서론
사내 프로젝트(이하 P)에서는 외부 솔루션을 이용한 관리 시스템(이하 K)과 연동하여 동작하고 있다. 관리의 편의성을 위해서 P는 K와 별도로 데이터베이스를 운영하고 있고(K에서 유지할 필요가 없는 P 만의 데이터 등) K는 P 말고도 다른 프로젝트들과 연동하고 있기 때문에 P는 주기적으로 K에서 변경된 사항을 읽어서 반영하고 있다.
정확히는 데이터를 변경하는 엔드포인트를 노출해두면 K에서 P로 HTTP 요청을 보내서 반영하는 방식이다. 그리고 반대로 P의 변경사항을 K로 반영해야 할 때가 있는데 고객은 K에 직접 접근할 수 없기 때문에 P를 이용하여 데이터를 추가하거나 갱신하면 P에서도 주기적으로 이를 K로 반영하여 K와 연동하는 다른 곳에서도 변경사항을 알 수 있도록 하기 위해서다.
이 과정에서 사용하는 두 가지 기술이 Spring Batch 프로젝트와 Quartz 스케줄러다. 전자는 batch process, 즉 순차적으로 진행되는 작업의 모음을 실행하고 분기에 따라 처리하며 후자는 timed job, 즉 cron 표현식이나 일정 시간마다 지정한 횟수만큼 반복해서 특정 작업을 실행할 수 있는 라이브러리다.
일정 시간마다 특정 작업을 수행해서 결과에 따라 분기하는 작업은 구현에 따라 복잡해질 수 있겠지만 P에서는 실패한 작업에 대해 로그 출력이나 재시작 처리 등에 사용하고 있다. 마침 이전에 경험해보지 못한 기술이기 때문에 이를 학습해보고자 하고 오늘은 그 중에서 Quartz 스케줄러와 그 활용에 대해 간략하게 정리해보고자 한다.
본론
왜 Quartz를 사용하는가?
Quartz는 홈페이지에서 볼 수 있듯이 스탠드얼론 애플리케이션부터 이머커스 시스템까지 사용할 수 있는 라이브러리다. 단순히 몇 번 반복하는 작업이라면 for 반복문 같은 원초적인 기법으로 수행할 수도 있겠지만 작업 실패 시 재시작 처리, 애플리케이션 재시작 후에 작업 복귀, JTA 트랜잭션 및 클러스터링(Java EE 쪽 기능이라는듯) 등 좀 더 복잡한 기능이 필요해질 때 이를 단순히 구현할 수 있는 것보다 수준높은 기능을 제공한다.
스프링 부트에서도 이 Quartz 스케줄러에 대한 연동을 제공하기 때문에 한결 간편하게 사용할 수 있고 Java 기반의 컴포넌트만 있다면 꼭 스프링같은 프레임워크 없이 가볍게 동작할 수 있다. 그리고 메모리 기반이나 데이터베이스 기반으로 작업을 기록하고 스케줄링 관련 이벤트에 대한 콜백 리스너 인터페이스를 제공하여 일종의 플러그인 기능을 제공하는 등 사용자가 유연하게(flexible) 활용할 수 있다는 장점이 있다.
그리고 설정된 스레드 풀 내에서 새 스레드를 생성하며 작업을 실행시키기 때문에 메인 스레드를 막지(blocking) 않고 비동기적으로 동작할 수 있다는 장점이 있다. 이는 작업의 상태와 관련된 특징(stateful)으로 이어지는 문제기 때문에 고려해야 할 점이기도 하다.
스프링 부트의 지원
Quartz 라이브러리만 받아서 스케줄링하는 것과 스프링 부트를 통해서 스케줄링하는 것은 약간 차이가 있다. 예상할 수 있겠지만 스프링 부트의 가장 큰 장점인 자동 설정인데 Scheduler 인터페이스, JobDetail, Calendar, Trigger 등 Quartz 스케줄러에 관련된 Bean 객체들을 컨테이너에 등록해준다. 원래는 Scheduler 객체를 SchedulerFactory를 통해서 생성하고 직접 시작시켜줘야 하지만 SchedulerFactoryBean을 통해서 자동으로 시작된 상태로 생성할 수 있는 것이다.
쿼츠는 컨테이너에 등록된 DataSource를 기반으로 스케줄링 관련 데이터(실행 기록, 스케줄러 정보 등)를 저장하기 위해 데이터베이스에 테이블을 자동으로 추가하고 기록하거나 메모리에 기록(기본값)할 수 있다.
QuartzJobBean이라는 추상 클래스를 제공하여 스케줄러 컨텍스트나 기타 데이터들이 등록되고 간단한 예외 처리를 포함한 Quartz 작업을 생성할 수 있고 JobDetailFactoryBean, SimpleTriggerFactoryBean 등 제공되는 Bean 객체를 이용해 다른 스타일로 스케줄러에 필요한 객체를 생성할 수도 있다.
핵심 구성요소
Job, JobDetail
You can create a single job class, and store many ‘instance definitions’ of it within the scheduler by creating multiple instances of JobDetails...
Lesson 3: More About Jobs and Job Details
Quartz에서 수행할 '작업'은 Quartz의 Job 인터페이스를 구현해서 작성할 수 있다. 이 인터페이스는 JobExecutionContext라는 컨텍스트를 매개변수로 받는 단 하나의 execute 메서드를 정의하고 있으며 이 메서드 안에 실제로 수행할 내용, 즉 Scheduler의 스레드가 실행할 코드가 들어간다.
그러나 클라이언트가 Job 인터페이스를 구현하여 정의한 작업은 단순히 '동작'만 구현한 것이고 실제로 이를 실제로 인스턴스화하여 작업으로 실행시키기 위해 필요한 Job 구현체의 자바 클래스, JobDataMap, 식별자, 실행 설정(동시 실행 가능, 복구 여부 등) 등을 포함한 작업 인스턴스를 정의할 때는 JobBuilder를 이용하여 JobDetail 인터페이스의 구현체를 생성해야 한다.
JobBuilder는 이 JobDetail 인터페이스의 구현체를 생성하기 위한 빌더 클래스로 빌더 패턴을 이용하는 것처럼 메서드 체이닝으로 작업 인스턴스를 정의하는데 필요한 정보를 필요한 만큼 부여하여 생성할 수 있다. 예를 들어 withIdentity 메서드로 JobKey를 부여하거나 usingJobData 메서드로 JobDataMap에 필요한 데이터를 집어넣을 수 있다.
위의 인용구에서 볼 수 있듯이 JobDetail은 스케줄러가 Job을 어떻게 실행할지 속성과 JobDataMap을 이용하여 정의하는 방식이라고 정리할 수 있다. 왜냐면 Job 인터페이스의 구현체가 단순히 독립적인 작업을 실행하는 게 아니라 작업 실행 시 주어진 입력값에 따라 다른 동작을 하는 변칙적인 로직을 가질 수도 있기 때문이다. 이 경우 모든 경우에 맞는 Job 인스턴스를 구현하는 것은 불가능하기 때문에 기본적인 '동작'을 Job 인터페이스로 정의하고 이 동작에 입력값을 JobDataMap 즉 JobDetail을 이용하여 다양하게 입력하고 실행할 수 있는 것이다.
JobDataMap, JobExecutionContext
쿼츠 스케줄러는 Job 구현체 클래스를 인스턴스화(newInstance())하여 작업을 실행하고 종료 시 참조를 삭제하여 가비지 컬렉터가 제거하도록 하는 생명 주기를 반복한다. 이는 매 실행마다 반복되기 때문에 클래스 필드로서는 작업 실행간에 상태를 유지할 수 없으며 이 경우 JobDataMap을 활용할 수 있다.
JobDataMap은 JobBuilder에서 초기값으로 등록할 수 있고 작업 내부에서 참조할 수 있으며 스케줄러에 작업이 등록될 때 같이 등록된다. 이름에서 추측할 수 있듯이 해당 Job과 관련된 데이터를 저장하고 있는 자바 Map 자료구조로 특정 Job 인스턴스의 상태 정보(state information)를 담고 있다. 언급했듯이 쿼츠 스케줄러는 작업 실행을 stateful하게 유지하지 않기 때문에 작업에 필요한 데이터를 외부에서 담아주거나 내부적으로 작업 실행간 stateful하게 데이터를 유지하는 용도로 활용된다.
이런 JobDataMap은 쿼츠 설정에 따라 메모리 상에 유지될 수도 있고 JDBC를 이용하여 데이터베이스 같은 영속성 영역에 저장될 수도 있다. 후자의 경우 직렬화, 역직렬화를 수행하기 때문에 별도의 주의가 필요할 것이다.
작업의 컨텍스트인 JobExecutionContext는 해당 작업의 실행환경(run-time environment)에 접근할 수 있는 기능을 정의한 인터페이스다. 작업과 트리거의 JobDataMap에 한번에 접근할 수 있는 getMergedJobDataMap(), 현재 작업의 시작 시간을 조회할 수 있는 getFireTime(), 현재 작업을 실행시킨 Scheduler 인스턴스나 Trigger에 접근할 수 있는 getScheduler(), getTrigger() 메서드 등 실행과 관련된 여러 메서드가 정의되어 있다.
JobDataMap이나 JobExecutionContxt나 각 작업 실행의 정보를 담고 있지만 전자가 작업 실행에 관련된 값을 담는다면 후자는 좀 더 넓은 측면에서 작업 실행 환경의 정보를 담고 있다고 할 수 있다.
JobKey, TriggerKey
JobKey는 JobDetail을 고유하게 구별하는 식별자인데 작업이 실제로 Scheduler에 등록되서 실행될 때 각 작업을 구분하기 위해 사용된다. 동일한 작업이 다양한 환경으로 실행될 수 있기 때문에 필요하며 '이름'과 '그룹' 문자열의 조합으로 이루어진다.
비슷하게 TriggerKey 역시 Trigger를 고유하게 구분하기 위한 이름과 그룹 문자열의 조합이다.
Trigger, TriggerBuilder
Job 인터페이스를 구현하여 작업의 '동작'을 정의하고 JobBuilder를 이용하여 JobDetail 인터페이스의 구현체를 생성하여 '실행'을 정의했다면 이제 무엇이 남았을까? 바로 '스케줄'이다. 정확히는 이 작업을 실행할 시각이나 방법을 정의하는 Trigger다. 작업은 그 자체로는 언제 실행될지를 정의할 수 없기 때문에 쿼츠 스케줄러에서 작업이 특정 시간대나 간격을 반복으로 동작하려면 이를 별도의 객체로 정의해야 하며 이것이 Trigger 인터페이스의 인스턴스가 된다.
쿼츠에서는 가장 기본적인 두 가지 방식의 스케줄링을 제공하는데 일정 간격으로 n번 반복하는 simple 방식과 Cron 표현식을 이용한 cron 방식을 제공한다. 두 가지 트리거 모두 JobBuilder처럼 TriggerBuilder를 이용하여 생성할 수 있다.
Trigger 역시 TriggerKey를 가지며 동일하게 이름과 그룹으로 조합될 수 있다.
Scheduler
쿼츠의 Scheduler, 스케줄러는 JobDetail과 Trigger 인스턴스를 관리하고 Trigger가 실행(fire)될 때 JobDetail을 기반으로 작업을 실행시킨다. 스케줄러 인스턴스는 SchedulerFactory를 통해 생성할 수 있지만 언급했듯이 스프링 부트와 연동하는 경우 설정 파일에 따라 자동으로 컨테이너에 스케줄러 인스턴스를 등록하며 이를 주입받아 스케줄러에 작업을 등록(scheduleJob)하거나 트리거(triggerJob)를 설정할 수 있다.
이런 JobDetail이나 Trigger를 참조할 때는 JobKey, TriggerKey를 이용하여 참조하게 된다.
기타
Trigger의 발생 시점을 일부분 제외하기 위한 Calendar 인터페이스나 JobDetail의 durability(연관된 Trigger가 없을 때도 스케줄러에 남아있을지 여부), 어노테이션을 이용한 동시 실행 제어, Trigger, Job 실행 리스너 등은 Quartz 스케줄러의 공식 홈페이지 튜토리얼에서 확인할 수 있다.
환경 설정
여기서부터는 Quartz를 Spring Boot 환경에서 활용한다고 가정하고 진행하겠다.
JobStore 선택
이런 스케줄링을 수행하려면 실행 기록이나 환경 설정(Trigger의 경우 몇 번 실행할 것인지 등)을 어딘가에는 기록해야 다음 시작 시간에 다시 읽어서 활용할 수 있다. 이를 저장할 저장소를 Quartz에서는 JobStore라 칭하며 스케줄링 수행과 관련된 모든 데이터를 메모리 상에 저장하거나 JDBC를 이용하여 데이터베이스에 저장할 수 있다.
으레 그렇듯 당연히 메모리 상에 저장하는게 빠르긴 하지만 실제로 스케줄러를 활용할 때는 이력 관리와 장애 복구 등을 위해서 데이터베이스 상에 저장하게 될 것이다. 다행히 Quartz는 다양한 데이터베이스 제품군과 호환되기 때문에 대부분의 경우 문제없이 동작하며 스프링 환경에서는 DataSource 객체를 활용할 수 있다.
spring.quartz.job-store-type=jdbc스프링 부트는 기본적으로 메모리 기반 JobStore를 제공하고 위처럼 jdbc로 명시되었을 때만 DataSource와 연동하기 때문에 스케줄러가 데이터베이스를 활용하도록 하려면 JobStore 타입을 jdbc로 명시해야 된다.
spring.quartz.jdbc.initialize-schema=alwaysQuartz 스케줄러에서 활용할 테이블이 생성되지 않았다면 위와 같은 옵션을 통해 자동으로 생성할 수도 있다. 그러나 이는 쿼츠 라이브러리에 포함된 SQL을 활용하며 이는 기존 테이블을 drop하고 다시 생성하기 때문에 데이터를 유지해야 할 필요가 있다면 별도로 쿼리를 작성하는 것이 좋다.
Autowired 가능한 JobFactory
스프링에서 제공하는 QuartzJobBean 클래스는 스프링 부트가 등록한 JobFactory를 이용하여 JobDataMap의 프로퍼티를 작업 클래스의 setter 메서드(setMyData 처럼)로 주입할 수 있도록 한다. 그러나 흔히 사용하는 것처럼 @Autowired 같은 어노테이션을 이용하여 다른 Bean 객체를 주입받으려 해도 작업 클래스는 컴포넌트가 아니기 때문에 주입받을 수 없다.
그래서 이 블로그 포스트에서는 BeanFactory의 메서드를 이용하여 작업을 인스턴스화하는 시점에 의존성을 주입하는 방식을 설명하고 있다. 한번 등록해두면 쿼츠 작업 클래스에서 서비스나 리포지토리를 주입받아 사용할 수 있기 때문에 꽤나 유용하다.
스레드 풀 설정
언급했듯이 Java 타이머나 반복문 등을 이용한 비-스케줄러 방식과 쿼츠의 차이점은 각 작업마다 스레드를 생성해서 멀티스레드 기반으로 동시에 처리할 수 있다는 것이다. 그러나 당연히 동시에 실행해야 하는 작업보다 스레드의 갯수가 적으면 우선순위가 높은 작업들이 먼저 실행되고 나머지는 대기(block) 상태가 되고 스케줄러에서 지정된 대기 시간을 넘기면 misfire 상태가 된다.
그렇기 때문에 쿼츠가 활용할 스레드 풀의 크기를 적절히 조절하는 것이 좋은데 공식 문서에서는 대부분의 스케줄 작업이 동시에 일어나지 않고 작업의 갯수가 그렇게 많지 않다는 점에서 스레드 풀의 크기를 5 정도로 권장하고 있다(스프링 쿼츠 스타터는 10개로 설정). 라이브러리에 내장된 SimpleThreadPool 같은 경우는 고정된 크기의 스레드 풀을 제공한다.
org.quartz.threadPool.class=...
org.quartz.threadPool.threadCount=...스프링 부트에서도 별다른 설정 프로퍼티를 제공하지 않기 때문에 Quartz 속성을 직접 설정하면 된다. 위의 프로퍼티는 ThreadPool 인터페이스의 구현체 클래스나 스레드의 갯수를 설정한다. 지정하지 않으면 SimpleThreadPool을 사용한다.
기타 설정
http://www.quartz-scheduler.org/documentation/quartz-2.3.0/configuration/
데이터베이스 테이블
작업들이 즉시 실행하고 완료되서 더 이상 추적할 필요가 없는 경우만 있다면 좋겠지만 대부분의 스케줄링이 필요한 작업의 경우 트리거를 이용하여 무한정 반복하도록 설정할 것이다. 그 외에도 상태를 유지해야 하는 stateful한 작업의 경우 스레드가 계속 그 작업만 처리하고 있을 수 없기 때문에 쿼츠는 전자든 후자든 어쩔 수 없이 데이터베이스(또는 메모리)에 실행중인 작업이나 트리거의 정보를 저장해야 할 필요가 있다.
위의 옵션을 적용하여 자동으로 생성된 스키마를 확인하면 다음처럼 11개 정도의 테이블이 생성된 것을 볼 수 있다.
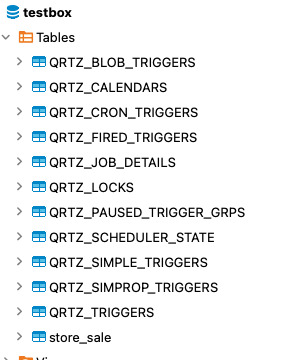
어떤 테이블이 어떤 일을 하는지는 내부적으로 알아서 할 일이기 때문에 자세히 알 필요는 없지만 스케줄러에 작업이 등록되어 트리거에 따라 실행중일 때 어떤 값을 갖게 되는지 간단하게 살펴보자. 아무런 작업도 하지 않는 5초 간격, 무한 반복 작업을 하나 생성해서 등록해보았다.

QRTZ_TRIGGERS 테이블에는 현재 스케줄러에서 실행중인 트리거의 정보가 등록된 것을 볼 수 있다. 트리거의 이름은 별도로 지정하지 않을 경우 랜덤한 값으로 주어지며 DEFAULT 그룹에 포함되는 것을 볼 수 있다.

그 외에도 트리거 타입, 이전 실행(fire) 시각, 다음 실행 시각이 저장되는 것을 볼 수 있다.
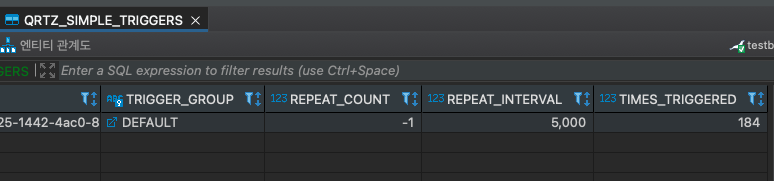
QRTZ_TRIGGERS 테이블에 트리거의 대략적인, 정확히는 어떤 종류의 트리거든 공유하는 정보를 저장하고 있었다면 각 트리거 별로 세부적인 정보는 QRTZ_SIMPLE_TRIGGERS 같은 별도의 테이블에서 저장하고 있다. Simple 트리거같은 경우 반복 횟수, 반복 간격, 실행 횟수 등을 저장하고 있다.
트리거의 이름과 그룹 즉 TriggerKey 값과 스케줄러의 이름을 QRTZ_TRIGGERS 테이블의 외래키로 가지는 동시에 기본키로 사용하기 때문에 스케줄러 내에서 트리거를 겹치지 않고 구분할 수 있다.
마지막으로 살펴볼 QRTZ_JOB_DETAILS 테이블에는 이전에 언급했던 JobDetail에 대한 정보가 담겨있다. 정확히는 작업 자체의 특징에 대한 내용으로 작업을 실행하는 스케줄러의 이름과 작업의 이름, 그룹, 설명, 작업 클래스 이름 등이 있다.

JOB_CLASS_NAME 컬럼에는 실제로 Job 인터페이스를 구현하거나 QuartzJobBean을 상속받아 만든 작업 구현체의 클래스 이름이 경로를 포함하여 저장되어 있다. 클래스의 정확한 경로를 알고 있기 때문에 쿼츠는 추후 작업을 다시 인스턴스화할 때 어떤 클래스의 인스턴스를 생성할 지 알 수 있는 것이다.

그 외에도 작업의 속성(동시 실행 가능, 갱신된 JobDataMap 저장 여부, 복구 필요 등)과 JobDataMap이 직렬화되어 저장되는 것을 볼 수 있다. JOB_DATA 컬럼같은 경우 blob 타입으로 직렬화된 JobDataMap의 바이트 코드가 저장된다.
코드 작성
Kotlin과 Spring Boot 기반으로 작성하였다.
작업 정의, 생성, 트리거 생성, 스케줄링
Job 인터페이스 구현
class GenerateRandomSalesJob(
private val salesService: StoreSalesService
) : Job {
var storeName: String? = null
override fun execute(context: JobExecutionContext?) {
println("=== EXECUTING [${this::class.simpleName}] ===")
val generatedStoreName = storeName ?: "GENERATED_STORE_${Random.nextInt(10000)}"
val createdStoreSaleData = salesService.createStoreSaleData(generatedStoreName)
println("Created store sale data: $createdStoreSaleData")
println("================= D O N E ===================")
}
}간단하게 StoreSale 레코드를 생성하는 작업을 Job 인터페이스를 구현해서 생성했다. 이를 실제로 사용할 때는 언급했듯이 JobBuilder를 이용하여 JobDetail 구현체를 생성하고 실행할 타이밍을 지정하는 Trigger를 생성해서 스케줄러의 scheduleJob 메서드로 계획(schedule)할 수 있다.
fun scheduleJobImplementation() {
val job = JobBuilder.newJob()
.ofType(GenerateRandomSalesJob::class.java)
.withIdentity(JobKey(GenerateRandomSalesJob::class.simpleName, "main"))
.usingJobData("storeName", "STORE_CREATED_FROM_JOB_IMPLEMENTATION")
.build()
val trigger = TriggerBuilder.newTrigger()
.withIdentity(TriggerKey("fireInstantlyOnce", "main"))
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(1)
.withRepeatCount(0)
)
.build()
scheduler.scheduleJob(job, trigger)
}빌더 클래스를 활용하는 모습에서 쉽게 알 수 있듯이 Job을 생성할 때는 GenerateRandomSalesJob 이라는 클래스의 이름을 JobKey의 이름 부분으로 생성하고 main 그룹에 포함시킨 것을 볼 수 있다. 그리고 작업을 인스턴스화하는 동시에 JobDataMap에 storeName 란 키로 "STORE_CREATED_FROM_JOB_IMPLEMENTATION"이란 문자열을 값으로 넣는 것을 볼 수 있다.
Trigger를 생성할 때도 비슷하게 TriggerKey를 생성하고 즉발, 한 번 반복하고 1초마다 반복하도록 실행 스케줄을 설정하는 것을 볼 수 있다. 왜 withRepeatCount(0)인데 한 번 반복하는지 이상할 수 있지만 메서드 자체가 파라미터로 받은 횟수보다 1 만큼 더 반복한다고 정의되어 있다. 그럼 '-1'로 등록하면 되지 않을까 싶지만 그건 무한히 반복하는 용도로 정의되어 있다. 사실 한 번도 반복하지 않을 작업이라면 스케줄러에 등록하는 것 자체가 이상하기 때문에... 헷갈리지 않도록 하자.
실행 결과는 다음처럼 단 한번만 실행되고 종료된 것을 볼 수 있다.

스프링에서 제공하는 QuartzJobBean을 이용하여 정의하는 방식은 다음과 같다.
class GenerateRandomSalesJobBean(
private val salesService: StoreSalesService
) : QuartzJobBean() {
var storeName: String? = null
override fun executeInternal(context: JobExecutionContext) {
println("=== EXECUTING [${this::class.simpleName}] ===")
val generatedStoreName = storeName ?: "GENERATED_STORE_${Random.nextInt(10000)}"
val createdStoreSaleData = salesService.createStoreSaleData(generatedStoreName)
println("Created store sale data: $createdStoreSaleData")
println("================= D O N E ===================")
}
}해당 작업을 스케줄하는 방식도 동일하다.
fun scheduleQuartzJobBean() {
val job = JobBuilder.newJob()
.ofType(GenerateRandomSalesJobBean::class.java)
.withIdentity(JobKey(GenerateRandomSalesJobBean::class.simpleName, "main"))
.usingJobData("storeName", "STORE_CREATED_FROM_QUARTZ_JOB_BEAN")
.build()
val trigger = TriggerBuilder.newTrigger()
.withIdentity(TriggerKey("fireTwoTimes1SecondInterval", "main"))
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(3)
.withRepeatCount(1)
)
.build()
scheduler.scheduleJob(job, trigger)
}이번엔 3초 간격으로 두 번(1+1) 실행되도록 스케줄했다. 실행 결과는 다음과 같다.
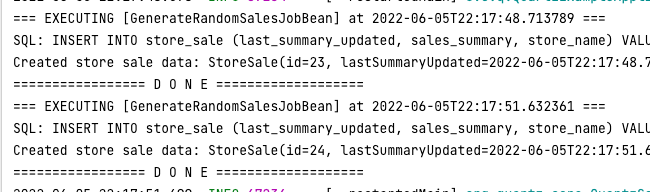
확인을 위해 타임스탬프를 찍도록 했고 미세한 오차가 있지만 설정한 대로 3초 간격으로 작업이 실행되는 것을 볼 수 있다.
특이한 것은 JobDataMap에 있는 프로퍼티를 클래스의 setter 메서드로 주입하는 기능이 Job 인터페이스를 구현한 방식과 QuartzJobBean을 상속받은 방식 둘 다 적용되었다. 생각해보면 QuartzJobBean도 Job 인터페이스를 구현하기 때문에 어쨌든 Job 인터페이스를 구현하면 스프링이 주입해주는 것 같다.
거기에 의존성 주입도 문제 없이 처리됐는데 기존에는 별도의 autowiring factory를 정의해야 했던 걸 생각하면 이상하다. Baeldung에서는 스프링에서 제공하는 SpringBeanJobFactory가 ApplicationContext의 Bean 객체를 꺼내쓰는 기능이 없기 때문에 별도의 설정이 필요하다고 했고 실제로 P에서도 그렇게 하고 있었다. 아마 이 프로젝트에서는 웹 모듈을 붙이지 않았기 때문에 WebApplicationContext가 없어서 뭔가 다르게 적용된 것이 아닐까 생각한다.
이 부분은 좀 더 알아봐야할 것 같다.
작업 데이터의 영속
위의 데이터베이스 테이블에서 볼 수 있었듯이 QRTZ_JOB_DETAILS의 JOB_DATA 컬럼을 이용하여 작업의 데이터를 stateful하게 유지할 수 있다. 그러나 쿼츠 작업은 기본적으로 데이터를 유지하기 않기 때문에 다음과 같은 작업을 그냥 실행하면 데이터가 영속되지 않는 것을 확인할 수 있다.
class NOPJob : Job {
override fun execute(context: JobExecutionContext) {
// val jobDataMap = context.mergedJobDataMap
val jobDataMap = context.jobDetail.jobDataMap
val runningCount = if (jobDataMap.containsKey("count")) jobDataMap.getLongValueFromString("count") else 0L
println("INFINITE JOB IS RUNNING $runningCount times...")
jobDataMap.putAsString("count", runningCount + 1)
}
}참고로 JobDataMap을 단순히 읽기만 할 때는 JobExecutionContext에서 getMergedJobDataMap() 메서드(Kotlin에서는 mergedJobDataMap 프로퍼티)를 이용하여 JobDetail의 JobDataMap과 Trigger의 JobDataMap을 한 번에 접근할 수 있다. 그러나 JobExecutionContext 인터페이스의 getMergedJobDataMap() 메서드 정의를 읽어보면 다음과 같다.
Do not expect value 'set' into this JobDataMap to somehow be set or persisted back onto a job's own JobDataMap - even if it has the @PersistJobDataAfterExecution annotation.
즉 이 메서드로 얻은 JobDataMap은 변경사항이 반영되지 않으므로 JobDetail에서 JobDataMap을 참조해야 작업 데이터를 영속시킬 수 있다.
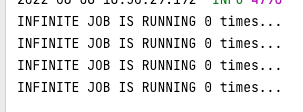
하지만 실제로 실행시켜보면 위처럼 JobDataMap에 넣은 count가 반영되지 않는 것을 볼 수 있는데 이는 쿼츠 작업이 기본적으로 stateless하게, JobDataMap을 영속하지 않기 때문이다. 그래서 매 실행마다 작업 데이터를 영속하려면 작업 클래스에 @PersistJobDataAfterExecution 어노테이션을 붙여줘야 한다.
@PersistJobDataAfterExecution
class NOPJob : Job { ... }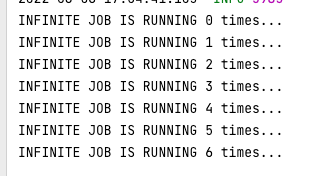
어노테이션을 작업 클래스에 붙여주면 정상적으로 작업 데이터가 영속되는 것을 볼 수 있다.
그러나 같은 작업 클래스를 여러 트리거가 동시에 실행시킨다면 어떨까? 어쨌든 작업 데이터는 스케줄러에 정의된 JobStore에 저장되기 때문에 여러 스레드에서 같은 데이터를 읽고 쓰는 경우 경쟁 상태(race condition)같은 문제가 발생할 수 있다. 그래서 보통 이렇게 stateful한 작업의 경우 @DisallowConcurrentExecution 어노테이션을 붙여서 해당 작업 인스턴스가 동시에 여러 개가 동작할 수 없도록 제한한다.
이 어노테이션은 작업 클래스 자체를 여러 개 등록할 수 없다는 게 아니라 하나의 작업 인스턴스가 여러 Trigger에 의해 동시에 실행될 수 없다는 것이다. 스케줄러에 등록 자체는 JobKey가 중복되지만 않는다면 얼마든지 등록할 수 있으나 동시에 실행하려 할 때 작업 클래스에 해당 어노테이션이 붙어있고 JobDetail이 이미 실행 중이라면 한 번에 오직 하나의 트리거로만 실행될 수 있다.
@PersistJobDataAfterExecution
class NOPJob : Job {
override fun execute(context: JobExecutionContext) {
val jobDataMap = context.jobDetail.jobDataMap
val runningCount = ...
println("Thread #${Thread.currentThread().id} ${LocalDateTime.now()}: ...")
Thread.sleep(1000)
...
}
}fun createInfiniteJob() {
val jobDetail = JobBuilder.newJob()
.ofType(NOPJob::class.java)
.storeDurably()
.build()
scheduler.addJob(jobDetail, false)
val repeatBy3Seconds = TriggerBuilder.newTrigger()...
val repeatBy3Seconds2 = TriggerBuilder.newTrigger()...
scheduler.scheduleJob(repeatBy3Seconds)
scheduler.scheduleJob(repeatBy3Seconds2)
}위처럼 동시 수행 제한 어노테이션을 붙이지 않고 하나의 JobDetail을 repeatBy3Seconds, repeatBy3Seconds2 두 개의 트리거로 실행하도록 스케줄러에 등록했다. 이 경우 쿼츠 스케줄러가 두 스레드를 이용하여 두 작업을 거의 같은 시간에 실행하게 된다.
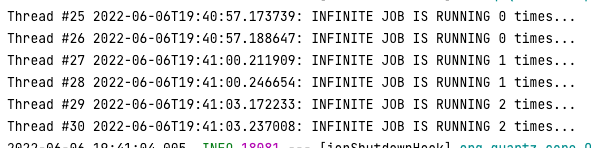
스레드 25/26, 27/28, 29/30이 각각 두 트리거를 맡아서 거의 같은 시간에 작업을 실행한 것을 볼 수 있다. 각 트리거는 3초 간격으로 반복하여 각 스레드에서 1초간 sleep한다. 각 트리거는 각자 자신의 JobDataMap을 읽어서 count를 증가시키는데 두 스레드가 동시에 작업을 수행하고 있지만 count가 2씩 올라가는게 아니라 1씩 올라가는 것을 볼 수 있다.
작업 클래스에 어노테이션을 붙인 후 다시 실행하면 다음과 같다.
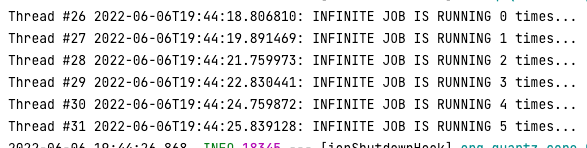
이번에는 스레드 26/27, 28/29, 30/31 간 1초의 간격이 있는 것을 볼 수 있는데 이는 작업 클래스에서 Thread.sleep 메서드를 이용하여 스레드를 sleep 시킨 기간과 일치한다. 즉 @DisallowConcurrentExecution 어노테이션이 한 작업 클래스를 한 트리거에서만 실행할 수 있도록 제한했기 때문에 26번 스레드에서 두 트리거 중 하나로 작업을 실행했고 완료된 후에 다른 트리거로 마저 작업한 것이다.
이 경우 한 번에 한 트리거만 작업을 실행시키기 때문에 경쟁 상태가 발생하지 않고 누적 count가 차곡차곡 잘 쌓이는 것을 볼 수 있다.
이처럼 동기화를 고려해야 하는 작업의 경우 특히 @PersistJobDataAfterExecution 어노테이션을 사용하여 stateful한 작업을 수행하는 경우 @DisallowConcurrentExecution를 같이 붙이는 것이 좋을 것이다.
Misfire 처리
위의 코드를 보면 생각해봐야 하는 부분이 두 트리거가 작업해야 하는데 한 트리거는 동시 수행 제한때문에 작업을 실행시키지 못했다. 증명을 위해 의도한 부분이긴 했지만 어쨌든 트리거는 지정된 실행(fire) 시간에 실행하지 못한 즉 misfire 상태가 됐다. 지금이야 한정된 조건 내에서 발생했지만 실제로 스케줄러가 동작할 때는 자원 고갈(스레드 풀 부족 등), 로컬 시간 문제 등 다양한 원인에 의해 misfire가 발생할 수 있다.
이런 경우 쿼츠 스케줄러에서는 트리거(simple, cron) 별로 복구 정책을 제공하고 있으며 공통 정책 한가지에 더해 CronTrigger는 두 가지, SimpleTrigger는 다섯 가지 정책을 제공한다. 이는 트리거를 생성할 때 SimpleScheduleBuilder나 CronScheduleBuilder 스케줄 빌더 클래스에서 withMisfireHandlingInstruction 으로 시작하는 메서드로 설정할 수 있다.
복구 정책을 명시적으로 지정하지 않으면 트리거는 Trigger 인터페이스에 정의된 SMART POLICY를 따른다. 이는 Trigger 인터페이스의 구현체 즉 simple 트리거라면 SimpleTriggerImpl이나 cron 트리거라면 CronTriggerImpl 클래스가 구현하고 있는 updateAfterMisfire() 메서드에게 처리를 위임한다. 자세한 내용은 아래와 같다.
CronTrigger
CronTrigger는 Cron 표현식으로 스케줄링하기 때문에 misfire(이하 불발)가 발생했을 때 딱히 해결할 수 있는 방법이 없다. 그래서 다음과 같은 세 가지 정책을 제공한다.
- 불발 무시(MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY)
- 즉시 재실행(MISFIRE_INSTRUCTION_FIRE_ONCE_NOW)
- 아무것도 하지 않음(MISFIRE_INSTRUCTION_DO_NOTHING)
불발 무시와 아무것도 하지 않는 것의 차이는 메서드 이름 updateAfterMisfire에서 알 수 있듯이 불발 트리거의 상태를 갱신(update)하느냐 그렇지 않느냐다. 전자의 경우 트리거에 불발이 일어나지 않은 것처럼 정말 아무런 동작도 하지 않고 실행됐을 때 트리거 상태가 갱신된다. 그에 비해 후자는 트리거의 다음 실행 시각을 갱신한다는 차이가 있다. 즉시 재실행 정책은 불발이 발생했을 경우 다음 실행 시각을 현재 시각으로 지정하여 스케줄러에게 현재 작업을 즉시 재실행하도록 요청하는 정책이다.
@Override
public void updateAfterMisfire(org.quartz.Calendar cal) {
int instr = getMisfireInstruction();
if(instr == Trigger.MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY)
return;
if (instr == MISFIRE_INSTRUCTION_SMART_POLICY) {
instr = MISFIRE_INSTRUCTION_FIRE_ONCE_NOW;
}
if (instr == MISFIRE_INSTRUCTION_DO_NOTHING) {
Date newFireTime = getFireTimeAfter(new Date());
while (newFireTime != null && cal != null
&& !cal.isTimeIncluded(newFireTime.getTime())) {
newFireTime = getFireTimeAfter(newFireTime);
}
setNextFireTime(newFireTime);
} else if (instr == MISFIRE_INSTRUCTION_FIRE_ONCE_NOW) {
setNextFireTime(new Date());
}
}소스 코드에서 볼 수 있듯이 설정된 불발 정책에 따라 분기하며 아무것도 하지 않는 정책은 무시하는 정책과 달리 다음 실행 시각을 Calendar(스케줄링 제외 구간)와 계산해서 설정하고 스마트 정책이나 즉시 재실행 정책은 다음 실행 시간을 현재 시각으로 설정하는 것을 볼 수 있다.
SimpleTrigger
SimpleTrigger는 반복 횟수로 다루기 때문에 cron보다 비교적 제공하는 정책이 많다.
- 불발 무시(MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY)
- 즉시 재실행(MISFIRE_INSTRUCTION_FIRE_NOW)
- 횟수 감소, 다음 일정으로 실행( MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT)
- 횟수 유지, 다음 일정으로 실행(MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT)
- 횟수 감소, 즉시 재실행(MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT)
- 횟수 유지, 즉시 재실행(MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT)
불발 무시는 cron의 경우와 동일하니 제외하고 총 5가지 정도가 제공되는데 반복 횟수를 유지하는지 여부와 실행 시각의 조합으로 이루어져있을 뿐이다. '즉시 재실행'같은 경우는 트리거를 즉시 재실행하는 정책인데 만약 2번 이상 실행되는 트리거라면 '횟수 유지, 즉시 재실행'과 동일한 옵션이다.
횟수를 유지(EXISTING)한다는 것은 트리거가 불발됐더라도 남은 실행 횟수를 차감하지 않는 옵션이다. 반대로 차감(REMAINING)한다는 것은 불발된 경우도 실행 횟수에서 차감하는 방식이다. 다음 일정(NEXT)으로 실행, 즉시(NOW) 재실행하는 옵션은 제약 사항이 있는데 전자의 경우 Calendar를 반영하고 후자의 경우 현재 시각이 트리거 자체의 종료 시각을 넘기지 않아야 한다.
@Override
public void updateAfterMisfire(Calendar cal) {
int instr = getMisfireInstruction();
if(instr == Trigger.MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY)
return; // 불발을 무시하는 정책의 경우 별다른 조치를 취하지 않는다.
if (instr == Trigger.MISFIRE_INSTRUCTION_SMART_POLICY) {
// 스마트 정책에서는...
if (getRepeatCount() == 0) {
// 반복 횟수가 0번(실제로는 0+1번)인 경우 즉시 다시 실행시킨다.
instr = MISFIRE_INSTRUCTION_FIRE_NOW;
} else if (getRepeatCount() == REPEAT_INDEFINITELY) {
// 무한 반복인 경우 횟수를 차감하고(별 의미는 없다) 다음에 실행시킨다.
instr = MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT;
} else {
// 그 외의 경우 횟수를 유지하고 즉시 다시 실행시킨다.
// if (getRepeatCount() > 0)
instr = MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT;
}
} else if (instr == MISFIRE_INSTRUCTION_FIRE_NOW && getRepeatCount() != 0) {
// 즉시 재실행 정책이며 2번 이상 반복 횟수가 남아있는 경우
// 정책 설명에 나와있듯이 반복 횟수를 유지하고 즉시 재실행한다.
instr = MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT;
}
if (instr == MISFIRE_INSTRUCTION_FIRE_NOW) {
// cron 때와 마찬가지로 현재 시각을 다음 실행 시각으로 설정하여 즉시 재실행한다.
setNextFireTime(new Date());
} else if (instr == MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT) {
// 다음 실행시각을 현재 이후로 설정하고 반복 횟수를 복원하지 않는다.
Date newFireTime = getFireTimeAfter(new Date());
while (newFireTime != null && cal != null
&& !cal.isTimeIncluded(newFireTime.getTime())) {
newFireTime = getFireTimeAfter(newFireTime);
if(newFireTime == null)
break;
//avoid infinite loop
java.util.Calendar c = java.util.Calendar.getInstance();
c.setTime(newFireTime);
if (c.get(java.util.Calendar.YEAR) > YEAR_TO_GIVEUP_SCHEDULING_AT) {
newFireTime = null;
}
}
setNextFireTime(newFireTime);
} else if (instr == MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT) {
// 다음 실행시각을 현재 이후로 설정하고 반복 횟수를 복원한다.
Date newFireTime = getFireTimeAfter(new Date());
while (newFireTime != null && cal != null
&& !cal.isTimeIncluded(newFireTime.getTime())) {
newFireTime = getFireTimeAfter(newFireTime);
if(newFireTime == null)
break;
//avoid infinite loop
java.util.Calendar c = java.util.Calendar.getInstance();
c.setTime(newFireTime);
if (c.get(java.util.Calendar.YEAR) > YEAR_TO_GIVEUP_SCHEDULING_AT) {
newFireTime = null;
}
}
// 다음 재실행이 가능한 경우 소실된 반복 횟수를 계산해서 복원한다.
if (newFireTime != null) {
int timesMissed = computeNumTimesFiredBetween(nextFireTime,
newFireTime);
setTimesTriggered(getTimesTriggered() + timesMissed);
}
setNextFireTime(newFireTime);
} else if (instr == MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT) {
// 즉시 재실행하고 반복 횟수를 차감한다.
Date newFireTime = new Date();
// 한 번만 실행하는 작업(0)이나 무한정 실행하는 작업(REPEAT_INDEFINITELY)이 아니라면...
if (repeatCount != 0 && repeatCount != REPEAT_INDEFINITELY) {
// 반복 횟수를 계산해서 차감하고 실행 횟수를 초기화한다.
setRepeatCount(getRepeatCount() - getTimesTriggered());
setTimesTriggered(0);
}
// 언급했듯이 즉시 재실행하는 경우 트리거의 종료 시각을 넘기지 않았어야 한다.
if (getEndTime() != null && getEndTime().before(newFireTime)) {
setNextFireTime(null); // We are past the end time
} else {
setStartTime(newFireTime);
setNextFireTime(newFireTime);
}
} else if (instr == MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT) {
// 즉시 재실행하고 반복 횟수를 유지한다.
Date newFireTime = new Date();
int timesMissed = computeNumTimesFiredBetween(nextFireTime,
newFireTime);
// 반복 횟수를 복원해야 할 트리거라면 계산해서 복원한다.
if (repeatCount != 0 && repeatCount != REPEAT_INDEFINITELY) {
int remainingCount = getRepeatCount()
- (getTimesTriggered() + timesMissed);
if (remainingCount <= 0) {
remainingCount = 0;
}
setRepeatCount(remainingCount);
setTimesTriggered(0);
}
// 위 블록과 동일한 조건.
if (getEndTime() != null && getEndTime().before(newFireTime)) {
setNextFireTime(null); // We are past the end time
} else {
setStartTime(newFireTime);
setNextFireTime(newFireTime);
}
}
}소스 코드에서 볼 수 있듯이 불발 정책에 따라 분기한다. CronTriggerImpl 때보다는 좀 길기 때문에 이번엔 소스 코드에 주석을 적어 보았다.
쿼츠에서 제공하는 불발 정책이 그렇게 엄청난 기능은 아니지만 스케줄러 레벨에서 비즈니스 로직에 관여해서 복구 기능을 제공하는 것도 이상하고 오히려 간단하기 때문에 사용하기 쉬운게 아닐까 싶다.
실제로 불발 상황을 만들어 볼 때는 설정 파일에서 다음과 같이 스레드 개수를 하나로 제한하고 매우 오래 걸리는 작업의 우선순위를 높게 스케줄링할 수 있다.
spring:
quartz:
job-store-type: jdbc
jdbc:
initialize-schema: always
properties:
org:
quartz:
threadPool:
threadCount: 1 # 스레드 풀의 크기를 1로 제한한다.
jobStore:
misfireThreshold: 1000 # 불발 감지 시간을 1초(기본 60초)로 줄인다.그리고 다음처럼 트리거 빌더에서 withPriority 메서드를 이용하여 한 작업이 스케줄 우선순위를 갖도록 할 수 있다.
// 스레드를 독차지하기 위한 작업을 스케줄링한다.
scheduler.scheduleJob(
// PendingJob 클래스는 Thread.sleep(3000000)을 수행한다.
JobBuilder.newJob().ofType(PendingJob::class.java).build(),
TriggerBuilder.newTrigger()
.startNow()
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.repeatForever()
.withIntervalInSeconds(1)
)
// '9'의 우선순위. 숫자가 높을수록 우선.
.withPriority(9)
.build()
)
// 다른 작업에 밀리는 우선순위의 작업을 스케줄링한다.
scheduler.scheduleJob(
JobBuilder.newJob().ofType(PendingJob::class.java).build(),
TriggerBuilder.newTrigger()
.startNow()
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withRepeatCount(10)
.withIntervalInSeconds(2)
// 남은 횟수를 유지하고 다음 실행 시간으로 조정하는 정책 적용.
.withMisfireHandlingInstructionNextWithExistingCount()
)
.withPriority(1)
.build()
)불발을 처리한 경우 쿼츠 스케줄러는 INFO 레벨 로그에 기록한다.

당연하지만 불발을 아예 무시하는 정책에서는 출력되지 않는다.
결론
쿼츠 라이브러리가 제공하는 다양한 상황을 모두 테스트해볼 순 없어서 가장 기본적인 요구사항인 작업 정의, 트리거 정의, 스케줄링, 데이터 영속 등을 살펴보았다. P에서도 스케줄러 클러스터링이라던지 리스너같은 세부적인 기능까진 사용하진 않기 때문에 간단한 부분만 다뤄보았다.
환경에 따라 다르겠지만 스케줄러를 클러스터링해서 부하를 분산해야 할 정도로 대규모의 시스템은 지금 프로젝트에서는 경험하기 어려울 것 같다. 언젠가 그런 시스템을 경험해볼 수 있으면 좋겠다.
