NLP is interdisciplinary
- Artificaial intelligence
- Machine learning; statistical models, neural networks
- Linguistics
- Social sciences/humanities (models of languege at use in culture/ society)
[참고]
Turing Test
- 일반인으로 구성된 심사위원이 컴퓨터와 대화를 해서 사람으로 판정하는 비율이 30% 이상이 되면, 인간처럼 사고 할 수 있는 system 이라고 판정
What makes languege hard?
- Languege is complex social process
- Tremendous ambiguity at every level of representation
- Modeling it is AI-complete ( requires first solving general AI ) -> 사람이 모델링한 부분에서만 대답 가능하다.
- Speech acts -> 문장에서 여러 가지 뜻이 있을 수 있다.
- Conversational implicature -> 문장이 다른 뜻을 함축할 수도 있다.
- Shared knowledge -> 인간 사회에서 공유된 지식이다.
- Variation / Indexicality -> 변동 가능하고, 맥락에 따라서 의미가 변할 수 있다.
Processing as representation
NLP generally involves representation languege for some end, e.g.:
- dialogue
- translation
- speech recognition
- text analysis
-> representation learning = Vectorization
예를 들어,
'이재명' 이라는 단어에는 진보성향, 사람, 민주당, 정치인, ... 등의 정보가 벡터화 되고
'윤석열' 이라는 단어에는 보수성향, 사람, 국민의힘, 정치인, ... 등의 정보가 벡터화된다.
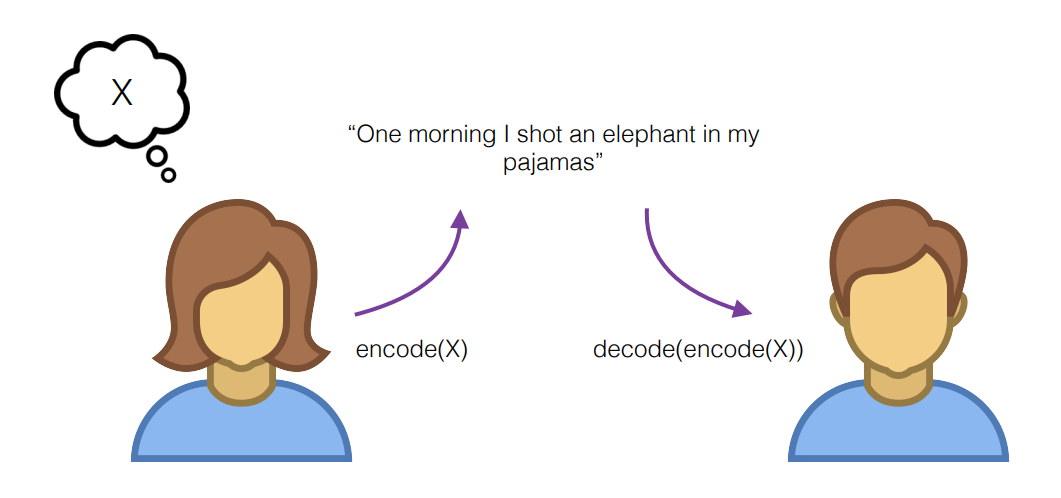
화자는 생각(X)를 encoding 해서 "One morning I shot an elephant in my pajamas" 를 청자에게 전달한다. 이때,
1. 화자는 청자의 이해를 최대화하기 위해서 어떤 단어를 선택할지를 고민하고
2. 의미는 대담자와 발화의 맥락에 의해 공동 구성된다.
3. (weak relativism) 언어의 구조는 생각에 영향을 미친다.
4. 청자는 encoding 된 문장을 듣고 decoding 하는데, words, morphology, systax, semantics(문맥), discourse(그 전의 대화) 등으로 구성된 representation 을 바탕으로 decoding 한다.
여러가지 NLP
- Sentiment analysis
- Question answering
- Machine translation
- Information extraction (정보 추출)
- Conversational agents (시리, 빅스비)
- Summarization
- Computational social science
1) Inferring ideal point of ploiticians based on voting behavior, speeches -> 연설 등 을 기반으로 정치인의 이상 추론
2) Detecting the triggers of censorship in blogs/social media -> 블로그, SNS에서 검열의 방아쇠 감지
3) Inferring power differentials in languege use -> 언어 사용의 힘 추론 - Text-driven forecasting
Methods
- Finite state automata/transducers (tokenization, morphological analysis) -> 유한 상태 오토마타
- Rule - based systems -> 규칙 기반 시스템 (옛날에 사용하던 방식)
- Probabilistic models -> 확률 모델
- Naive Bayes, Logistic regression, HMM, MEMM, CRF, languege models
- Dynamic programming (combining solution to subproblems)
- Dense representations for features/labels ( generally : inputs and outputs )
- Neural networks : multiplt, highly parameterized layers of interactions mediating the input/output
- Latent variable models ( specifying probabilitic structure between variables and inferring likey latent values )
개인 공부용
더 자세히 공부하고 (한글로) 간단히 정리하기

데이터사이언스와 자연어처리를 공부하고 있습니다.