🔥 사건의 발단
개발 중인 시스템이 타시스템에 통합되어 고객사에 세일즈되면서 시스템을 납품해야 하는 일이 생겼습니다. 그런데 고객사에서는 MongoDB를 사용하지 않으니, Oracle로 변경해야 하는 요구 사항이 있었습니다. 이처럼 당황스러운 요구 사항은 매번 신선한 충격을 주는 거 같습니다. (솔직한 마음으로는 “안돼 돌아가” 를 외치고 싶었습니다..🥲)

하지만 이미 세일즈 되었기에 현실적으로 리팩터링을 피할 수는 없었으며, 다른 고객사에서도 일어날 수 있는 이슈라고 생각했습니다. 이를 해결하기 위해 고민하던 중, Spring Data JPA의 Repository가 떠올랐습니다. Spring Data 모듈의 경우, spring-data-jpa / spring-data-mongodb / spring-data-elasticsearch 등을 통해 다양한 영속성 장치와 통신 하고 있습니다.
만약 시스템의 기능 역시 Spring Data 모듈처럼 동작한다면, 구현 기술에 영향 받지 않을 수 있다고 생각했습니다. 이를 통해 다양한 Infarstructure(Oracle, MySQL, Mongo)를 지원할 수 있으며, 도메인에 집중할 수 있습니다. 나아가 객체 지향 설계에서 추구하는 관심사 분리와도 연관 있다고 생각했습니다.
현재 개발중인 시스템을 프로젝트 실행 시, 설정 값에 따라 다양한 인프라스트럭쳐를 지원하는 것을 목표로 여정을 떠났습니다.
🤔 Repository Pattern이란?
2004년 Eric Evans의 Domain-Driven-Design 에서 처음 소개된 개념으로, 공통적인 데이터 Access & Manipluate 에 집중하여 도메인 모델 계층과 구현 기술을 분리시키는 것입니다. 구현 기술에 종속적이지 않기 때문에 도메인에 집중할 수 있다는 장점이 있으며, 꼭 영속성 장치가 아닌 파일 시스템, 웹 서버여도 상관 없습니다.
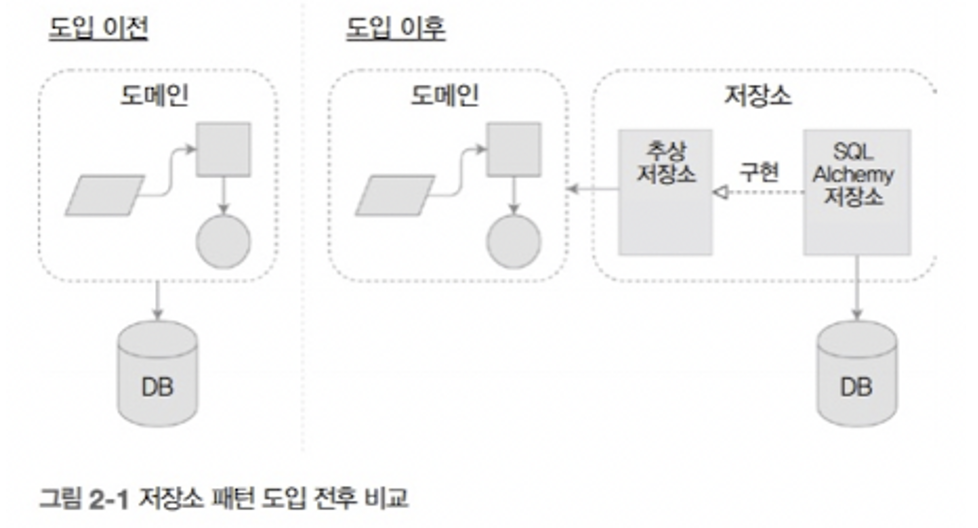
우리가 흔히 부르는 Repository는 Spring의 개념은 아니며, Java나 어떤 구현 기술에 종속적이 이야기도 아니라고 합니다. 코드 리팩터링의 저자이자 유명한 개발자인 마틴 파울러는 ‘레포지토리를 Domain과 Data Source Layer 간에 중재자 역할을 수행하는 것’ 이라고 말합니다.
따라서 Spring Data와 유사한 구조를 갖기 위해 Repository Pattern을 적용하기로 했습니다.
🗣 TMI
사실 Repository Pattern은 이전부터 알고 있던 디자인 패턴인데요. 실무에서 인프라가 바뀔 일이 없을 거라고 생각했는데, 그 상황이 저한데 올 줄은 꿈에도 몰랐습니다..🤮
👨🏻💻 DIP를 활용한 구현
DIP는 Dependency Inversion Principle의 약자로, 객체지향설계 5원칙(SOLID)에서 D에 해당하는 원칙입니다. 즉, DIP를 사용한다는 것의 의존성 방향을 역전시키겠다는 의미이며 고수준 모듈이 저수준 모듈에 의존하지 않도록 하기 위함입니다.
Domain Model 계층(고수준 모듈)과 Infrastructure 계층(저수준 모듈)을 분리하고, Infrastructure가 Domain을 의존하게 함으로써 하나의 추상적인 Repository에 대해서 다양한 구현이 가능하게 됩니다.
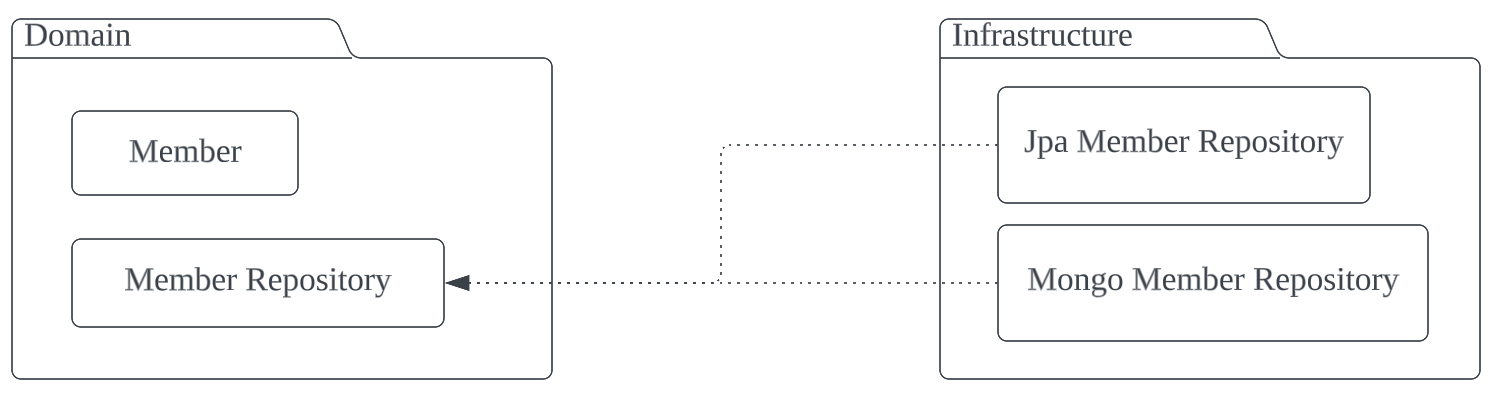
도메인의 관점에서 생각하면 Repository는 데이터 처리에 대한 명세를 추상화한 것으로 어떻게 Repository에 저장되는 지 관심을 갖지 않게 됩니다. 예를 들어, Infrastructure에서 이를 JPA를 사용하여 구현하던 MyBatis를 사용하던 중요하지 않습니다. 따라서 Domain 과 Infrastructure 는 코드 상에서 격리시켜 Loose Coupling(느슨한 결합)을 유지해야 합니다.
🚧 주의해야 할 점
동료들의 동의
프로젝트에서 가장 중요한 부분은 협업이기에 혼자 판단하여 아키텍처를 바꾸는 일은 바람직하지 않다고 생각합니다. 그래서 개인 레포지토리에 앞으로 시스템이 변경되는 구조의 프로젝트를 구현한 후 설명하는 자리를 가졌습니다.
Converting의 증가
구현 기술을 분리하게 된다면 Domain과 Infrastructure 간의 변환 코드들이 많아지는 것은 불가피합니다. 또한, Converting 과정에서는 JPA의 Lazy Loading의 이슈도 존재합니다. (DDD 관점에서는 Lazy Loading이 필요하다는 것은 Aggregate의 설계가 잘못되었을 가능성이 존재하다는 의견도 있다고 합니다.)
Converting 과정에서 코드의 양을 줄이기 위해서 Mapstruct 라이브러리를 사용했습니다. Mapstruct도 JPA의 Lazy Loading 관련 이슈가 있기 때문에, 해당 부분만 주의한다면 도입이 간단했습니다. Repository Pattern와 Mapstruct를 모두 사용하고 싶었는데 오히려 좋은 상황이었습니다.
🏁 마치며
작년 하반기에 다녀왔던 NHN 컨퍼런스에서도 클린 아키텍처는 ‘애매 그 잡채’ 라고 말했던 것이 기억이 납니다. 리팩터링을 진행하며 더 좋은 구조는 무엇일 지에 대해서 많은 고민을 했습니다. 저 역시도 고민에 대한 결과는 ‘애매 그 잡채’ 였습니다. 중요한 건 꺾이지 않는 마음처럼, 동료들과 더 좋은 아키텍처를 고민하고 공유하는 것이 Best Practice라고 생각합니다.
여행 끗-!
🙇🏻♂️ 출처
[DDD] Repository Pattern 이란, 이론편
https://github.com/paul-1455/career-rpp
천종호 판사 안돼 돌아가 > 짤투데이
[도서] 파이썬으로 살펴보는 아키텍처 패턴