핵심개념
Supervised learning - input(데이터), target(정답)이 포함된 데이터로 학습
Unsupervised learning - input(데이터)만 사용, 데이터를 잘 파악함
Numpy - 파이썬의 대표적인 배열 라이브러리, 고차원 리스트 표현 가능
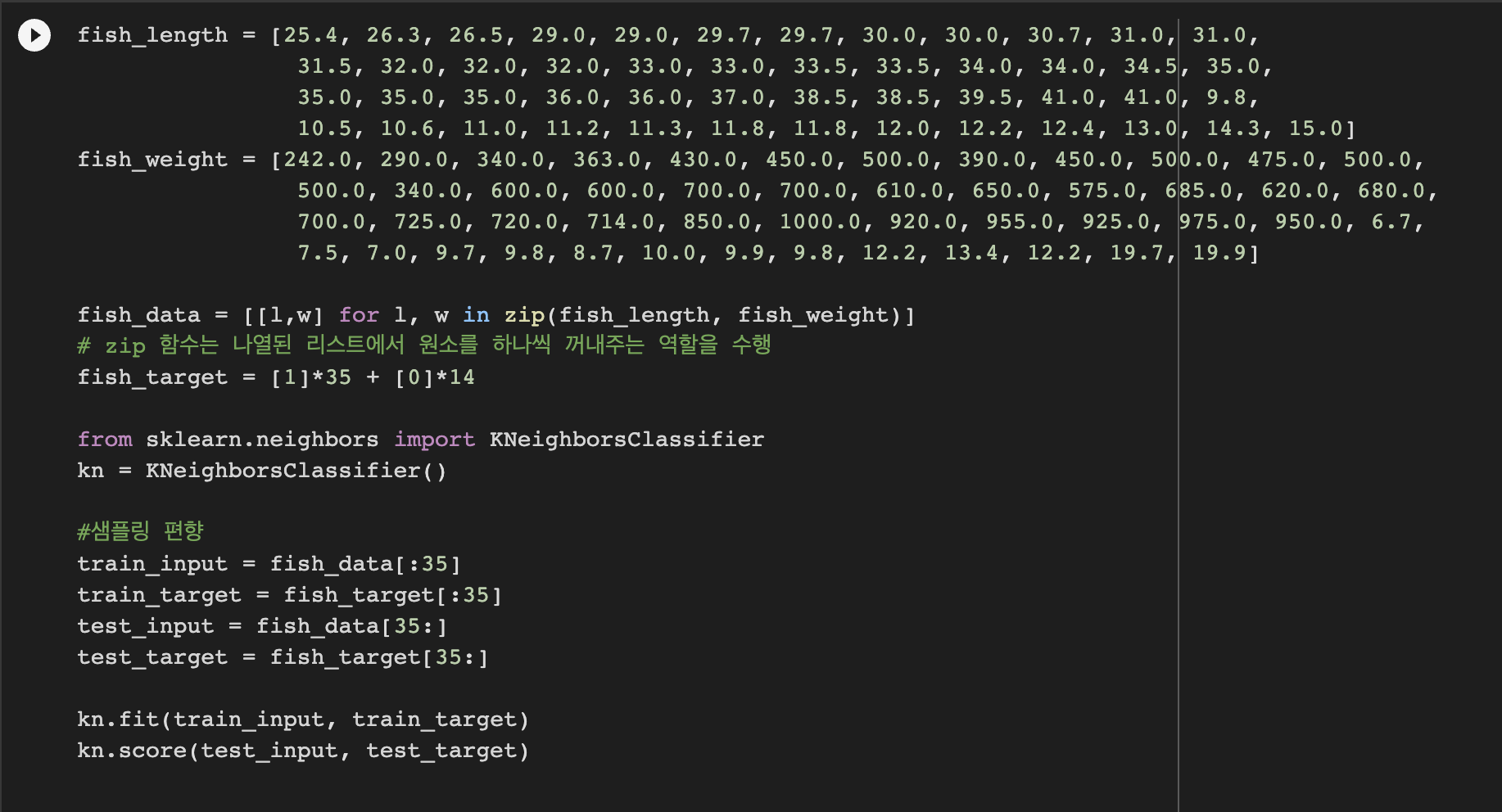
-> train에 쓰인 데이터와 test에 쓰인 데이터가 섞이지 않아서, 샘플링 편향 발생
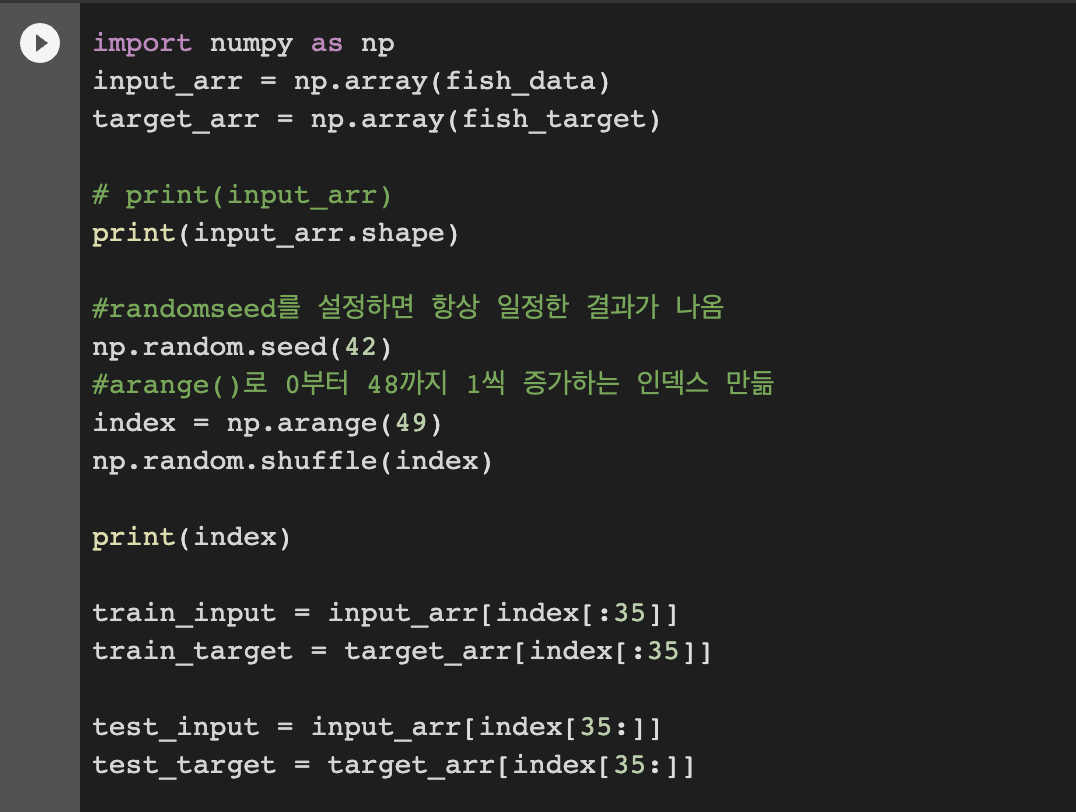
-> 그래서 골고루 잘 섞어줌! arange, shuffle 함수 이용
-> train에 쓰이는 데이터와 test에 사용할 데이터 분리
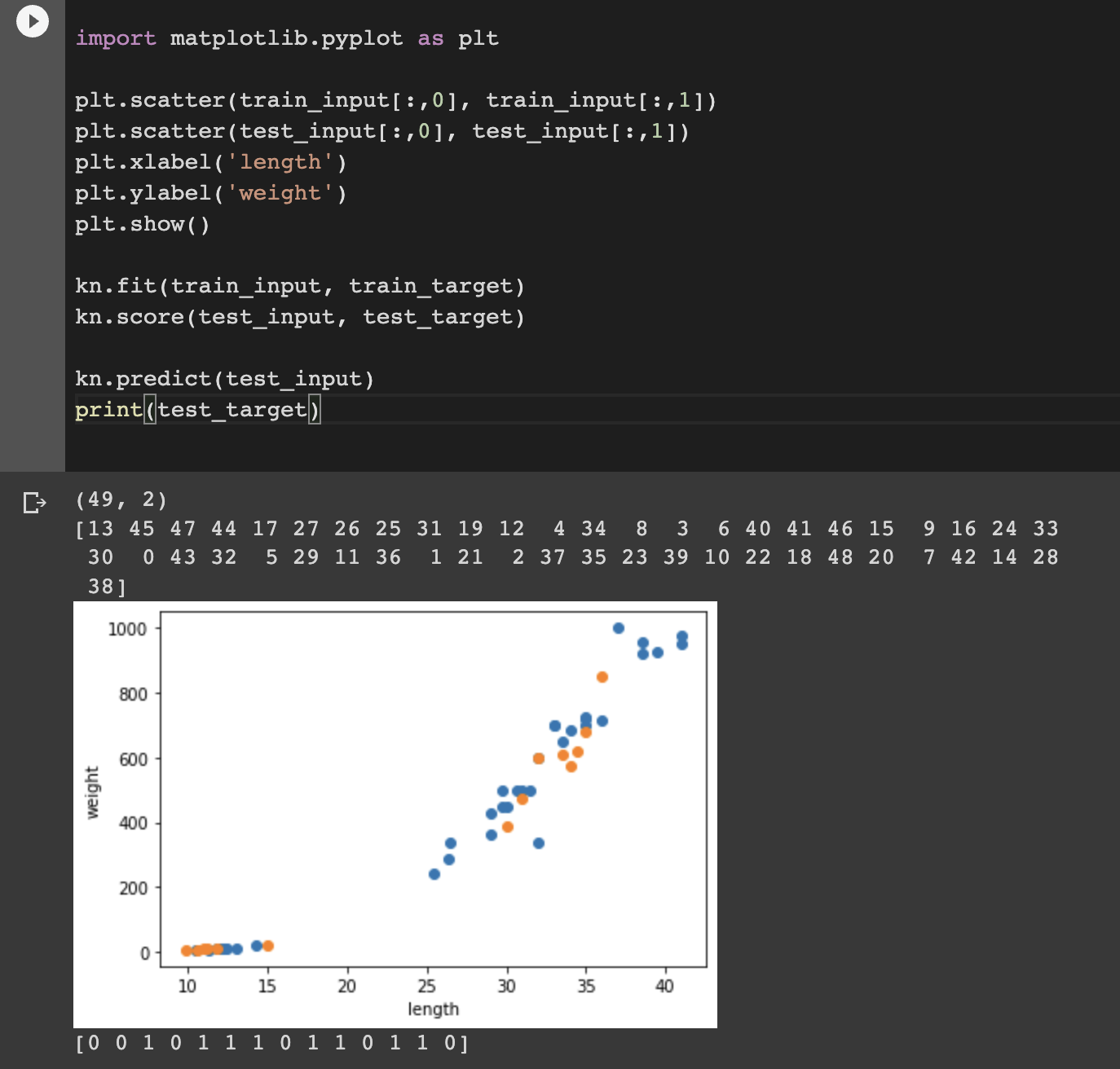
-> 파란색이 훈련 세트, 주황색이 테스트 세트 : 잘 섞임!
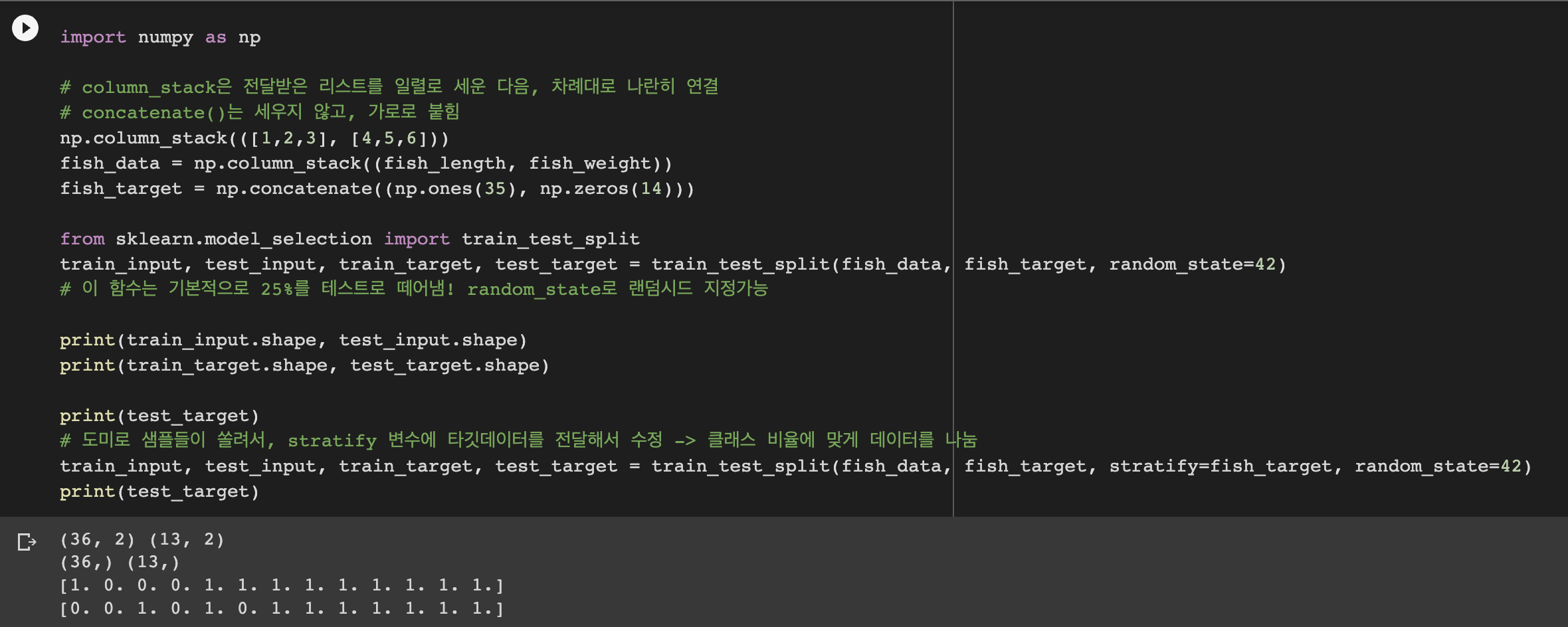
-> train_test_split 함수 이용해서 훈련/테스트 세트 자동으로 분리
-> statify 변수에 타깃데이터 전달해주면, 클래스 비율에 맞게 데이터를 나눠줌
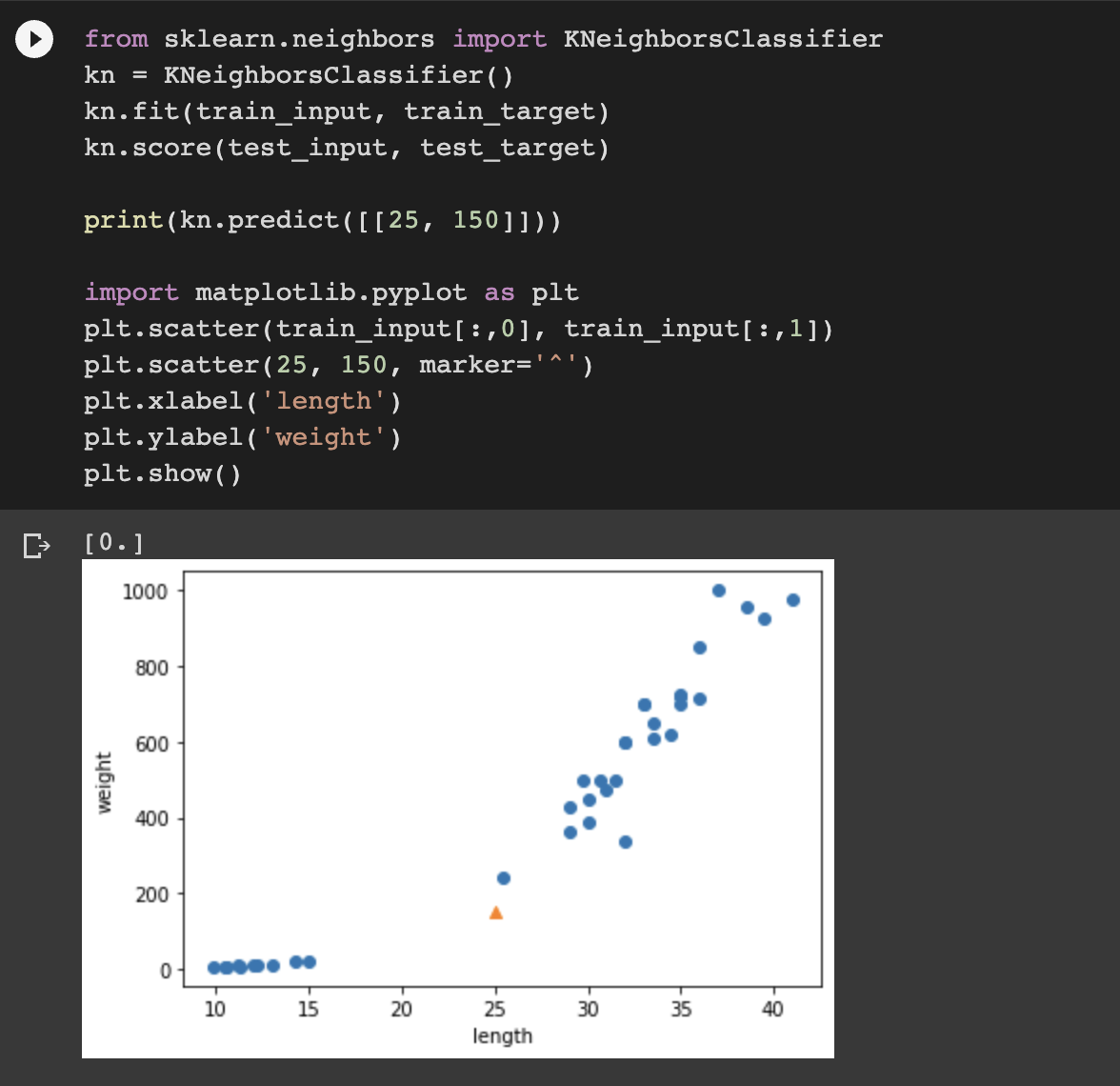
-> 도미에 가깝지만, 결과가 빙어로 나옴 Why?
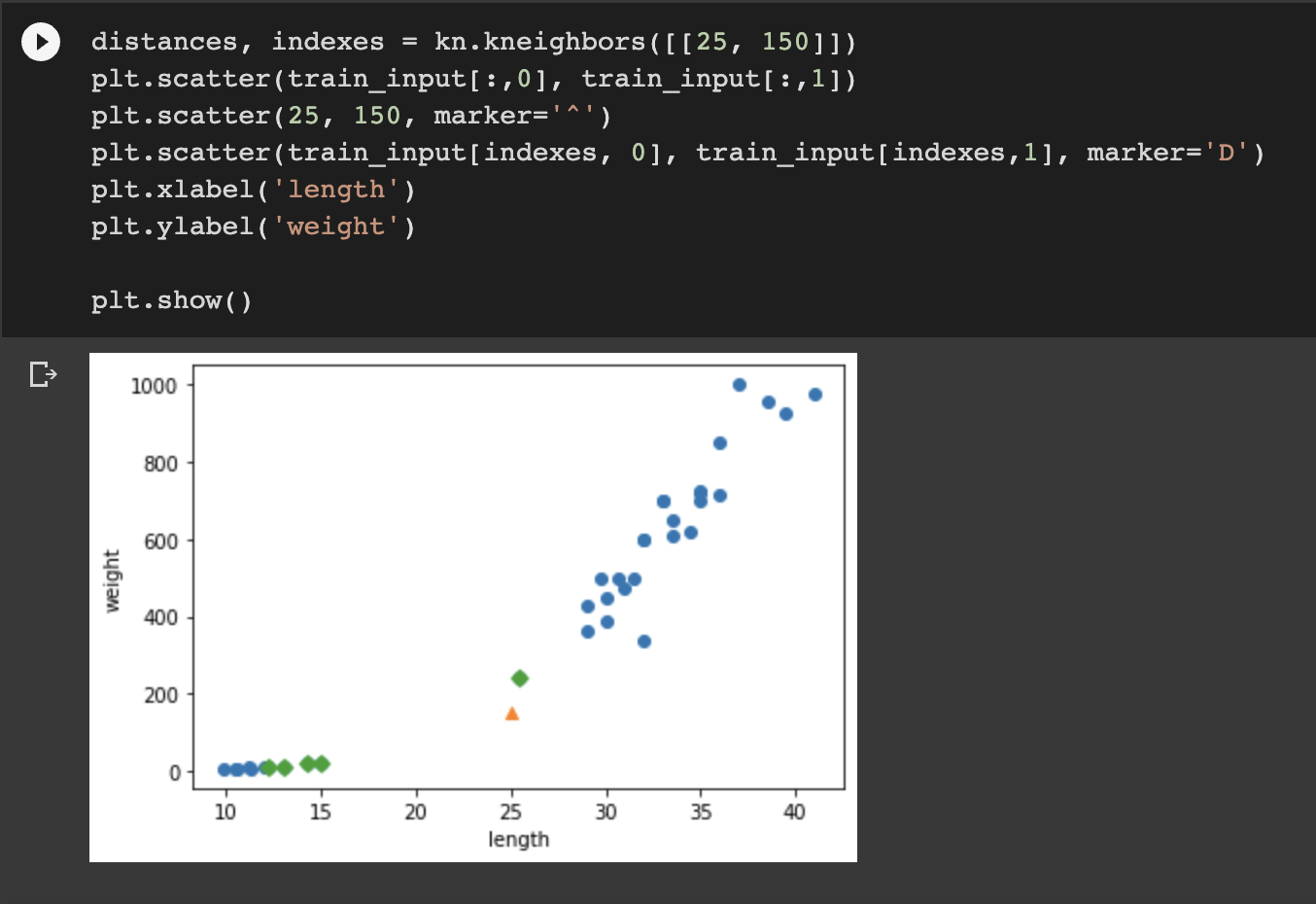
-> 거리상 가까운 5개의 점 중 4개가 빙어이기 때문!
-> 이 문제를 해결해줘야, 도미로 분류되겠죠?
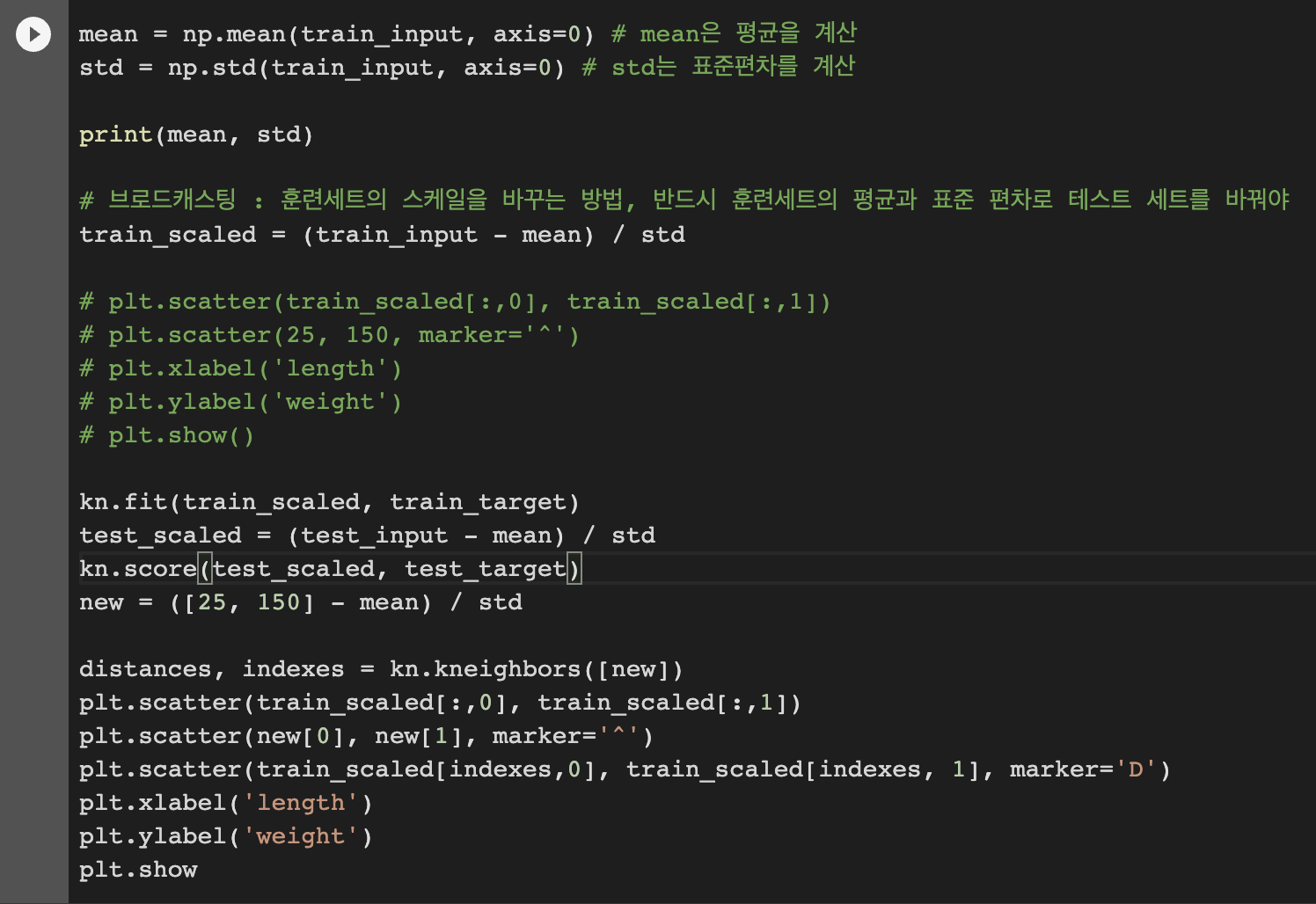
-> 브로드캐스팅 방식을 통해 훈련세트의 평균과 표준편차를 이용해 테스트 세트의 스케일 바꿔줌!
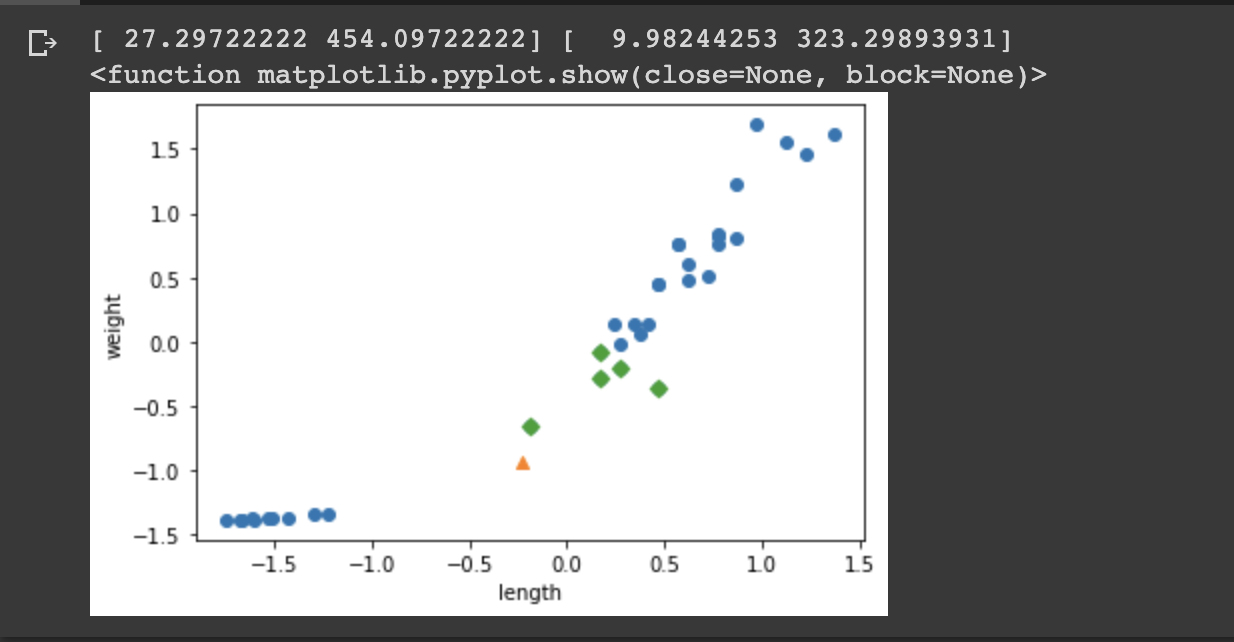
-> 최종 결과를 살펴보면, 가장 가까운 5개의 점 모두 도미인 것을 확인 가능!
참고자료
https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/2-1.ipynb
https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/2-2.ipynb
