
Level 3
문제
정답
from collections import deque
def solution(begin, target, words):
def bfs(begin, cnt):
q=deque()
q.append([begin, 0])
visited=[0]* len(words)
while q:
word, cnt = q.popleft()
if word == target:
return cnt
for i in range(len(words)):
tmp_cnt=0
if not visited[i]:
for j in range(len(word)):
if word[j] !=words[i][j]:
tmp_cnt+=1
if tmp_cnt ==1:
q.append([words[i], cnt+1])
visited[i]=1
if target not in words:
return 0
else:
answer= bfs(begin, 0)
return answer접근했던 방법
정답 X
- words 내의 단어들을 list()를 써서 dog 라면 d, o, g로 나눠 앞선 단어와 2개가 맞는다면 방문체크하고, 이를 사용하도록 하고, cog를 찾을 때까지 돌려서 루트를 세는 것이다. 구현하면서 성능 문제가 있을 것 같다고 생각은 했지만..
역시 구현하고 테스트로 돌려보니.. 10초 넘게 걸려 '실행 시간이 10.0초를 초과하여 실행이 중단되었습니다. 실행 시간이 더 짧은 다른 방법을 찾아보세요.' 이러한 메시지가 떴다.
def solution(begin, target, words):
visited=[0]* len(words)
print(visited)
def dfs(b, k):
n=0
b=list(b)
res=0
while(b!=target):
for i in range(k,len(words)):
for j in range(len(words[i])):
if (visited[i]==1):
continue
if b[j]==words[i][j]:
n+=1
if n == len(words[i])-1 and visited[i]==0:
visited[i]=1
res+=1
dfs(words[i], i)
return res
answer = 0
if target not in words:
return 0
else:
answer= dfs(begin, 0)
return answer그래서 두번째로 더 효율적인 방법을 생각해봤다.
정답 X
- 문자의 자릿수에 따라 딕셔너리에 넣어 사용하는 것이다
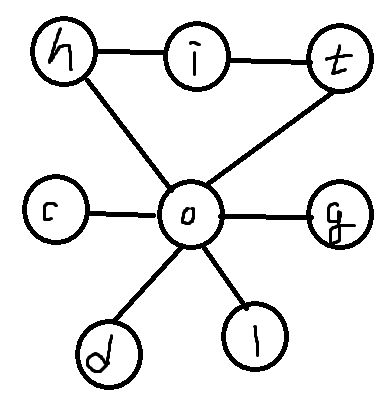
이러한 그래프를 그려서 이렇게 구현하면 되지 않을까 싶었다..
근데 구현은 어떻게 해야할지 고민이 되었다 아무래도 접근을 잘못한건가 싶어서 결국 다른 사람의 코드를 참고해 학습하며 작성해보고자 한다..ㅠㅠ
후기
혼자 너무 어렵게 생각했다.. 사실 간단히 해결될 문제였다. 코드도 보고 바로 이해돼서 허무했다..
심지어 굳이 list()로 문자를 안나누고 그냥 이차원 배열을 써도 한 글자씩 잘 가져오는 것을 알 수 있었다.
그리고, 나 같은 경우는 겹치는 글자가 len(word)-1와 같다면 진행하도록 했는데, 참고한 코드에서는 안겹치는 글자가 1개라면으로 구현한 것을 볼 수 있다. 처음 접근은 잘 했지만 , BFS를 어떻게 써야할지 모르겠어서 그냥 구현의 단계에서만 해결했지만, 다음에는 더 생각하고 구현해야할 것 같다.

I believe in myself.