
ELMo
- Learn parameters to combine the RNN output across all layers for each word in a sentence for a specific task(NER, semantic role labeling, question answering etc.). Large improvements over SOTA(State Of The Arts) for lots of NLP problems.
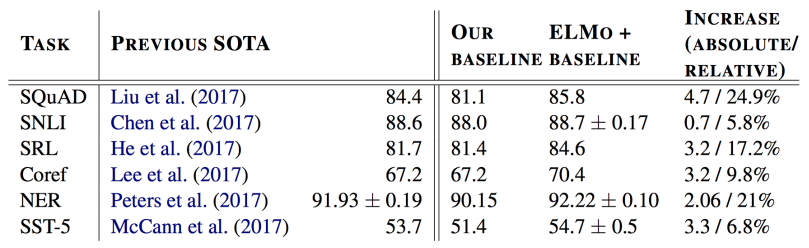
BERT
- Learn the parameters of this model with two objectives :
1) Masked language modeling
2) Next sentence prediction
-Masked LM
- Masked one word from the input and try to predict that word as the output
- More powerful than an RNN LM since it can reason about context on both sides of the word being predicted
- A BiRNN models context on both sides, but each RNN only has access to information from on direction.
- 전부 다 masked 하는 건 아니고 한 15% 정도만 하고 예측한다.
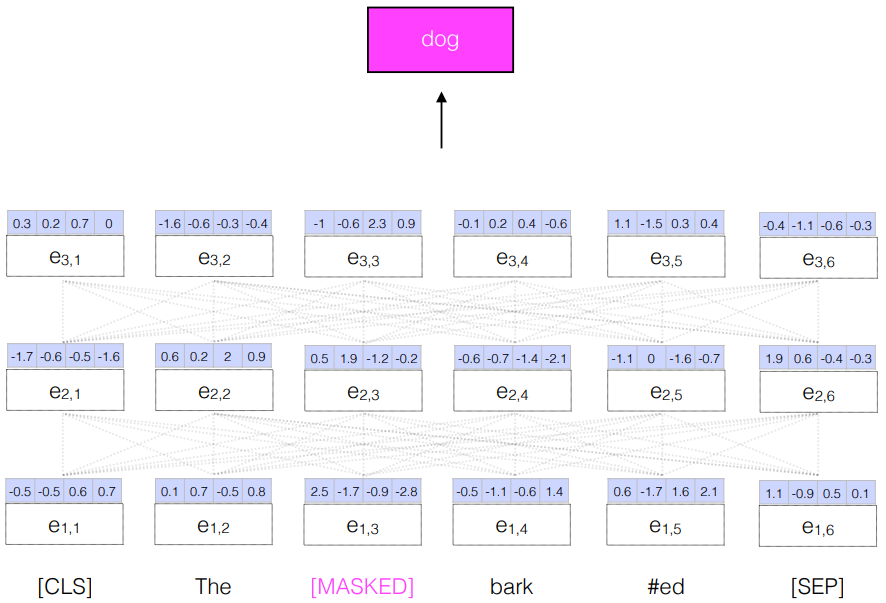
[참고]
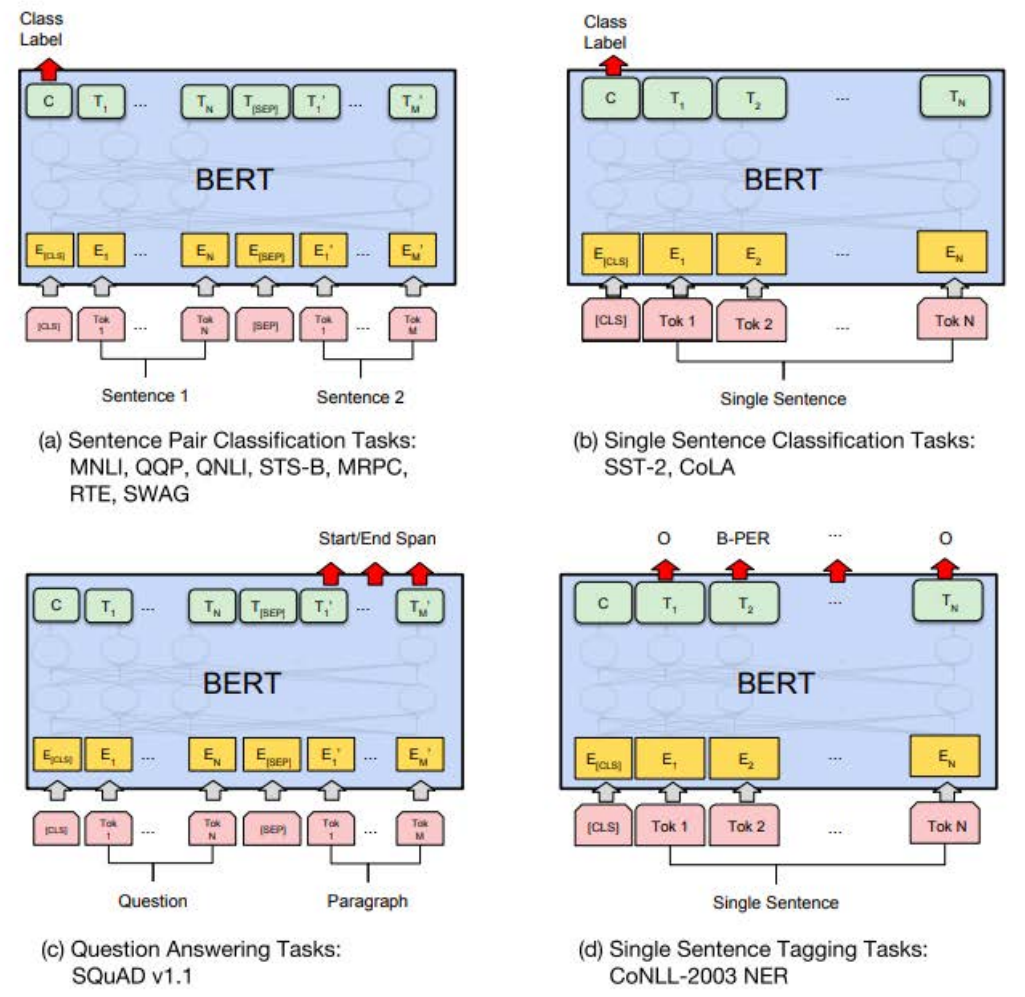
모든 sentence의 첫번째 token은 언제나 [CLS](special classification token) 이다. 이 [CLS] token은 transformer 전체층을 다 거치고 나면 token sequence의 결합된 의미를 가지게 되는데, 여기에 간단한 classifier를 붙이면 단일 문장, 또는 연속된 문장의 classification을 쉽게 할 수 있게 됩니다. 만약 classification task가 아니라면 이 token은 무시하면 됩니다.
또한 CLS 로 같은 문서에서 왔는지 다른 문서에서 왔는지를 classification 할 수 있다.
Next sentence prediction
- For a pair of sentences, predict from [CLS] representation whether they appeared sequentially in the training data

데이터사이언스와 자연어처리를 공부하고 있습니다.