Next.js
Search Engine Optimization
What is SEO?
SEO의 목적은 검색 엔진 결과에서 웹사이트의 순위를 높이는 전략 수립하는 것이다.
What you'll learn in this course
- Search Systems 와 search engine robots (Googlebot)
- SEO 전략이 웹사이트에 가져오게될 효과
- SEO 모범 사례를 적용하는 방법
- Crawling, indexing, rendering, ranking 에 대하여
- Core Web Vitals과 웹 퍼포먼스에 대하여
Why is SEO so important?
높은 검색 순위는 유효 방문자들의 유입을 증가시킬 것이다.
SEM
SEO와 SEM은 다르다. SEM은 검색 결과 상단에 웹사이트가 위치하기 위해 돈을 지불하여 마케팅하는 방식이다.
3 Pillars of Optimization
웹사이트 최적화에 대해서 아래와 같이 3가지 정도로 나누어 볼 수 있다.
1. Technical - crawling과 performance를 위한 웹사이트 최적화
2. Creation - 특정 키워드 타겟팅을 위한 컨텐츠 전략 수립
3. Popularity - 검색엔진이 웹사이트를 신뢰할 수 있도록 사이트 인지도를 개선한다. 외부사이트에서 링크되어진 backlink들로 인한 인기도 상승
SEO 분야는 광범위하고 많은 측면들을 가지고 있지만, Next.js 개발자로서 거칠 첫번째 단계는 모범사례들을 통하여 웹앱을 SEO 준비 상태로 만드는 방법을 이해하는 것이다.
Search Systems
Search System은 Search Engine이라고도 불린다. 거대한 문제를 해결하는 복잡하고 거대한 시스템이다.
검색엔진의 4가지 주요 업무
1. Crawling - 모든 웹사이트들의 컨텐츠들을 파싱하고 접근하는 과정. 3500만 개가 넘는 도메인들이 있기 때문에 매우 큰 작업이다.
2. Indexing - crawling 단계에서 모아진 모든 데이터들에 접근 가능하도록 모아진 데이터들을 저장할 공간을 찾는다.
3. Rendering - 사이트의 콘텐츠를 풍부하게하고 기능을 향상시키는 자바스크립트 리소스들을 실행한다. 이 과정은 크롤링되는 모든 페이지에서 일어나지는 않는다. 가끔 이 과정은 콘텐츠가 index되기 전에 일어난다. 만약 인덱싱 이전에 수행될 작업이 없다면 렌더링은 indexing 되고 난 후 일어난다.
4. Ranking - 사용자 입력 기반으로 관련 결과 페이지를 만들기 위해 데이터를 쿼리한다. 검색엔진에 다양한 순위 기준이 적용되어 사용자 의도에 알맞은 최선의 답변을 제공한다.
What are Web Crawlers?
웹사이트가 검색 결과에 보이기 위해 구글은 웹 크롤러를 사용해 웹사이트들, 웹페이지들을 탐색한다.
각각의 검색엔진들은 나라마다 다른 시장 점유율을 가지고 있다. 하지만 구글이 대부분의 나라들에서 가장 큰 검색엔진이다. 그렇기 때문에 그들의 가이드라인을 살펴보는 것이 좋다.
검색엔진들은 서로 Ranking과 Rendering 측면에서는 다른점들이 있는데, 대부분의 경우 Crawling과 Indexing애서는 매우 비슷하다.
웹 크롤러는 사용자를 모방하여 링크들을 탐색하면서 페이지들을 인덱싱한다. 웹크롤러들은 커스텀 user-agent들로 식별될 수 있다. 가장 많이 사용되는 웹크롤러 커스텀 user-agent는 Googlebot Desktop, Googlebot Smartphone이다.
How does Googlebot Work?
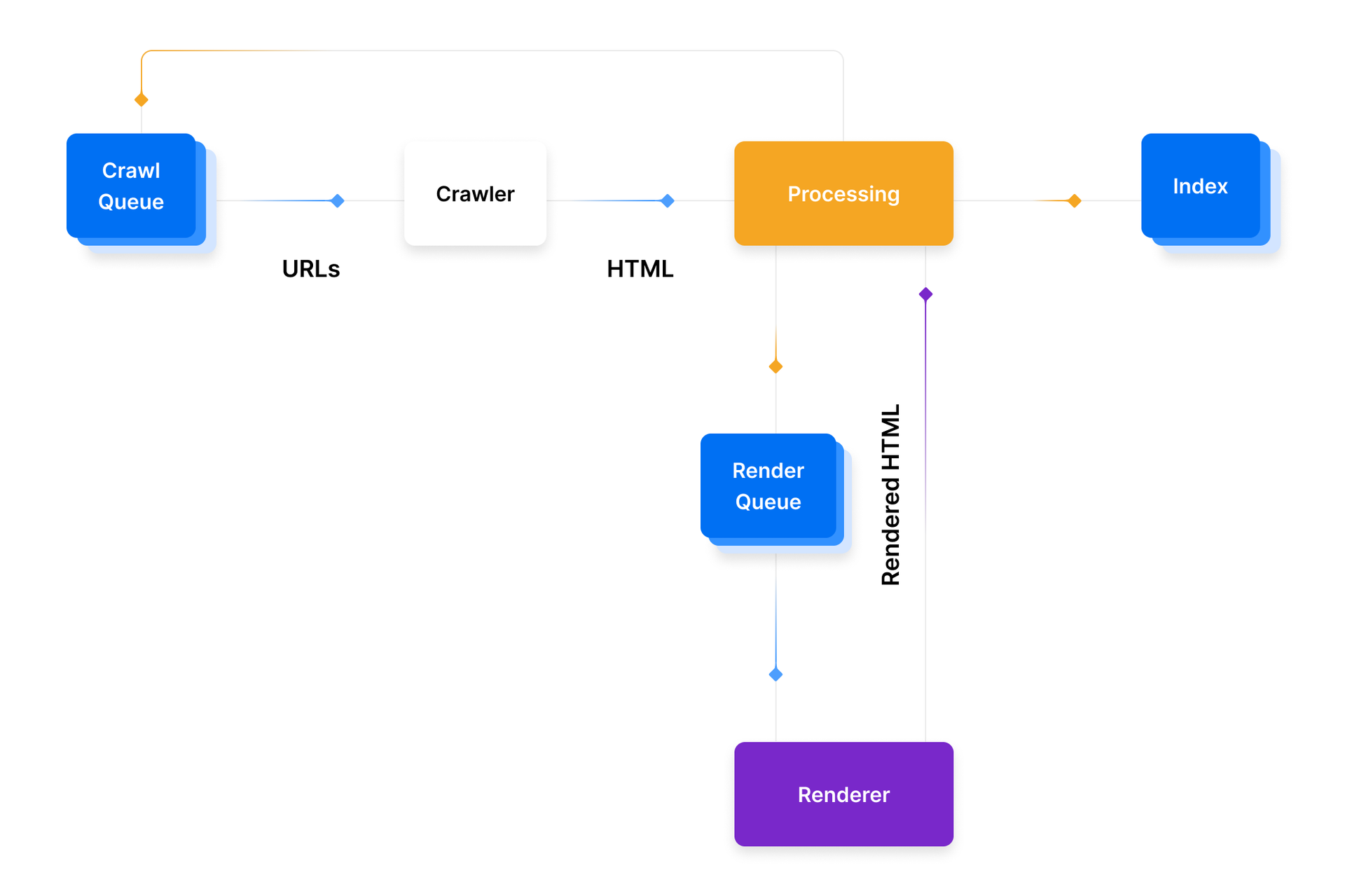
1. Find URLs: Google은 다양한 곳으로부터 URL들을 가져온다. (Google Search Console, 웹사이트들 간의 링크, XML sitemaps)
2. Add to Crawl Queue: 찾은 URL들은 구글봇이 이후 처리하기 위해 Crawl Queue에 담겨진다. 담긴 URL들은 보통 몇초간 머물지만 경우에 따라서 페이지가 렌더링되어야하거나 인덱싱되야하거나 이미 인덱싱되어있어서 새로고침되어야 하면 몇일간 머물러있기도한다. 이후 페이지들은 Render Queue로 들어간다.
3. HTTP Request: 크롤러가 status code에 따라 헤더와 액션을 받기 위해 HTTP 요청을 보낸다.
200- 크롤링되고 HTML을 파싱한다30X- 리다이렉트를 따라간다40X- 에러를 알리고 HTML을 로드하지 않는다50X- 후에 돌아와 status code가 변경되었는지 확인한다
- Render Queue: 검색 시스템이 각 서비스, 컴포넌트들의 HTML, 컨텐츠를 파싱 할 때, 만약 클라인트 사이드 자바스크립트를 가지고있다면 URL들은 Render Queue에 추가된다. Render Queue는 자바스크립트를 렌더링하기 때문에 추가적인 비용이 든다. 몇몇 검색 엔진들은 render 트리의 공간을 구글만큼 가지고있지 않기 때문에 이것을 Next.js를 사용해 도와 줄 수 있다.
- Ready to be indexed: 만약 모든 기준이 맞았다면, 페이지들은 인덱싱 되어 검색 결과에 보여질 자격을 갖추게 된다.
