AI 모델링 해석
설명이 잘되는 알고리즘 대체로 성능이 낮다.
성능이 좋은것이 항상 최우선
성능이 낮다면 모델링 해석도 의미가 없다.
1. Feature Importance
1-1. FI
- Tree based Model (Decision Tree, Random Forest, XGB)
- DT (gain)
- RF(total)
- 변수 중요도를 계산하는 3가지 방법
- weight : 해당 feature가 split될때 사용된 횟수의 합, plot_importance 기본값
- gain : feature별 평균 information gain, model.featureimportances 기본값
- cover : feature가 split할때 샘플 수의 평균
1-2. PFI(permutation feature importance)
- 모든 알고리즘 가능
- permutation(순열) -> feature 하나의 데이터를 무작위로 섞을때 model의 score가 얼마나 감소하는지 계산 -> 즉 차이가 클수록 중요한 feature
- 다중공선성 고려 -> 관계가 있는 변수가 존재시 score가 별로 줄어들지 않음
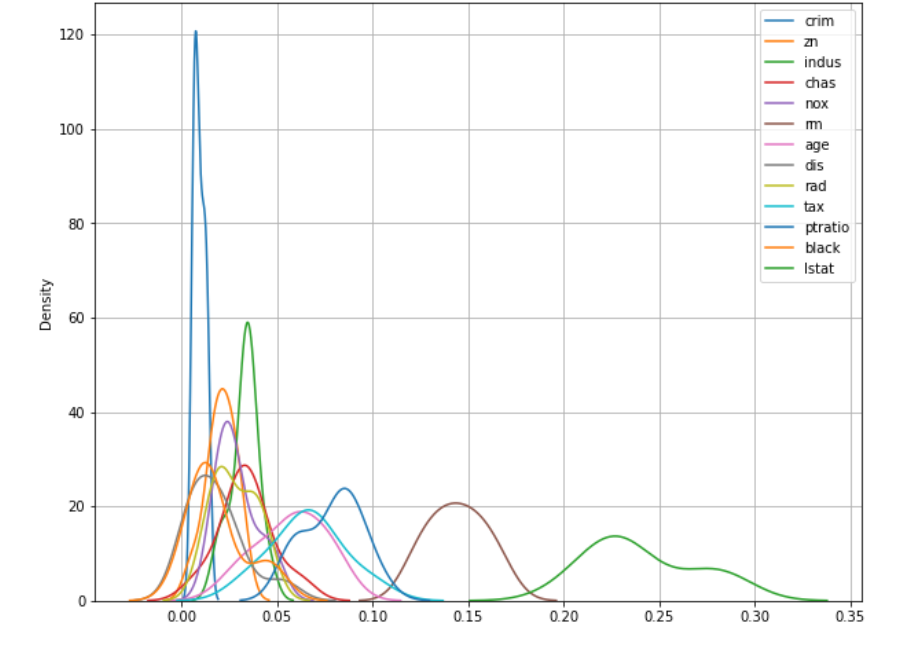 ->해석 : lstat가 가장 높은 성능, rm이 2번째
->해석 : lstat가 가장 높은 성능, rm이 2번째
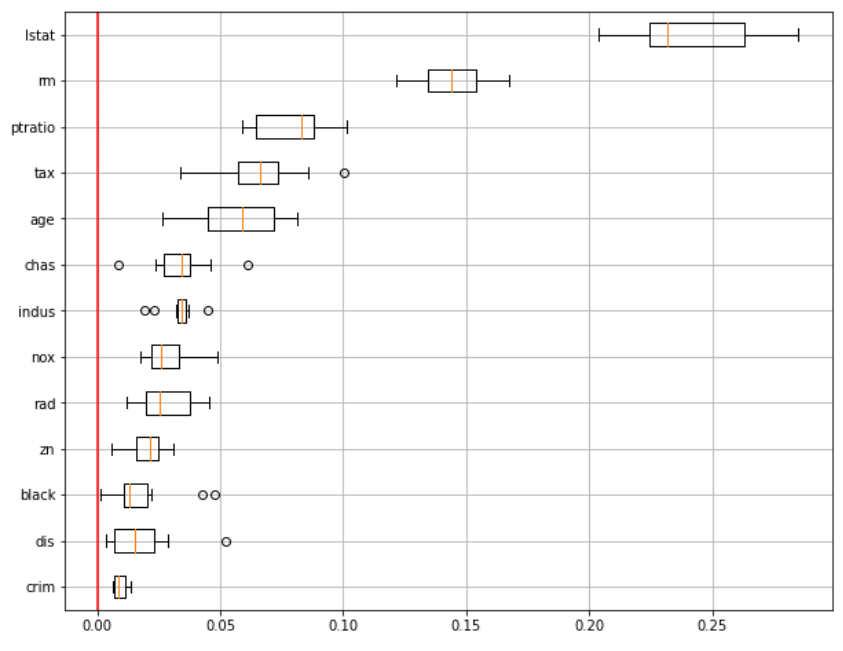 -> 0 을 기준으로 lstat의 분포, crim이 제일 낮음
-> 0 을 기준으로 lstat의 분포, crim이 제일 낮음
2. PDP(Partial Dependence Plots) (중요 feature -> 예측값 변화)
-
관심 feature의 값이 변할때 모델에 미치는 영향을 시각화
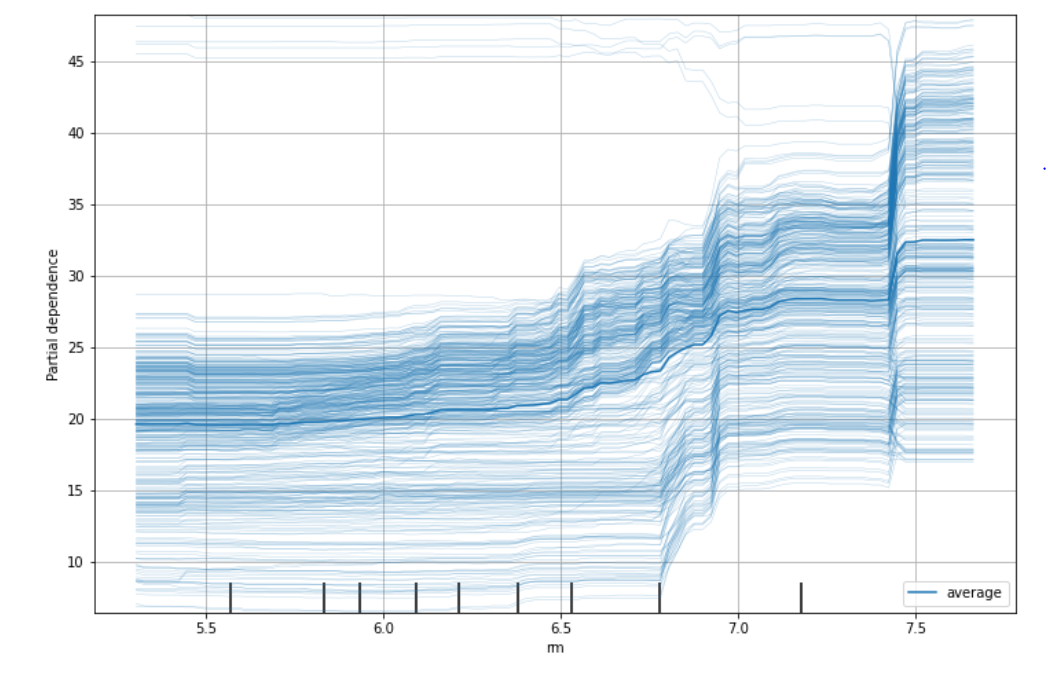 -> 모든 데이터에 대해서 rm이 6.7 ~ 7.0 집값이 급격히 상승하는 구간
-> 모든 데이터에 대해서 rm이 6.7 ~ 7.0 집값이 급격히 상승하는 구간
-
두 feature와 예측 결과와의 관계 (확률로 보여줌)
 -> 정상 대출 상황하고 기간이 짧을 수록 확률이 높다.
-> 정상 대출 상황하고 기간이 짧을 수록 확률이 높다.
3. SHAP(shapley additive explanations) (특정 feature)
- 결과에 대한 근거 제시 요구
- 변수 개수로 가중치 계산
- shapley value : 모든 가능한 조합에서 하나의 feature에 대한 평균 기여도 계산
- 전체 평균을 중심으로 예측된 값에 어떠한 영향을 주었는지 변수별 확인 가능, 하락요인, 상승요인 확인 가능

| 알고리즘 | shap | 주의사항 |
|---|---|---|
| Tree 기반 알고리즘 | TreeExplainer | shap.KernelExplainer(모델) |
| Deep learning | DeepExplainer | 리스트안에 np.array값이 저장 -> 값을 뽑아서 사용, shap_values = shap_values[0] |
| svm | KernelExplainer | shap.KernelExplainer(모델.predict, x_train_s) |
| knn | KernelExplainer | shap.KernelExplainer(model2.predict.proba, x_train_s) |
| other | Explainer |

소프트웨어 엔지니어