Search
DFS
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
특징
- 자기 자신을 호출하는 순환 알고리즘의 형태 를 가지고 있다.
- 전위 순회(Pre-Order Traversals)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
- 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다. - DFS는 그래프(정점의 수: N, 간선의 수: E)의 모든 간선을 조회한다.
- 인접 리스트로 표현된 그래프: O(N+E)
- 인접 행렬로 표현된 그래프: O(N^2)
- 즉, 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
BFS
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 직관적이지 않은 면이 있다.
- BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다. - BFS는 재귀적으로 동작하지 않는다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
- 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다. - BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
- 즉, 선입선출(FIFO) 원칙으로 탐색
- 일반적으로 큐를 이용해서 반복적 형태로 구현하는 것이 가장 잘 동작한다. - 인접 리스트로 표현된 그래프: O(N+E)
- 인접 행렬로 표현된 그래프: O(N^2)
- 깊이 우선 탐색(DFS)과 마찬가지로 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
Binary Search
이진 탐색이란 데이터가 정렬돼 있는 배열에서 특정한 값을 찾아내는 알고리즘이다. 배열의 중간에 있는 임의의 값을 선택하여 찾고자 하는 값 X와 비교한다. X가 중간 값보다 작으면 중간 값을 기준으로 좌측의 데이터들을 대상으로, X가 중간값보다 크면 배열의 우측을 대상으로 다시 탐색한다. 동일한 방법으로 다시 중간의 값을 임의로 선택하고 비교한다. 해당 값을 찾을 때까지 이 과정을 반복한다.
시간 복잡도 : O(log N)
자세한 사항은 [[Graph, Tree]]를 확인 귿~
허프만 코드
데이터를 효율적으로 압축하는 데 사용하는 알고리즘으로, 그리디 알고리즘에 속함.\
데이터 빈도 수에 따라 우선순위 큐에서 작은 두 개의 노드를 꺼내고 이를 합쳐 트리를 만드는 과정이 있다.\
고정 길이 코드와 가변 길이 코드 두 가지 표현 방법이 존재함.
텍스트에서 문자가 출현하는 빈도수에 따라 다른 길이의 부호를 부여라는 핵심을 가지고 있다.
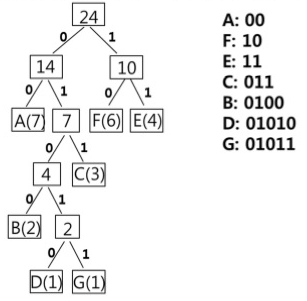
시간 복잡도 : O(N log N )
