자연어처리 요소 기술
1) NLP(Natural Language Processing)
- computer science + Linguistics + Artificial Intelligence
- 언어를 처리하고 이용하는 연구 분야
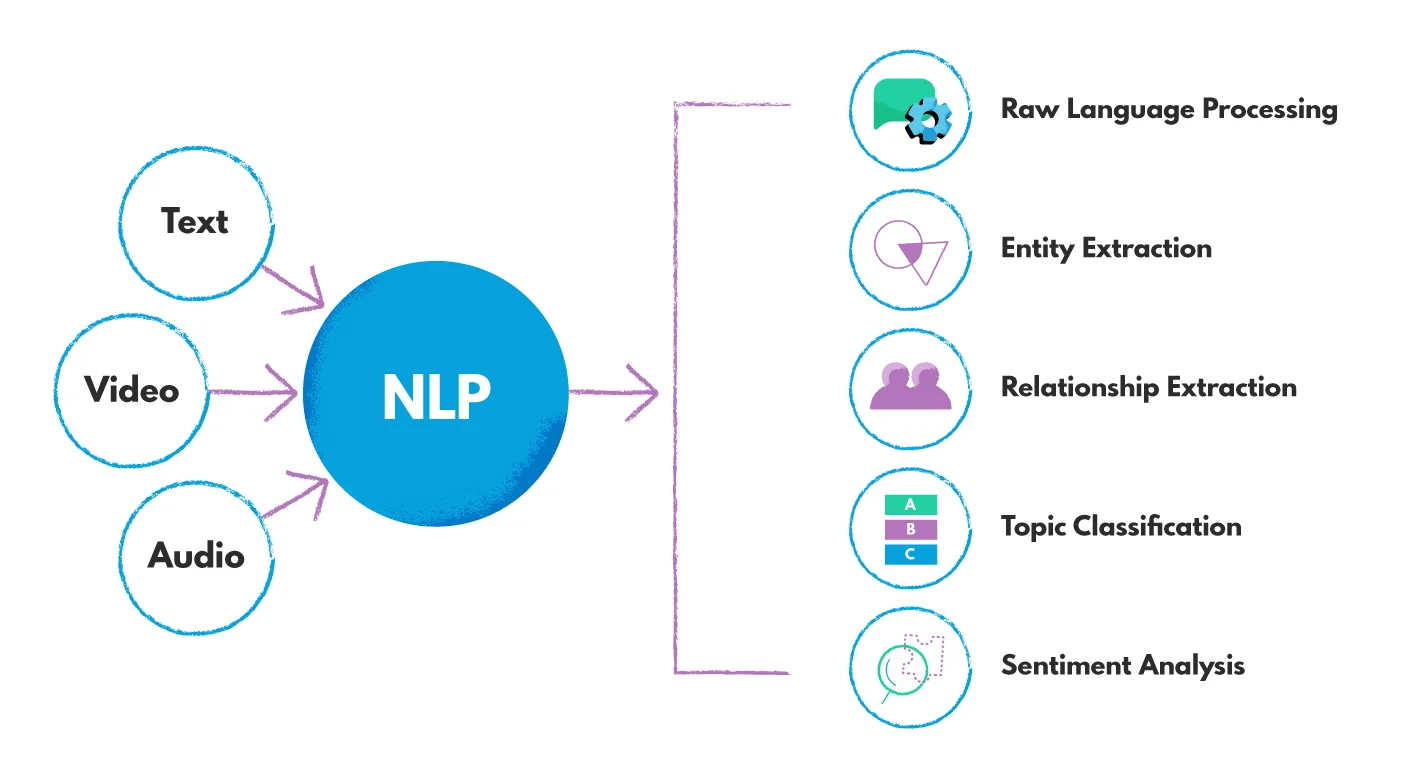
- input : 음성, 텍스트
- 활용 분야 : 정보검색, 기계번역, 챗봇, 텍스트마이닝
2) NLP 요소기술
1. 한국어의 품사
- 품사 : 단어를 문법적 성질에 따라 분류함
2. 형태소 분석
- 한 어절 내에 있는 모든 형태소를 분리
ex) 나는 : 나(대명사) + 는(조사) / 날다(동사) + 는(어미) / 나다(동사) + 는(어미)
형태소 분석의 모호성
- 동일한 표층형 어절이 여러가지 형태소 결합으로 분석 가능한 문제
3. 품사 태깅
- 형태소 분석의 기준이 되는 세분화된 품사 체계
- 형태소 분석의 모호성을 해결
- 통계 기법에 의한 해결 -> 대량의 품사 태깅 된 말뭉치 구축
3.1 Hidden Markov Model(HMM) 기반 품사 태깅
- 대량의 품사 태깅된 말뭉치 기반의 통계적 기법
- 가까운 품사만 참고
3) NLP 전처리
- 스팸 필터링
- 욕설/비속어 필터링
- 중복 문서 제거
- 맞춤법 교정
- 축약어 처리
4) 규칙 패턴 기반 자연어 처리
1.개체명 인식(NER)
- 누가 무엇을 언제 어디서 얼마나 에 대한 정보
1.1 BIO 태깅
- 개체명 태깅 기법
2. 구문 분석
- 언어별 문법과 lexicon(품사 속성 사전)에 기반하여 문장의 구문 구조 분석
- tree로 표현
3. 패턴매칭
4. corpus
- 말뭉치
- 언어의 표본을 추출한 집합
5) 기계학습 기반 자연어 처리
- 대부분의 자언처리 문제들은 분류 문제로 해결 가능
ex) 띄어쓰기 -> 이진분류 / 개체명 인식 -> 다중분류
6) 문서 벡터화
1. Bag of words
- 문서를 단어의 집합으로 간주
- 출현 빈도에 따른 가중치 부여
2. Term Extraction
- 문서를 term 단위로 분해
ex) n-gram
3. stop word List
- 쓸모없는 단어 제외
- 대부분의 문장에 자주 등장하는 고빈도 단어들
4. Document Transformation
Term Frequency Vector
- Out of Vocabulary term 제거
- 각 문서내 frequency count (TF)
5. Document Weighting
- 가중치 벡터로 문서 표현
- TF or TF*IDF
- 모델에 따라서 부여되는 가중치가 달라짐
TF-IDF 값
- TF와 IDF를 결합하여 각 용어의 가중치 계산
- 문서 D에 나타난 용어 t에 부여되는 가중치

소프트웨어 엔지니어