참고: https://www.youtube.com/watch?v=o_peo6U7IRM&list=PLCsGBQ3i2iIWOssGekIwgic0DxmDA9-ya
KeyWord
Auto encoder
VAE
GAN
MSE
KL-Divergence
Manifold
Latent
probability
Likelihood
인공지능 역사를 잠깐 살펴보면
1969년
Marvin Minsky가 Perceptrons로 실제 문제를 해결 X, XOR 문제 해결 못함 주장 (인공지능 암흑기)
1974년
Paul webos박사과정 backpropagation의 활성, XOR해결 (인공지능 연구 부활 움직임)
1982년
John Hopfield "Neural networks and physical systems with emergent collective computational abilities"
상호결합형 신경망 모델로서 연상기억이나 최적화 문제를 병렬적으로 해결. 연상기억에서 미지의 입력패턴이 주어질 때 이와 가장 유사한 패턴을 찾아냄
(인공지능 연구 부활)
~2000년
인공지능 연구 전성기를 맞이 했을 때 Auto Encode라는 개념이 나옴.
인공지능이 부활하자 마자 나온 것이 Auto Encode임
Auto Encoder가 나온 이유??
딥러닝 연구에 있어서 여러 연구자들은
X를 넣었을 때 Y를 나오는 과정에 대한 의구심들이 있었음.
몇몇 사람들이 질문을 던짐
그러면 X를 넣었을 때 X가 나오게 해봐!
인공신경망이 정말로 제대로 작동하는지 검증한 것과 같다라는 생각이 들었음
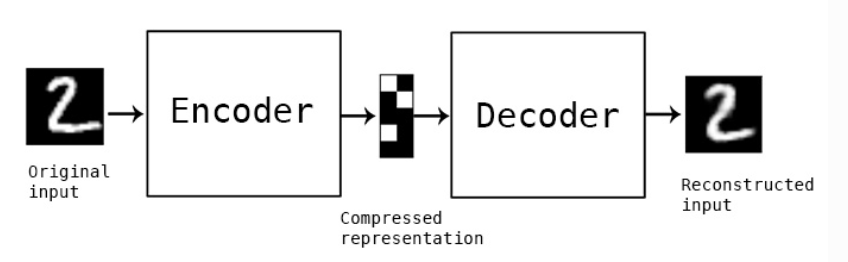
가운데에 있는 Compressed representation은 데이터를 압축하는 기능
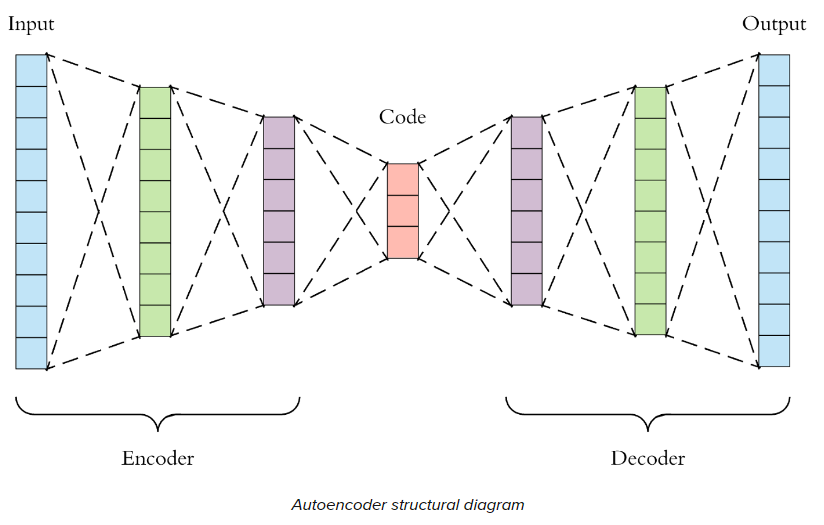
Code부분은 ManiFold, Latent, Feature라고 불림

차원 축소
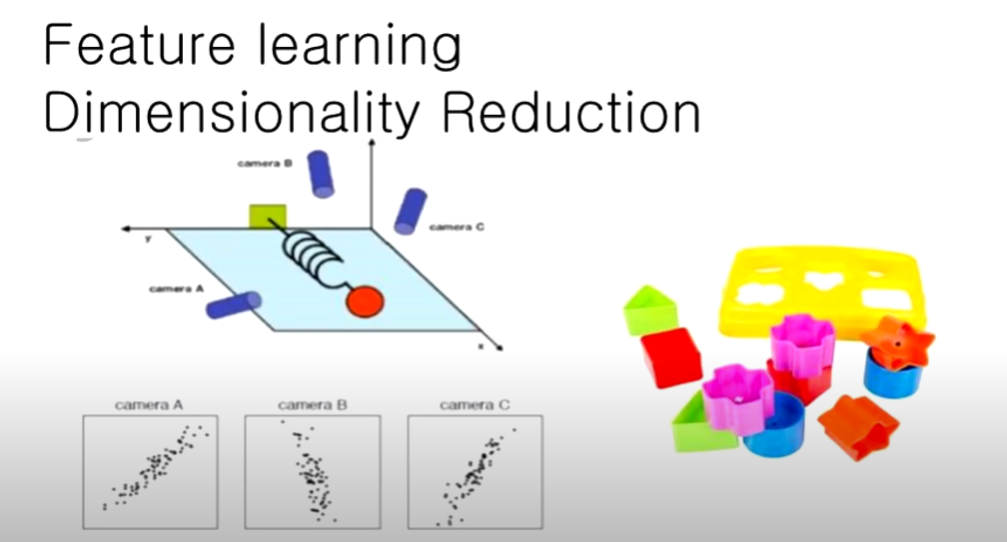
A시점, B시점, C시점에서 바라본 스프링의 움직임은 그래프에 나와 있듯이 직선으로 그려짐, 주의해야 할 것은 각 시점이 전체 움직임을 대변한다고 생각하면 안됨.
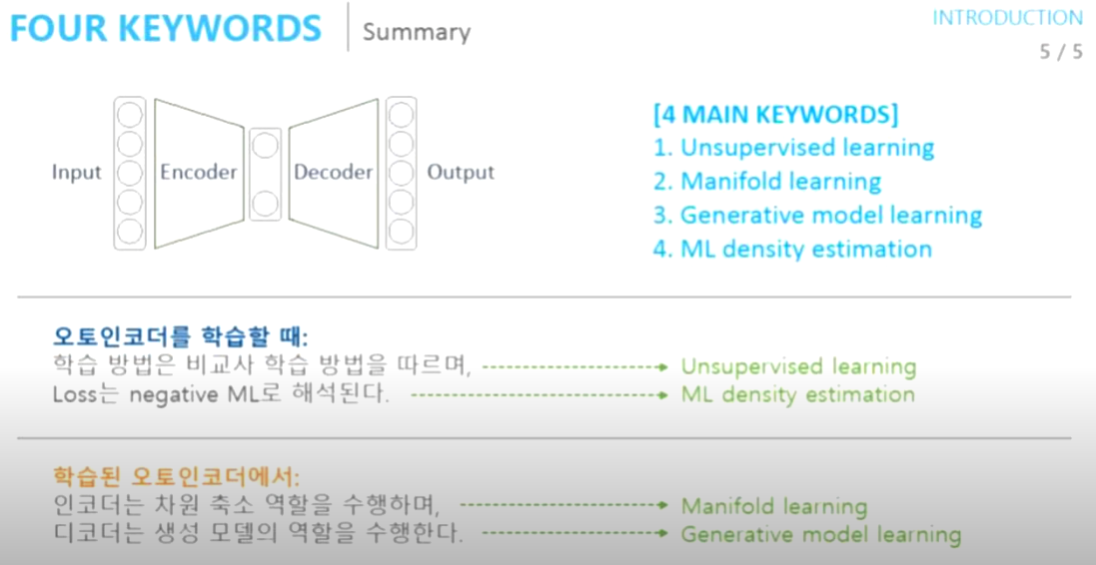
Unsupervised learning인 이유
X값을 넣어서 X가 나오니 labeling을 할 필요가 없음
Manifold가 많아 지면 오히려 성능이 떨어졌다.
-> 차원의 저주
X가 들어가서 X가 나오는 걸 어떻게 맞출까?
핵심 요약
X1이 들어가서 X1이 나오는 maximum Likelihood(최대우도)를 구하는 인공신경망을 만들어!
쉽게 말하면
X가 들어가서 X가 나올만한 신경망
Likelihood를 쓰는 이유는
주어진 모수값에서 관측된 데이터가 나타날 확률을 나타내는 것으로, 모수값을 예측하는 데 사용됩니다. 즉, 데이터는 이미 주어졌으며, 이를 이용하여 모수값을 추정하는 데 사용됩니다.
또한, code부분이 어떤 분포를 따를지 모르기 때문에 (변수이기에)
Probability를 쓰지 않는 이유는
확률은 주어진 사건이 발생할 확률을 나타내는 것으로, 이미 발생한 사건에 대한 확률을 계산합니다. 즉, 데이터와 모수값이 모두 주어졌을 때, 이를 이용하여 예측하는 데 사용됩니다.
레이블이 주어지지 않았으니까

X가 들어가서 X가 가장 잘 나올 Likelihood로 신경망을 만들어보자

