 노드의 지니 불순도는 질문으로 나뉜 두 데이터 셋의 지니 불순도의 평균이다.
단, 양쪽의 데이터 수에 대해서 무게를 준다.)
노드 고르기
- 분류 노드, 질문 노드들 중 지니 불순도가 가장 낮은 노드를 고른다.
- 분류 노드의 불순도가 가장 작으면 이미 데이터가 잘 나누어져 있다는 것이므로 그대로 분류해도 된다.
- 질문 노드의 불순도가 가장 작으면 질문을 통해서 지금 있는 데이터 셋보다 불순도를 더 낮출 수 있다는 것이므로 질문 노드를 고른다.
모든 노드 만들기
- 속성이 수치형인 질문 노드: 시속 50km 이상인가요 등, 같은 속성을 다시 쓸 수 있다.
- 속성이 boolean형인 질문 노드: 안전벨트를 했나요 등, 같은 속성을 다시 쓸 이유가 없다.
- 노드 고르기 과정을 모든 leaf 노드가 분류 노드가 될때까지 반복하여 결정 트리를 만든다.
- 트리가 몇층까지 내려가는지를 트리 깊이 라고 하는데 결정 트리를 만들 때 트리 깊이를 제한할 수 있다.
제한된 깊이까지 도달하면 더 이상 불순도를 비교하지 않고 분류노드로 만든다.
속성이 수치형인 경우 만들 수 있는 질문이 매우 많기 때문에 질문을 만드는 방법은 아래와 같다.
데이터의 수치형 속성을 정렬한다.
각 연속된 수치형 데이터의 평균을 계산한다.
평균들로 질문을 만들어 해당 질문의 지니 불순도를 구한다.
지니 불순도가 가장 낮은 질문을 선택한다.
수치형 속성을 가진 질문을 다시 만들 때는 이를 반복한다.
노드 중요도(Node Importance)
- 위 노드에서 아래 노드로 내려오면서 불순도가 얼마나 줄어들었는지를 타나대는 수치이다.
- 노드 중요도가 높을수록 중요한 노드이다.
- 나눠지는 데이터 셋들에 대해서 점점 더 알아간다고 해서 정보 증가량(information gain)이라고도 한다.
( : 노드까지 오는 데이터 수, : 전체 학습 데이터 수, : 노드의 지니 불순도, 좌,우 노드에 대해서 똑같이 적용)
속성 중요도(Feature Importance)
- 특정 속성이 얼마나 평균적으로 지니 불순도를 얼마나 낮췄는지를 나타내는 수치이다.
특정 속성이 결정 트리에서 얼마나 중요한지 알 수 있다. - 모든 질문 노드의 중요도를 계산한 후 이를 이용하여 속성 중요도를 구할 수 있다.
- 평균 지니 감소(Mean Gini Decrease)라고 부르기도 한다.
(속성 A에 대한 속성 중요도는 모든 A 속성 질문 노드의 중요도의 합/모든 노드 중요도합으로 구한다.)
이 글은 코드잇 강의를 수강하며 정리한 글입니다. 더 자세한 설명은 코드잇을 참고하세요

미래의 개발자입니다!