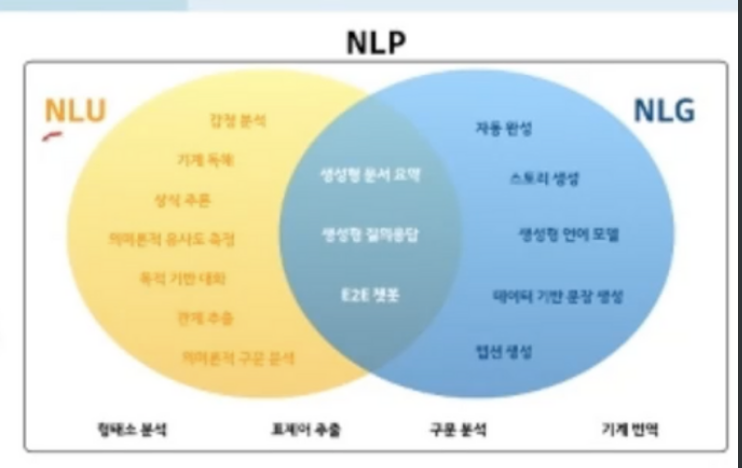
순환 신경망의 사용처
.gif)
- 순환 신경망은 분별 모델뿐 아니라 생성 모델로도 활용됨
- 장기 문맥을 처리하는 데 유리한 LSTM이 주로 사용됨
언어 모델
- 문장, 즉 단어 열의 확률분포를 모형화
- P(자세히, 보아야, 예쁘다) > P(예쁘다, 보아야, 자세히)
- 같은 표현들이 사용됐지만 주로 사용되는 확률분포를 따진다는것!
- 음성 인식기 또는 언어 번역기가 후보로 출력한 문장이 여럿 있을 때, 언어 모델로 확률을 계산한 다음 확률이 가장 높은 것을 선택하여 성능을 높임
- 확률분포를 추정하는 방법
- n-그램
- 다층 퍼셉트론
- 순환 신경망
n-그램을 이용한 언어 모델
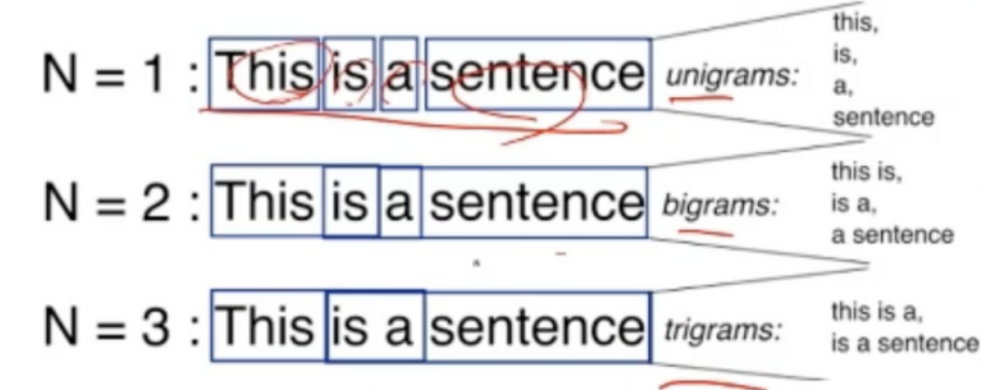
- 고전적인 방법
- n=1: unigrams
- n=2: bigrams
- n=3: trigrams

- 문장을 x = (z1,z2,...,z_T)^T 라 하면 x가 발생할 확률은 위의 식으로 정리됨
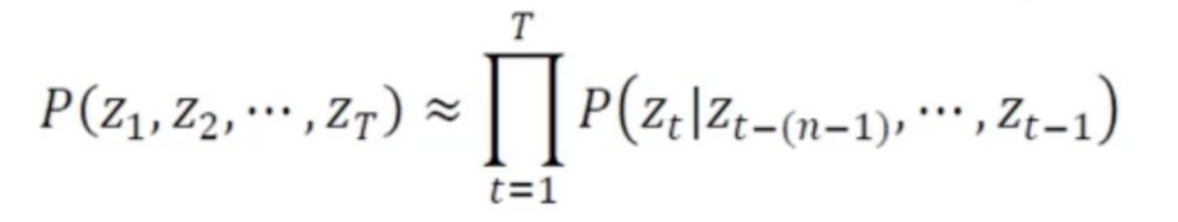
- n-그램은 n-1개의 단어만 고려하는데, 이때 위의 식이 성립
- 알아야 할 확률의 개수가 m의n승이므로 차원의 저주 때문에 n을 1~3정도로 작게 해야 함
- 확률 추정은 말뭉치를 사용
단점
- 단어가 원핫 코드로 표현되므로 단어 간의 의미 있는 거리를 반영하지 못하는 한계
순환 신경망을 이용한 언어 모델
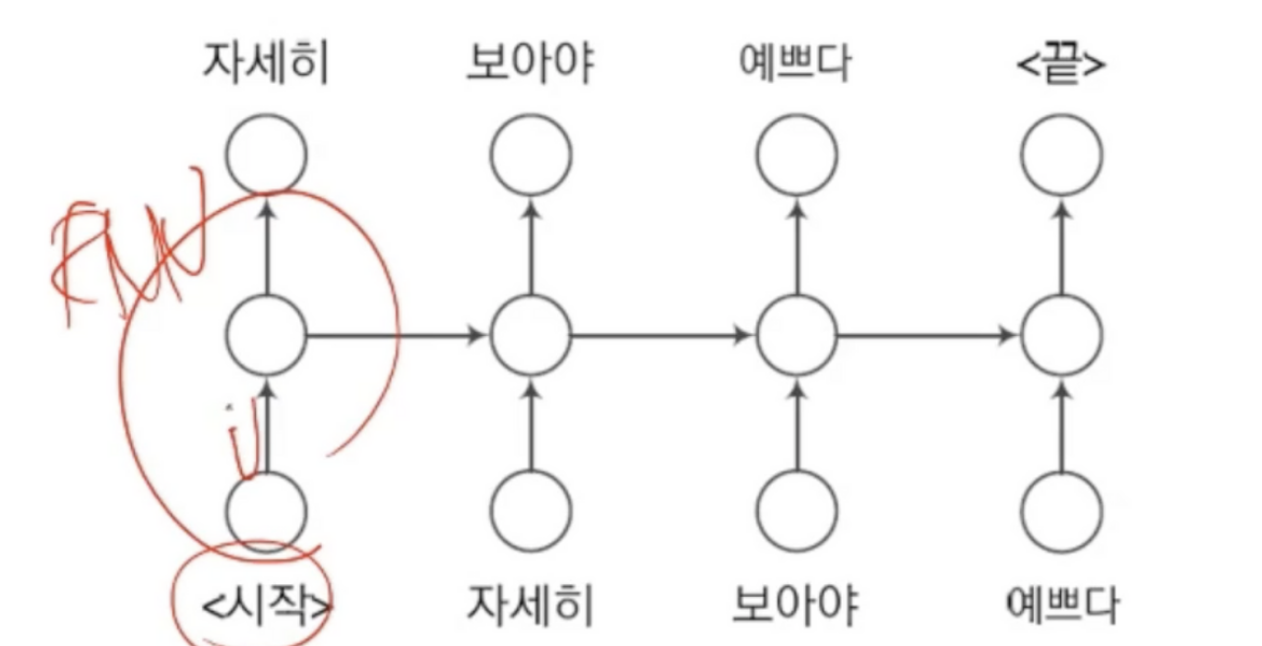
- 현재까지 본 단어 열을 기반으로 당므 단어를 예측하는 방식으로 학습
- 비지도 학습에 해당하여 말뭉치로부터 쉽게 훈련집합 구축 가능

- 위와 같은 훈련집합으로 학습 진행
- 말뭉치에 있는 문장을 위 식처럼 변환하여 훈련집합을 만든 다음, BPTT학습 알고리즘을 적용
학습을 마친 순환 신경망(언어 모델)의 활용
- 기계 번역기나 음성 인식기의 성능을 향상하는 데 활용
- (자세히, 보아야, 예쁘다)와 (자세를, 모아야, 예쁘다) 라는 2개 후보를 출력했을 때 언어 모델로 각 확률분포를 계산하고 높음 확률의 후보를 선택
- 일반적으로 사전학습을 수행한 언어 모델을 개별 과제에 맞게 미세 조정함
생성 모델로 활용
- 시작할 키워드 하나를 입력
- 다음 단어로 올 것들중 확률이 높은 것을 선택
- 그 단어를 시작한 키워드 다음으로 붙임
- 위 동작을 계속적으로 수행
주요 언어 모델
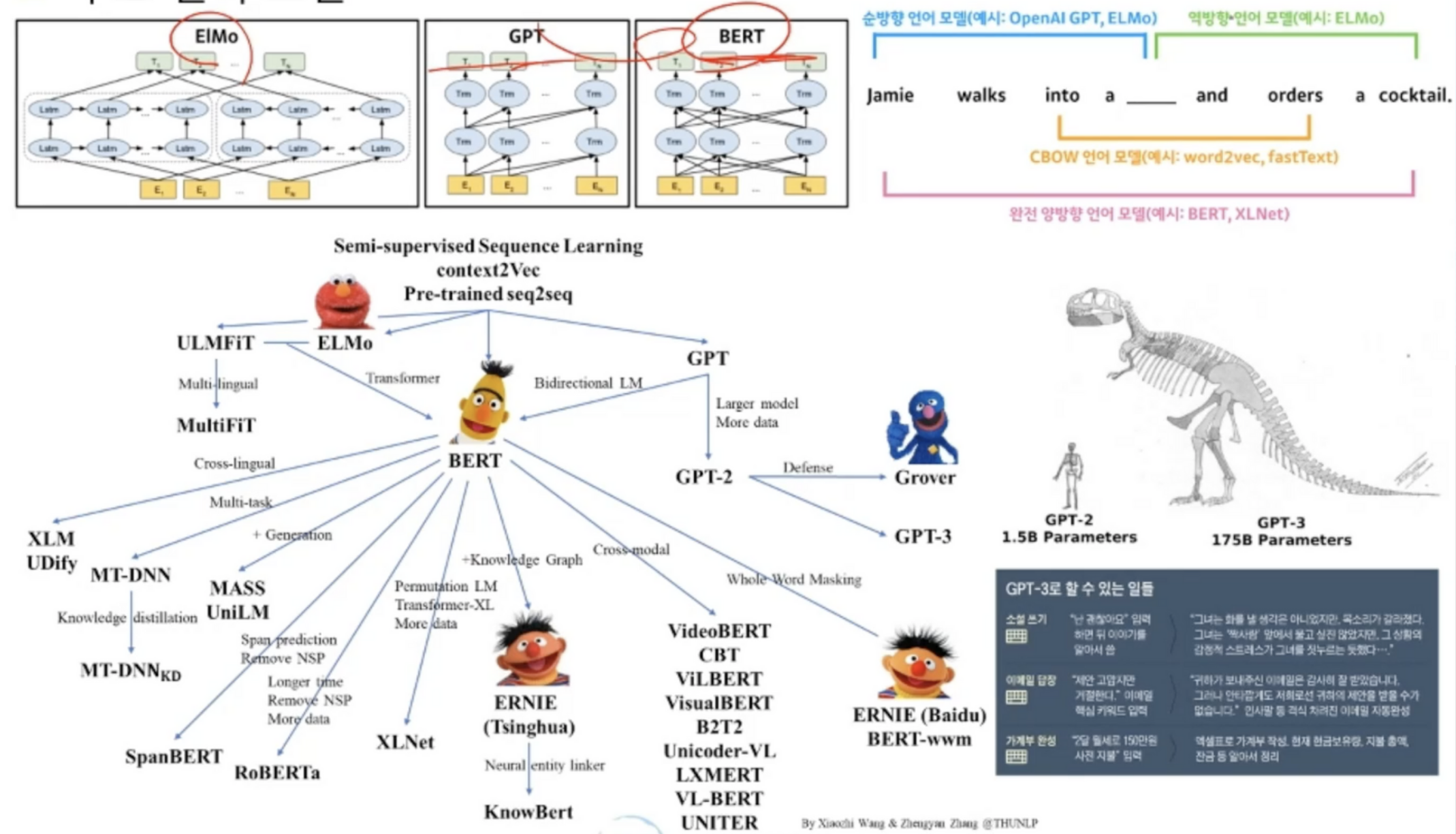
- GPT는 단방향
- BERT는 양방향
- ELMo는 원천적 초기 기술
- 소설, QnA, 가계부 완성 등 GPT3가 해냄
- 이미 만들어진 모델들의 Pretrained로 많이 사용

컴퓨터가 좋아