Word Embedding
- pre-traiend word embeddings great for words that appear frequently in data
- Unseen words are treated as UNKs and assigned zero or random vectors; everything unseen is assigned the same representation
Shared structure
- Even in languages like English that are not agglutinative and aren't highly inflected, words share important structure
- Even if we never see the word "unfriendly" in our data, we should be able to reason about it as: un + friend + ly
Subword Model
- Rather than learning a single representation for each word type w, learn representation z for the set of ngrams that comprise it -> 분자단위 n-gram으로 쪼개서 학습시킴
How do we use word embeddings for document classification?

[참고]
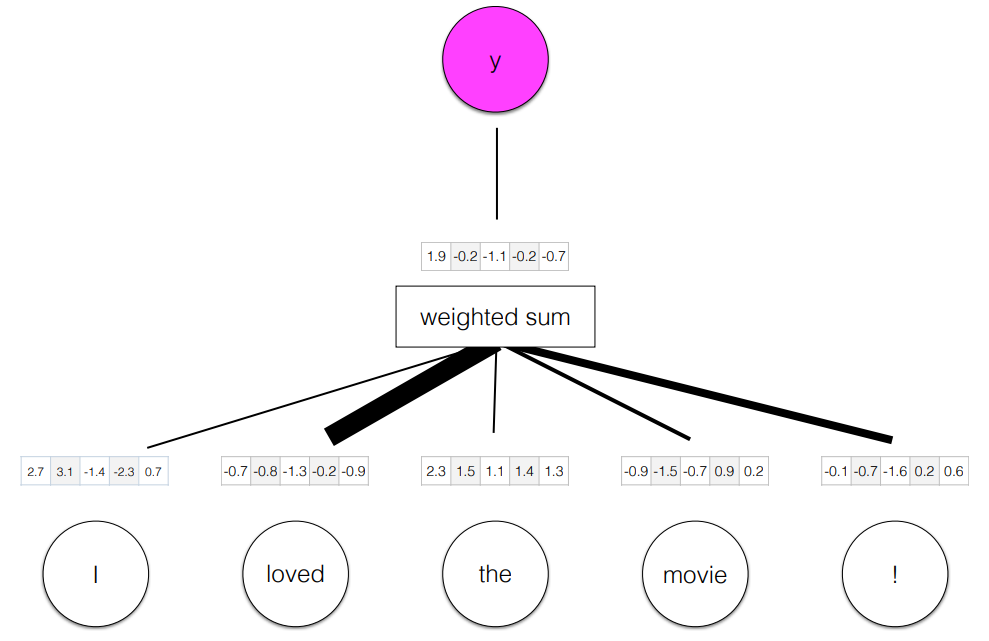
Attention
weighted sum 을 이용해서 word embeddings 을 사용할 때 사용하는 개념
어떤 단어에 더 집중해야할 지에 따라 비중을 달리한다.
Define v to be a vector to be learned; think of it as an "important word" vector. The dot product here measures how
similar each input vector is to that "important word" vectorLots of variations on attention
1) Linear transformation of x into before otting with v (선형변환)
2) Non-linearities after each operation (비선형)
3) "Multi-head attention" : multiple v vectors to capture different phenomena that can be attended to in the input
4) Hierarchical attention (sentence representation with attention over words + document representation with attention over sentences (word 레벨에서 한 번보고 sentence 레벨에서 한 번 보고 ...)Attention gives us a normalized weight for every token in a sequence that tell us how important that word was for the prediction -> 어떤 단어가 중요했는지 역으로 파악 가능
- This can be useful for visualization
RNN
- With an RNN, we can generate a representation of the sequences as seen through time t.
- This encodes a representation of meaning specific to the local context a word is used in.
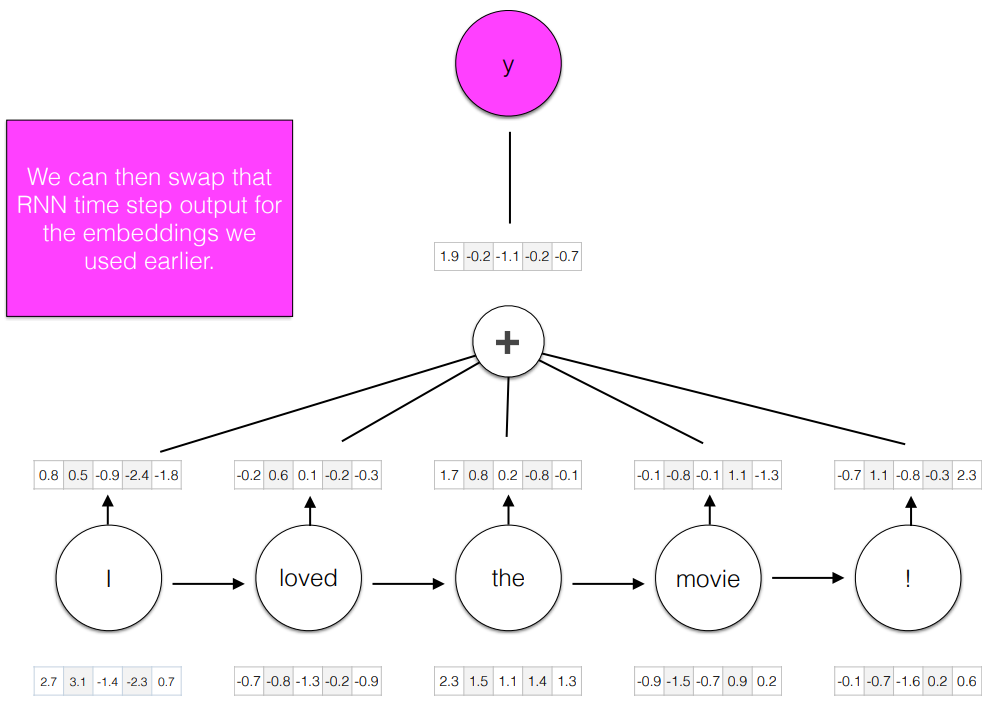
- What about the future context?
- RNN 을 이용해서 다음에 나올 단어를 예측해볼 수도 있다.
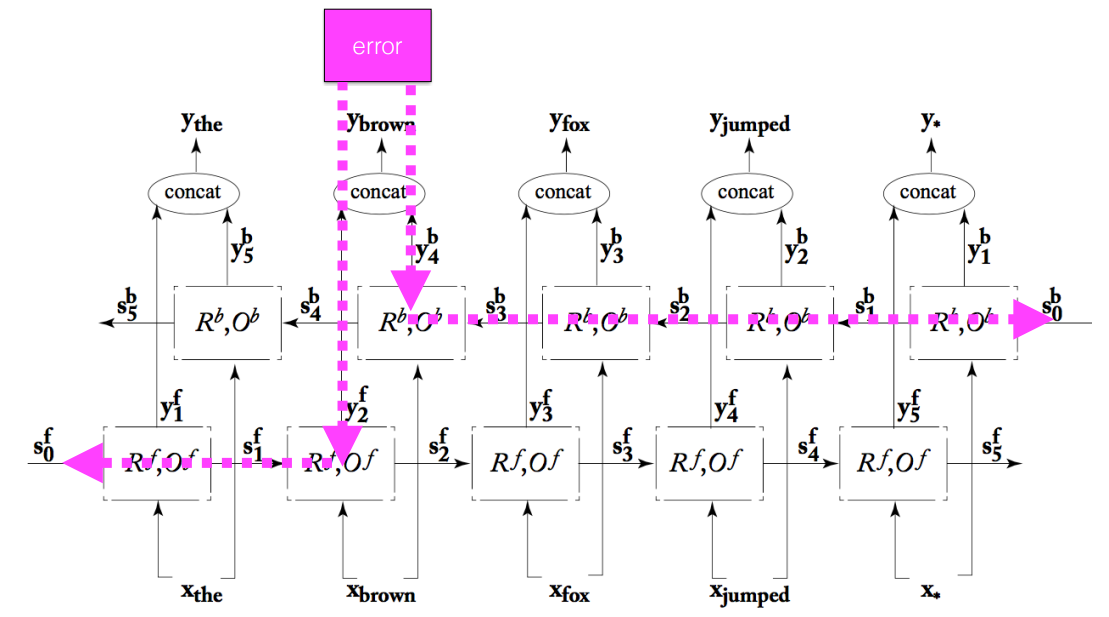
Bidirectional RNN
- A powerful alternative is make predictions conditioning both on the past and the future.
- Two RNNs
1) One running left- to- right
2) Oner right- to- left - The forwadr RNN and backward RNN each output a vector of size H at each time step, which we concatenate into a vector of size 2H.
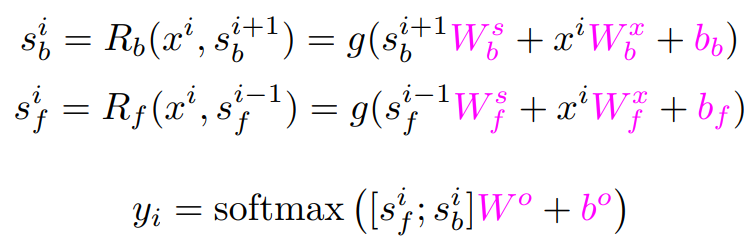
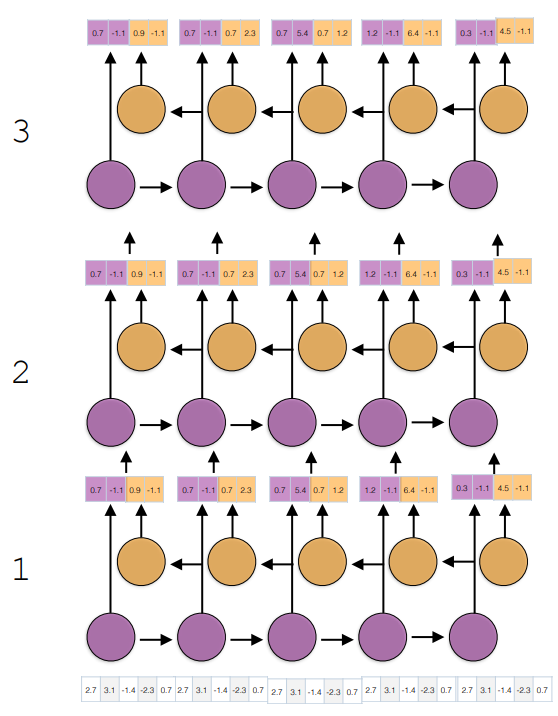
Stacked RNN
- Multiple RNNs, where the output of one layer becomes the input to the next.
Contextualized embeddings
- Models for learning static embeddings learn a single representation for a word type -> 지금까지 한 거
- 예 : word2vec, glove
- 단어에 대한 문맥 (순서 X) , 단어자체만 임베딩으로 이용

- 동물 bears, 과일 bears, 야구팀 마스코드 bears 가 모두 같은 벡터로 변환되는 것이 static embedding 이다. - Contextualized word representations
- 예 : elmo, bert, gpt
- 단어에 대한 문맥 (순서 O), 언어적 구조, 구조적 특징, domain의 특징 등 학습
- Big idea : transform the representation of a token in a sentence to be sensitive to its local context in a sentence and trainable to be optimized for a specific NLP task
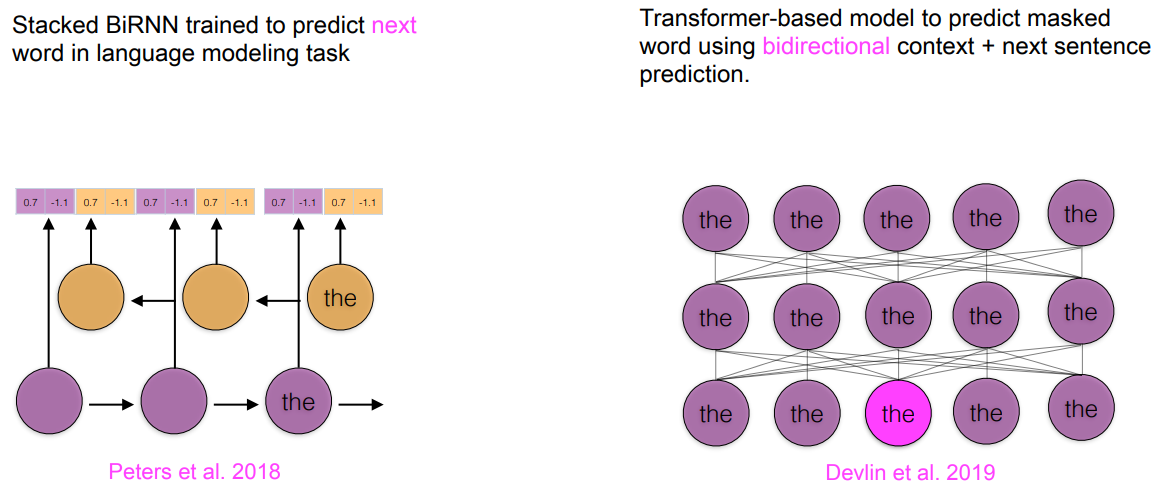
- BERT는 모든 상관관계를 Attention 을 고려하여 학습
- BERT는 Transformer-besed model 인데 빈칸채우기를 하기위해서 Bidirectional RNN 을 이용하기도 하고 문장을 쪼개서 이어지는 게 말이 맞는지를 확인하기도 한다.