💡 (Apache) Hadoop : High-Availability Distributed Object-Oriented Platform의 약자
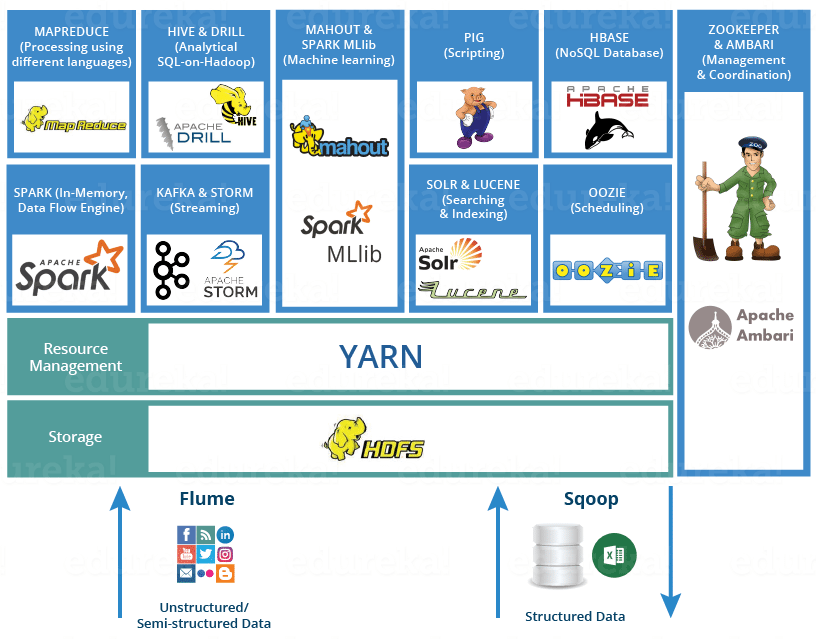
Apache(아파치) 재단에서 관리하는 프리웨어인 Hadoop Project에서 만들어지는 모든 소프트웨어 솔루션들의 집합을 얘기한다.
Hadoop은 HDFS라는 파일처리 시스템과 YARN이라는 리소스 관리 시스템, MapReduce라는 대용량 처리 시스템을 기반으로 하는 프레임워크다.
대용량 데이터를 효과적으로 처리하는 것을 목적으로 하는 많은 소프트웨어들이 함께 있는 플랫폼으로 많은 기업이 활용하고 있다.
HDFS (Hadoop Distributed File System)
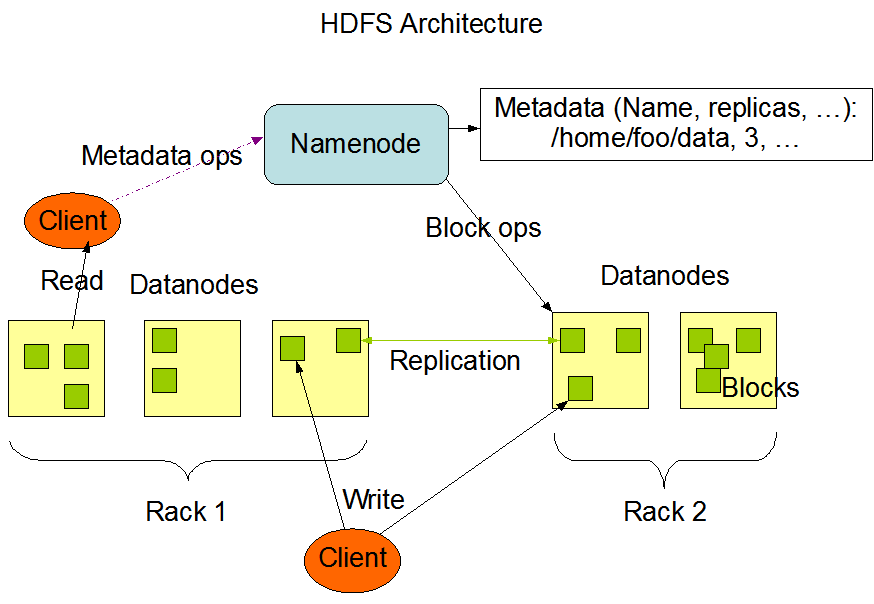
- Hadoop에서 관리하는 모든 데이터를 저장/관리하는 시스템 (스토리지 관리)
Namenode와Datanode로 데이터를 분산관리node: 컴퓨터 한 대
rack: Node 여러 대를 물리적으로 묶어놓은 것. 같은 네트워크 스위치를 공유
cluster: 여러 rack을 물리적으로 묶은 것- Namenode는 실제 데이터가 어떤 Datanode에 저장되어 있는지를 관리하는 메타데이터를 관리하는 노드이다.
- Datanode엔 실제 데이터가 분산 저장된다. (replica들이 존재함)
YARN (Yet Another Resource Negotiator)
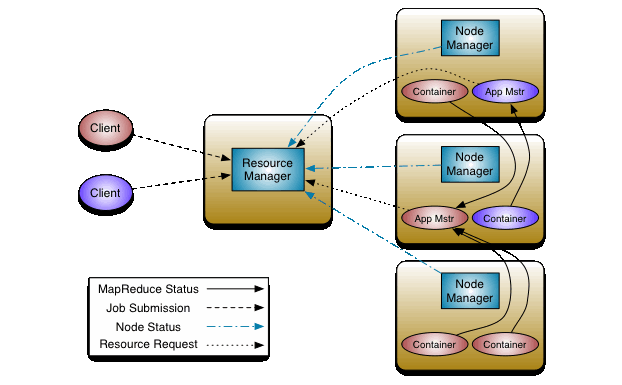
- Hadoop에서 처리되는 모든 리소스를 관리해주는 시스템
- 어떤 요청이 어떤 클러스터에 할당되어야 하는지 관리
Resource Manager와Node Manager가 리소스를 관리- Resource Manager는 각 Node Manager가 각 Node의 리소스를 얼마나 사용하는지를 관리한다.
- Node Manager는 각 Node를 관리하며, Node의 리소스를 관리한다. Resource Manager의 요청을 수행하는 역할
- Client가 작업을 요청하면 Resource Manager가 Node Manager들을 관리하여 리소스를 할당하고, 작업을 수행한다.
MapReduce
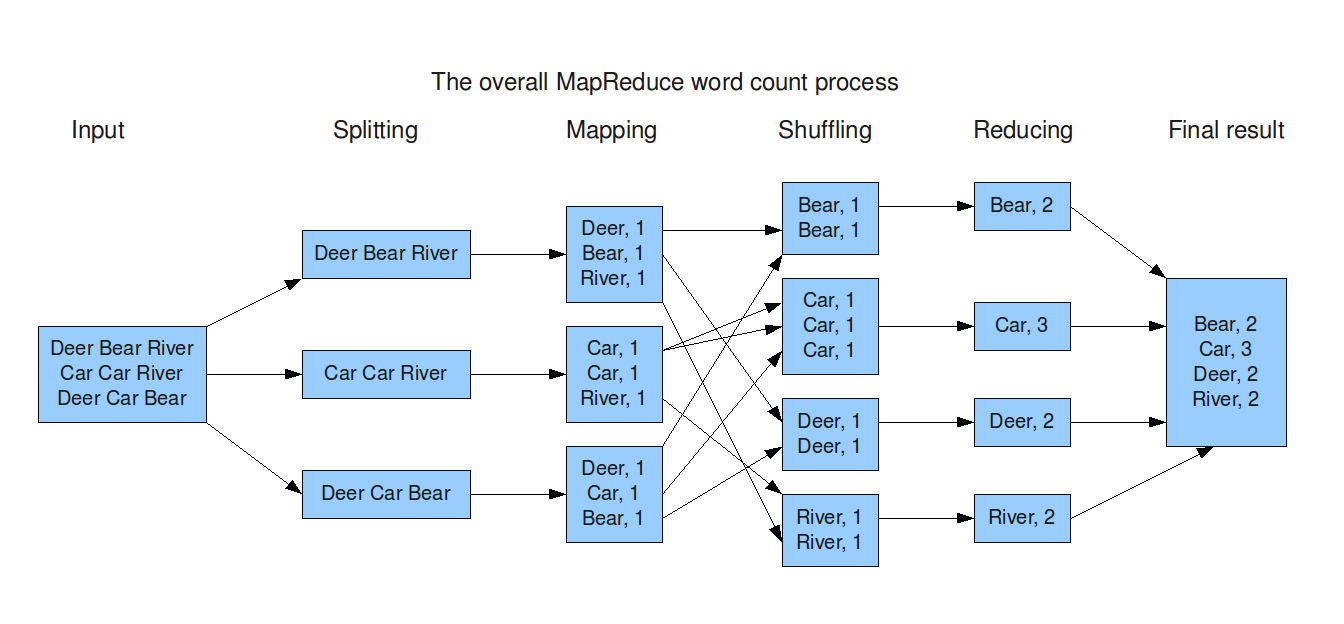
- Hadoop에서 데이터를 분산처리하는 방법 중 하나
Maptask와Reducetask가 존재- Map task를 수행하는 노드를
Mapper, Reduce task를 수행하는 노드를Reducer라고 한다. Suffling: Sort & Merge
Process
- 전처리기가 Mapper가 일을 할 수 있는 형태로 데이터를 정의하여 Mapper들에게 전달 (Preprocessing)
- Mapper는 처리해야 하는 데이터를 Reducer가 연산할 수 있는 형태로 변환 (Mapping)
- Reducer에게 전달하기 전에 데이터를 기준에 맞게 Sort & Merge (Shuffling)
- Reducer는 전달받은 데이터에 요청하는 연산을 수행 (Reducing = sum)
- Reducer들이 처리한 데이터를 합침
요약
- Hadoop Ecosystem은 대용량 데이터를 처리하는 프로그램의 플랫폼
- HDFS, YARN, MapReduce 핵심 컨셉에 따라 실제 데이터를 처리
- Hadoop Ecosystem에 있는 구성 프로그램들은 모두 오픈소스며, 대용량 데이터 처리를 위해서 기능별로 구현

데이터 사이언티스트를 꿈꾸는 3년차 제품총괄입니다.