OS : CentOS 7.9 64bit
MySQL : 8.0.34 - commercial
Replica Set : 1(Soure), 2(Replica)
Server
VIP : 10.1.247.13
node1(DB) : 10.1.247.10
node2(DB) : 10.1.247.11
node3(DB, Orchestrator) : 10.1.247.12
지난 포스팅에서, Orchestrator의 auto-rejoin 기능을 커스텀하여 추가해 보았습니다.
이번에는, 동일하게 커스텀 스크립트를 적용하여 Source(Master) 서버에 VIP Floating을 유연하게 해주는 것이 목적입니다.
마찬가지로, 이번 포스팅도 hoing.io (정현호) 님의 포스팅을 참고 하였습니다.
하지만, 포스팅에서도 언급 주신 것처럼 VIP 구조가 달라 따로 수정한 부분이 있습니다.
기존 글은 Master 포함 Slave 노드에서도 모두 VIP를 달아주어, Failover 발생 시 DeadMaster에 Slave VIP를 올려주고, Promote 된 Slave에 Master VIP를 옮겨주는 방식이었습니다.
기존에 진행하던 것과 다른 구성이라 이해하기 힘들었지만, 아마 정현호님께서는 Master가 Write, Slave 서버들이 Read를 한다는 목적이 담겨 해당 작업을 진행한 것 같습니다.
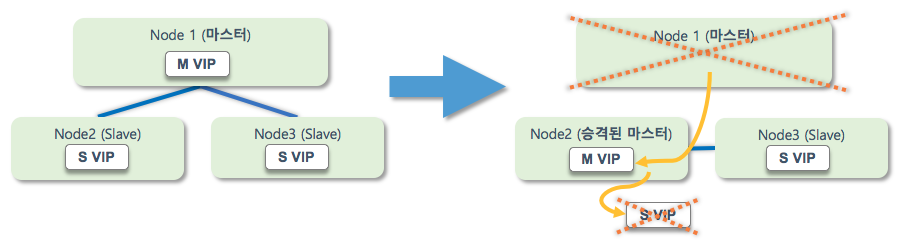

위 포스팅에서 가져온 이미지입니다. 언급한 것처럼 모든 Node에 VIP가 존재하며, 첫 번째 이미지는 DB 서버가 세 대 이상일경우, 아래 이미지는 두 대의 경우입니다.
3 Node 구성에서는 제가 진행했던 방식과 동일하나(어짜피 결국 승격된 마스터에 VIP가 올라가고, Slave 서버는, VIP든 RIP든 동일하게 접근 가능하기에), 이해가 조금 필요했던 구조는 아래 1 : 1 구조에서의 방식입니다.
위 예시들을 한꺼번에 가정하여 시나리오를 구성해보면
Failover Scenario(1)
- 세개의 Node 구성 중 Master Failover 발생 -> 승격된 Master에 VIP Floating 및 기존 Slave IP 제거 (1번 이미지) = 두개의 Node로 운영 중
- 두개의 Node 중 다시 한 번 Master Failover가 발생 -> 하나의 Node가 남았으므로, Master VIP 및 Slave VIP 모두 Floating (2번 이미지)
- DeadMaster 복구 후 Replication re-join 작업 진행 -> 기존 1 Node로 운영하던 Msater의 Slave VIP를 뗴어낸 후, re-join된 Node에 Slave VIP Floating
아래는 제가 기존에 관리하던 방식의 Failover Scenerio입니다.
Failover Scenario(2)
- 세개의 Node 구성 중 Master Failover 발생 -> 승격된 Master에 VIP Floating = 두개의 Node로 운영 중
- 두개의 Node 중 다시 한 번 Master Failover가 발생 -> 하나의 Node가 남았으므로, Master VIP Floating
- DeadMaster 복구 후 Replication re-join 작업 진행 -> VIP 작업 없음
관리의 수월성을 위해서는 1번 시나리오가 가장 바람직하다고 생각합니다.
왜냐하면, re-join된 DB 서버를 윗 단(AP 등)에서는 알 방법이 없기 때문입니다.
하지만 MySQL Router나, HAproxy와 같은 프록시 개념의 중간 서버가 ReplicaSet을 관리하고 Health Check를 진행한다면, 2번 시나리오로도 운영하는 데 문제가 없다고 생각합니다.
관련하여서는, 아래 포스팅 참고 부탁드립니다.
Haproxy 예시
VIP Floating은 MHA와 같이 스크립트로 각 Node에 접속해 Floating 작업이 필요합니다.
이를 위해서, 동일하게 각 서버의 SSH 통신이 가능한 OS 계정이 필요합니다.
또한, MHA와 마찬가지로 해당 계정이 /sbin/ifconfig 혹은 /sbin/ifup을 사용할 수 있는 권한이 있어야 합니다. (visudo)
해당 작업은 MHA 포스팅의 '2. 서버 별 SSH 구성과 접속 테스트, VIP 생성' 을 참고해주세요.
VIP 절체 과정은 아래와 같습니다.
VIP Floaing Scenario
- Orchestrator Hook 중 'OnFailureDetectionProcesses' 과정에서 Master VIP Down
- Orchestrator Hook 중 'PostFailoverProcesses' 과정에서 Promoted 된 Node VIP Up
아래와 같이 Orchestrator.conf를 수정합니다.
...
"OnFailureDetectionProcesses": [
"date +\"%Y%m%d %H:%M:%S\" >> /usr/local/orchestrator/log/recovery.log",
"echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /usr/local/orchestrator/log/recovery.log",
"echo '{failureType}' > /usr/local/orchestrator/log/detected_failuretype.log",
"/usr/local/orchestrator/vip_down.sh {failedHost} {successorHost} >> /usr/local/orchestrator/log/vip_change.log"
],
...
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /usr/local/orchestrator/log/recovery.log",
"/usr/local/orchestrator/vip_change.sh {failedHost} {successorHost} >> /usr/local/orchestrator/log/vip_change.log"
],
스크립트는 아래와 같습니다. PATH 및 네트워크 디바이스 장치명 등은 환경에 맞게 수정하시면 됩니다.
###vip_down.sh
echo " "
## PATH
export PATH=$PATH:/mysql/bin
failuretype=`cat /usr/local/orchestrator/log/detected_failuretype.log`
planned_takeover=`cat /usr/local/orchestrator/log/planned_takeover.log`
## Failure Master Host IP
failed_host_ip=`mysql --login-path=orchuser -sN -e "select ipv4 from orchestrator.hostname_ips where hostname='$1'"`
## Failure Master Host Ethernet Device
failed_host_ethernet=ens33
## Recovery - failover type 1
if [ "$failuretype" = "UnreachableMaster" ]
then
/bin/ssh -o StrictHostKeyChecking=no $failed_host_ip /bin/sudo /sbin/ifconfig $failed_host_ethernet:1 down
fi
## relocate or failover
if [ "$failuretype" = "DeadMaster" ]
then
/bin/ssh -o StrictHostKeyChecking=no $failed_host_ip /bin/sudo /sbin/ifconfig $failed_host_ethernet:1 down
fi
/bin/cp /dev/null /usr/local/orchestrator/log/planned_takeover.log
echo " "##vip_change.sh
#!/bin/bash
echo " "
## PATH
export PATH=$PATH:/mysql/bin
failuretype=`cat /usr/local/orchestrator/log/detected_failuretype.log`
planned_takeover=`cat /usr/local/orchestrator/log/planned_takeover.log`
## Failure Master Host IP
failed_host_ip=`mysql --login-path=orchuser -sN -e "select ipv4 from orchestrator.hostname_ips where hostname='$1'"`
failed_host_ethernet=ens33
## Promote Host IP
promote_host_ip=`mysql --login-path=orchuser -sN -e "select ipv4 from orchestrator.hostname_ips where hostname='$2'"`
promote_host_ethernet=ens33
## Recovery - failover type 1
## Master VIP if-up
/bin/ssh -o StrictHostKeyChecking=no $promote_host_ip /bin/sudo /sbin/ifup $promote_host_ethernet:1 up
/bin/ssh -o StrictHostKeyChecking=no $promote_host_ip /sbin/arping -c 5 -D -I $promote_host_ethernet:1 -s $failed_host_ip $failed_host_ip
/bin/cp /dev/null /usr/local/orchestrator/log/planned_takeover.log
echo " "해당 스크립트를 적용하고, 실제로 Master를 Graceful Takeover 시키거나, Failover 시킬 경우 VIP가 정상적으로 Floating 되는 것을 알 수 있습니다.
기존에는 'PostFailoverProcesses' 과정에서 VIP Down과 Up 모두 진행했으나, 해당 과정을 Jmeter로 부하 분산을 주는 과정에서 Duplicated Entry Key (Primary Duplicated) 에러가 발생하여 복제가 깨지게 됩니다.
아무래도 Failover 탐지 과정인 'OnFailureDetectionProcesses'에서 VIP를 내려주지 않으면, 여전히 Jmeter에서 Takeover되기 전인 Master Node에 데이터가 들어가기에 해당 현상이 발생합니다.
그리하여, VIP Down과 VIP Up 과정을 두개의 Hook으로 분리해 진행하였습니다.
Orchestrator는 기본적으로 모든 SwitchOver(Failover 포함) 과정에서 Relay 로그가 applied 되는 과정을 기다려 주지 않습니다.
MHA는 Failover 동작 중, 지정된 시간만큼 Relay applied 작업을 기다린 후 Switchover를 진행합니다.
아래는, MHA Failover 과정 중 Slave 지연 발생 시 Promote 과정을 기다리는 로그입니다.
(3번째 줄)
...
Fri Sep 8 02:39:04 2023 - [info] Starting recovery on 10.64.70.13(10.64.70.13:33061)..
Fri Sep 8 02:39:04 2023 - [info] Generating diffs succeeded.
Fri Sep 8 02:39:04 2023 - [info] Waiting until all relay logs are applied. ### 해당 과정에서 기다림
Fri Sep 8 02:39:04 2023 - [info] done.
Fri Sep 8 02:39:04 2023 - [debug] Stopping SQL thread on 10.64.70.13(10.64.70.13:33061)..
Fri Sep 8 02:39:04 2023 - [debug] done.
Fri Sep 8 02:39:04 2023 - [info] Getting slave status..
Fri Sep 8 02:39:04 2023 - [info] This slave(10.64.70.13)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000001:525). No need to recover from Exec_Master_Log_Pos.
Fri Sep 8 02:39:04 2023 - [debug] Current max_allowed_packet is 1073741824.
Fri Sep 8 02:39:04 2023 - [debug] Tentatively setting max_allowed_packet to 1GB succeeded.
Fri Sep 8 02:39:04 2023 - [info] Connecting to the target slave host 10.64.70.13, running recover script..
Fri Sep 8 02:39:04 2023 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='mha' --slave_host=10.64.70.13 --slave_ip=10.64.70.13 --slave_port=33061 --apply_files=/mha/remote/saved_master_binlog_from_10.64.70.14_33061_20230908023858.binlog --workdir=/mha/remote --target_version=8.0.34-commercial --timestamp=20230908023858 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.58 --debug --slave_pass=xxx
Fri Sep 8 02:39:04 2023 - [info]
Applying differential binary/relay log files /mha/remote/saved_master_binlog_from_10.64.70.14_33061_20230908023858.binlog on 10.64.70.13:33061. This may take long time...
Applying log files succeeded.
Fri Sep 8 02:39:04 2023 - [debug] Setting max_allowed_packet back to 1073741824 succeeded.
Fri Sep 8 02:39:04 2023 - [info] All relay logs were successfully applied.
Fri Sep 8 02:39:04 2023 - [info] Getting new master's binlog name and position..
Fri Sep 8 02:39:04 2023 - [info] mysql-bin.000003:157
Fri Sep 8 02:39:04 2023 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.64.70.13', MASTER_PORT=33061, MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=157, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Fri Sep 8 02:39:04 2023 - [info] Executing master IP activate script:
Fri Sep 8 02:39:04 2023 - [info] /mha/scripts/master_ip_failover --command=start --ssh_user=mysql --orig_master_host=10.64.70.14 --orig_master_ip=10.64.70.14 --orig_master_port=33061 --new_master_host=10.64.70.13 --new_master_ip=10.64.70.13 --new_master_port=33061 --new_master_user='mha' --new_master_password=xxx
Set read_only=0 on the new master.
...Orchestrator는 'DelayMasterPromotionIfSQLThreadNotUpToDate'라는 파라미터를 제공하여 해당 과정을 재현할 수 있습니다.
해당 파라미터는, Master에서 오류 발생 시(Takeover 포함) 모든 Slave가 지연되었을 경우, 적용되지 않는 Relay 로그를 반영시킬 때 까지 기다립니다.
모든 Slave가 지연될 경우, Slave 중 하나라도 지연된 것이 없을 때 까지 기다렸다가, 먼저 완료된 Slave를 Master로 승격합니다.
반대로 하나의 Slave가 지연될 경우, 지연되지 않은 Slave를 Master로 승격합니다.
아래와 같이 orchestrator.conf에 추가합니다.
...
"PostGracefulTakeoverProcesses": [
"echo 'Planned takeover complete' >> /usr/local/orchestrator/log/recovery.log",
"/usr/local/orchestrator/takeover_replication_start.sh {failedHost} >> /usr/local/orchestrator/log/recovery.log"
],
"CoMasterRecoveryMustPromoteOtherCoMaster": true,
"DelayMasterPromotionIfSQLThreadNotUpToDate" : true, ##추가
"DetachLostSlavesAfterMasterFailover": true,
"ApplyMySQLPromotionAfterMasterFailover": true,
"PreventCrossDataCenterMasterFailover": false,
"PreventCrossRegionMasterFailover": false,
"MasterFailoverDetachReplicaMasterHost": false,
"MasterFailoverLostInstancesDowntimeMinutes": 0,
"PostponeReplicaRecoveryOnLagMinutes": 0,
"OSCIgnoreHostnameFilters": [],
"GraphiteAddr": "",
"GraphitePath": "",
"GraphiteConvertHostnameDotsToUnderscores": true,
"ConsulAddress": "",
"ConsulAclToken": "",
"ConsulKVStoreProvider": "consul"
...해당 과정 진행 후 Jmeter나 Sysbench 등으로 부하분산 테스트 중 Switchover 발생의 경우, 앞서 설명한 것처럼 Slave 중 Relay Log가 반영된 노드가 있기 전 까지 대기하다가 Switchover를 진행합니다.
