
The main idea of BentoML is that the Data Science team should be able to ship their models in a way that is easy to test, easy to deploy, and easy to integrate with. And to do so, Data Scientists need tools that help them build and ship prediction services, instead of uploading pickled model files or Protobuf files to a server and hoping things work out.
BentoML
BentoML은 모델을 빠르고 쉽고 좋은 성능으로 Serving 할 수 있게 도와주는 프레임워크입니다.
기존에 Flak로 만들어진 서빙 앱의 성능 이슈 및 ML 개발자 친화적으로 배포 프로세스를 정립하기 위해 BentoML을 도입하게 되었습니다.
도입 후 느낀 점이지만 BentoML 도입으로 모든게 해소되지 않았습니다.여전히 초보 단계의 서빙 구조라 생각하며 좀 더 견고하고 좀 더 스마트한 구조로 발전시키고 싶습니다.
여기에서는 적용 단계 내용 중에 중요한 내용만 간략하게 소개하겠습니다.
배포 부분에서는 인프라 쪽과 배포 파이프라인도 빠질 수 없지만 BentoML을 중심적으로 적겠습니다.BentoML로 서빙 앱을 만들고 배포까지, 한 사이클을 구현하고 싶은 분들에게 도움이 되었으면 좋겠습니다.
초간단 BentoML Tutorial
sklearn으로 간단하게 모델을 학습시켜 모델 서빙(local 환경) 까지 구현하는 간단한 웹 어플리케이션을 만들어보겠습니다.
파일 구조
bentoml/
├── bento_packer.py # responsible for packing BentoService
├── bento_service.py # BentoService definition
├── requirements.txt
└── models/
└── train.py # training scriptsBentoML 패키지 설치
$ pip install bentoml==0.13.1학습으로 모델 생성
models/train.py
from sklearn import svm
from sklearn import datasets
# Load training data
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Model Training
clf = svm.SVC(gamma='scale')
clf.fit(X, y)서비스(API) 코드 작성
bento_service.py
import pandas as pd
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import DataframeInput
from bentoml.frameworks.sklearn import SklearnModelArtifact
@env(infer_pip_packages=True)
@artifacts([SklearnModelArtifact('model')])
class IrisClassifier(BentoService):
"""
A minimum prediction service exposing a Scikit-learn model
"""
@api(input=DataframeInput(), batch=True)
def predict1(self, df: pd.DataFrame):
"""
An inference API named `predict` with Dataframe input adapter, which codifies
how HTTP requests or CSV files are converted to a pandas Dataframe object as the
inference API function input
"""
return self.artifacts.model.predict(df)IrisClassifier는 웹 어플리케이션의 Controller class와 유사합니다.predict1()이 실제 요청을 처리하는 Controller@api()에 route를 정의하지 않으면 URL path가 predict1이 됩니다.- POST /xxx/predict1
@artifacts()에SklearnModelArtifact은bento_packer.py에 정의한 모델을 사용하겠다는 의미이며 artifact type은 sklearn입니다.
BentoML 패킹 코드 작성
bento_packer.py
from models.train import clf
from bento_service import IrisClassifier
# Create a iris classifier service instance
iris_classifier_service = IrisClassifier()
# Pack the newly trained model artifact
iris_classifier_service.pack('model', clf)
# Save the prediction service to disk for model serving
saved_path = iris_classifier_service.save()iris_classifier_service.pack('model', clf)에서 train 코드를 통해 학습된 모델을 서비스에서 사용할 수 있도록 연결합니다..save()는 모델, 서비스 코드를 배포 가능한 상태인 bundle로 만듭니다.
bundle 생성
$ export BENTOML_HOME=/xxx/bentoml
$ bentoml list
BENTO_SERVICE AGE APIS ARTIFACTS LABELS
$ python bento_packer.py
[2021-10-12 17:21:31,932] INFO - BentoService bundle 'IrisClassifier:20211012172130_3A79E6' saved to: /Users/byeongsookim/Documents/projects/bentoml/repository/IrisClassifier/20211012172130_3A79E6
$ bentoml list
BENTO_SERVICE AGE APIS ARTIFACTS LABELS
IrisClassifier:20211012172130_3A79E6 27.83 seconds predict1<DataframeInput:DefaultOutput> model<SklearnModelArtifact>BENTOML_HOME은 만들어질 bundle 및 로그 저장 경로는 정의함bento_packer.py를 실행하면 bentoml 폴더에 아래 폴더 및 파일이 생성됨- logs/* : 로그
- repository/* : bundle, 배포용 API 코드 및 모델
- storage.db : bundle을 관리하기 위함의 DB(SQLite)
Web App Run
$ bentoml serve IrisClassifier:latest
...
======== Running on http://0.0.0.0:5000 ========
(Press CTRL+C to quit)
* Serving Flask app "IrisClassifier" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:50594/ (Press CTRL+C to quit)- Swagger 문서
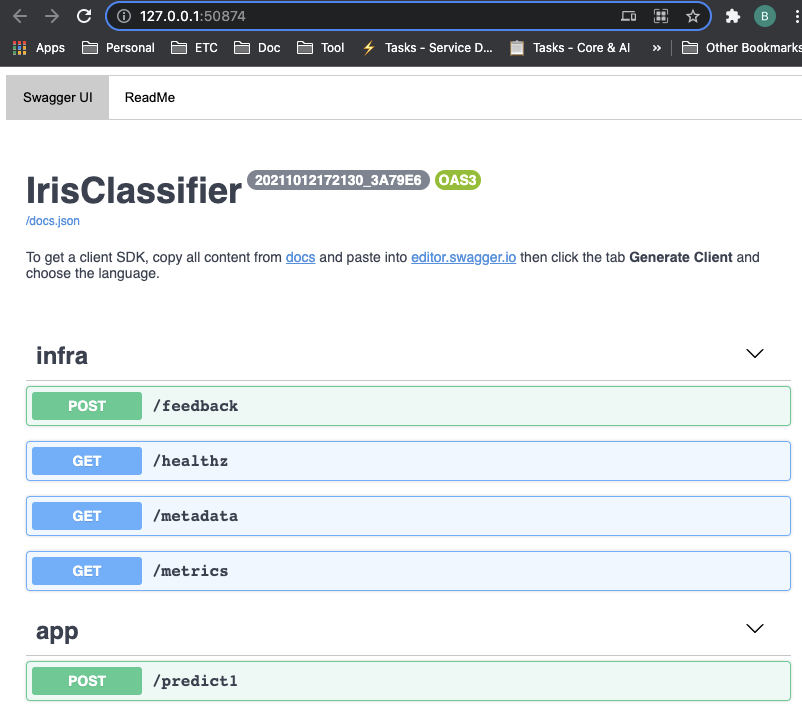
- 요청 테스트
$ curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[[5.1, 3.5, 1.4, 0.2]]' \
localhost:5000/predict
HTTP/1.1 200 OK
Content-Type: application/json
X-Request-Id: 5c0d591a-0078-4887-90c9-0b4b22f38702
Content-Length: 3
Date: Tue, 12 Oct 2021 08:48:30 GMT
Server: Python/3.6 aiohttp/3.7.4.post0
[0]%Yatai server
Yatai server는 BentoML Command로 관리되는 bundles 및 deployments를 웹 형태로 볼 수 있게 해줍니다.
또한 Yatai server는 기본적으로 bundle 정보는 SQLite로, bundle file은 Local에 저장하지만 PostgreSQL 또는 AWS S3에도 저장 가능합니다.
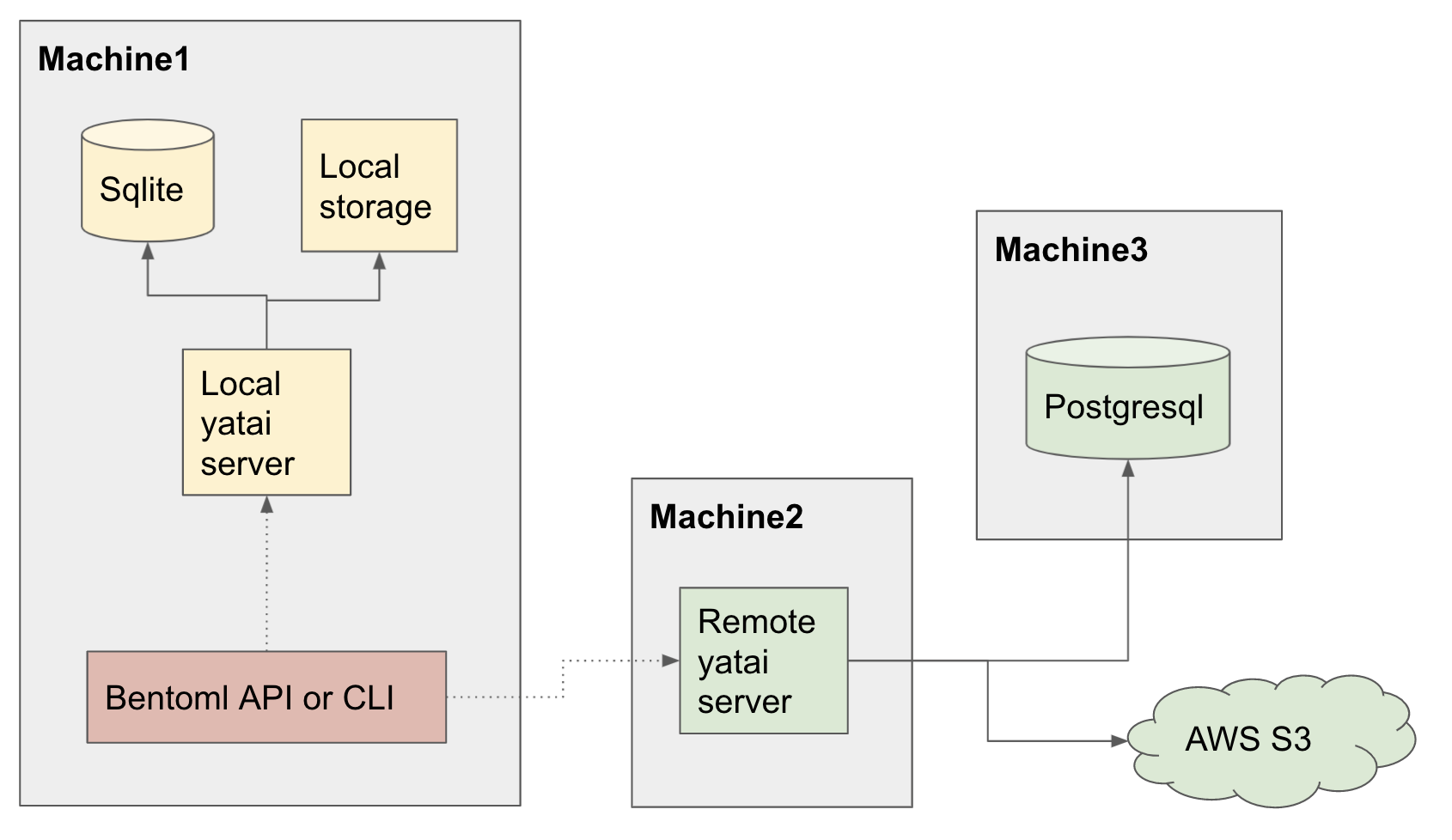
Yatai server 실행 - Local 환경
$ bentoml yatai-service-start --grpc-port 50051
* Starting BentoML YataiService gRPC Server
* Debug mode: off
* Web UI: running on http://127.0.0.1:3000
* Running on 127.0.0.1:50051 (Press CTRL+C to quit)
* Prometheus: running on http://127.0.0.1:3000/metrics
* Help and instructions: https://docs.bentoml.org/en/latest/guides/yatai_service.html
* Web server log can be found here: /Users/byeongsookim/Documents/projects/perfitt-ai-engine_v2/logs/yatai_web_server.log
-----
* Usage in Python:
* bento_svc.save(yatai_url="127.0.0.1:50051")
* from bentoml.yatai.client import get_yatai_client
* get_yatai_client("127.0.0.1:50051").repository.list()
* Usage in CLI:
* bentoml list --yatai-url=127.0.0.1:50051
* bentoml containerize IrisClassifier:latest --yatai-url=127.0.0.1:50051
* bentoml push IrisClassifier:20200918001645_CD2886 --yatai-url=127.0.0.1:50051
* bentoml pull IrisClassifier:20200918001645_CD2886 --yatai-url=127.0.0.1:50051
* bentoml retrieve IrisClassifier:20200918001645_CD2886 --yatai-url=127.0.0.1:50051 --target_dir="/tmp/foo/bar"
* bentoml delete IrisClassifier:20200918001645_CD2886 --yatai-url=127.0.0.1:50051BentoML API & Yatai server로 bundle 생성
- 코드
bento_packer_with_yatai.py
from models.train import clf
from bento_service import IrisClassifier
# Create a iris classifier service instance
iris_classifier_service = IrisClassifier()
# Pack the newly trained model artifact
iris_classifier_service.pack('model', clf)
# Save the prediction service to disk for model serving
saved_path = iris_classifier_service.save(yatai_url='127.0.0.1:50051')위 bento_packer.py 파일과 동일하고 .save(yatai_url=...) 을 설정한 것만 다릅니다.
- bundle 생성
$ python bento_packer_with_yatai.py
[2021-10-16 01:23:29,422] INFO - BentoService bundle 'IrisClassifier:20211016012326_50FC64' saved to: /Users/byeongsookim/Documents/projects/perfitt-ai-engine_v2/repository/IrisClassifier/20211016012326_50FC64
$ bentoml list --yatai-url 127.0.0.1:50051
BENTO_SERVICE AGE APIS ARTIFACTS LABELS
IrisClassifier:20211016012326_50FC64 57.82 seconds predict1<DataframeInput:DefaultOutput> model<SklearnModelArtifact>Yatai Web server
'127.0.0.1:3000' 으로 접속하면 Web UI를 확인할 수 있습니다.
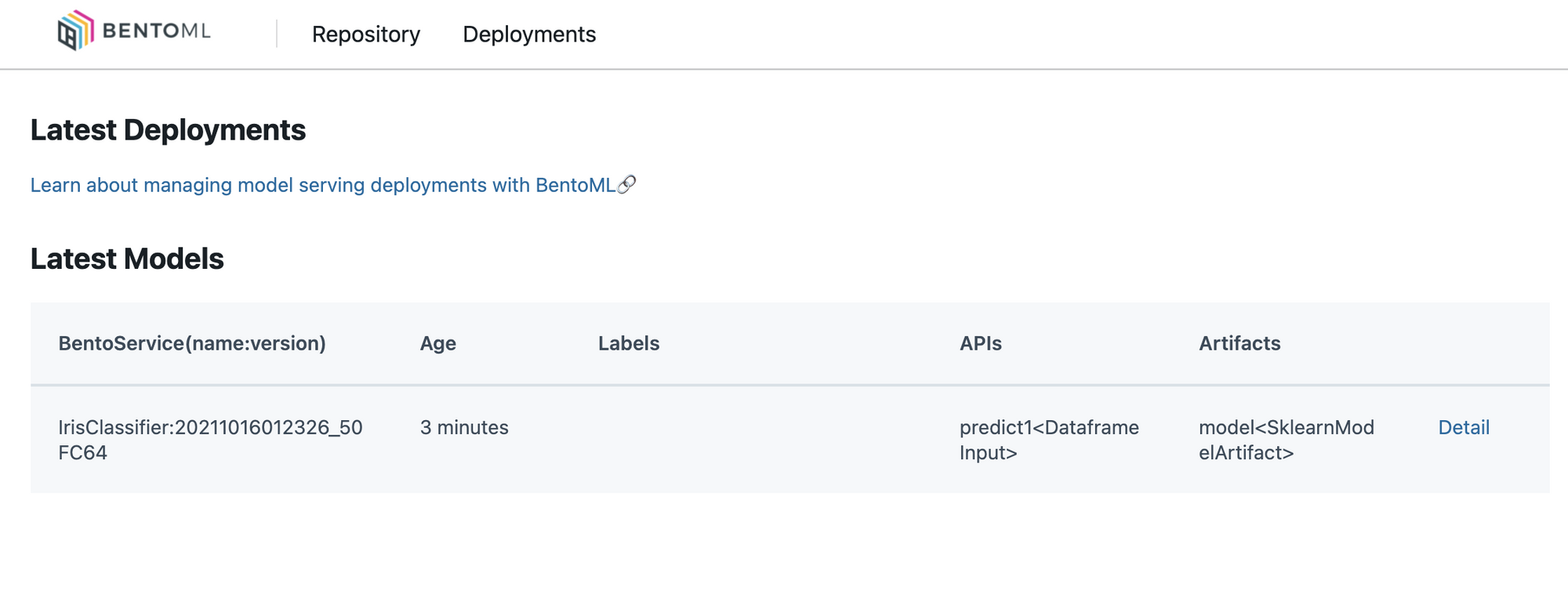
배포 파이프라인
- BentoML에서는 이미 다양한 형태의 배포를 지원합니다.
- 하지만 AWS Elastic Beanstalk를 서버로 이용할 예정이기에 BentoML에서 제공하는 기능을 사용하지 않고 AWS CLI를 이용합니다.
- 여기에서는 AWS Elastic Beanstalk에 대해서는 언급하지 않겠습니다.
- 이 글은 실제 업무에 BentoML을 적용한 케이스를 소개하는 글이기에 구현한 환경을 소개하겠습니다.
배포 파이프라인 구성도
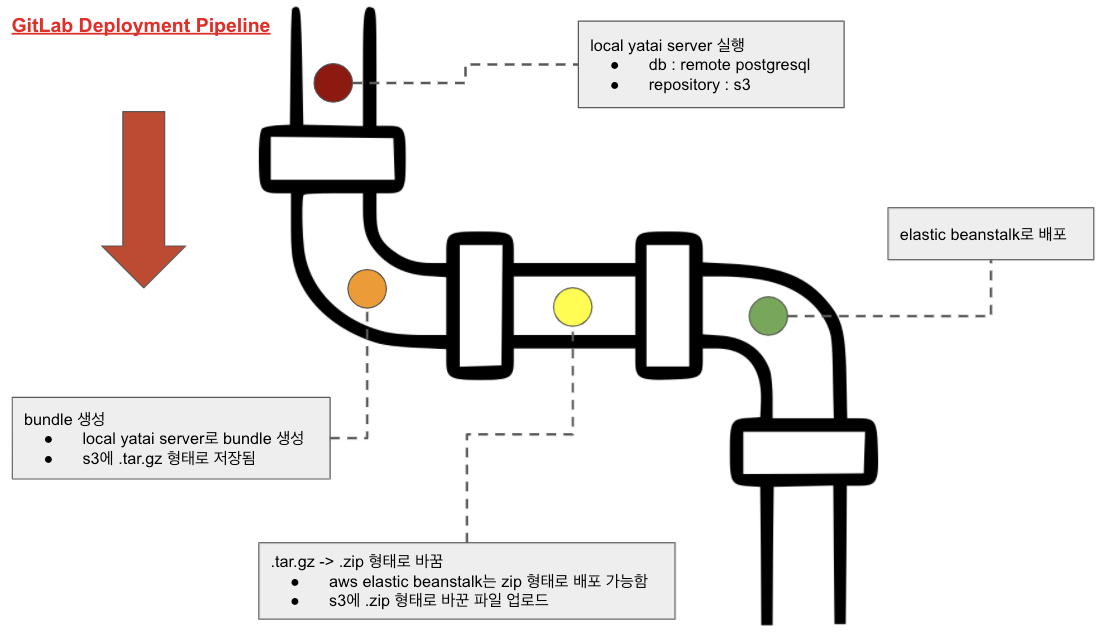
- 서버 환경은 API 서버 + Yatai 서버로 구성됩니다. 둘은 물리적으로 다른 서버에 구성했습니다.
- Yatai 서버는 배포 파이프라인에서 실행시키는 Local Yatai Server와 같은 PostgreSQL 서버, AWS S3를 사용하여 배포 정보를 지속적으로 확인할 수 있도록 합니다.
- AWS Elastic Beanstalk에 배포하는 형태는 Dockerfile이 포함된 .zip 파일 형태로 배포합니다.
Reference
