
프로젝트 명
옷늘날씨
프로젝트 진행 기간
2023.11.09 ~ 2023.12.08
개발환경
Frontend - Next.js, Typescript, Vercel, Recoil, Sass
Backend - SpringBoot, Node.js, Spring Security, Apache Kafka, Spring Cloud, Nginx, MySQL, MongoDB
Infra - AWS EC2, AWS RDS, AWS S3, Docker, Git Action
팀 구성
Frontend 3명, Backend 3명
기여한 부분
- Spring Eureka, Spring Cloud를 사용한 MSA 환경 구축
- Spring Cloud Config를 사용해 모든 서비스들의 설정파일 관리
- MSA 환경에 적합한 DB 스키마 구축
- 서버간 통신을 위한 Kafka 클러스터 구축
- Git Action을 사용해 모든 서비스들의 배포자동화 구현
- Spring 사용해 댓글 서비스, Node 사용해 카테고리 서비스 구현
프로젝트 URL
https://weatherfit.vercel.app/
Github
https://github.com/kdt-8-4/Weatherfit
주제 및 기획의도
최근 날씨의 추이를 살펴보면, 급격한 온도변화와 큰 일교차때문에 외출 전 옷을 어떻게 입어야 할지 고민을 하게 됨
SNS나 영상 매체를 통해 사람들이 패션에 관심이 늘어남
이러한 이유로 날씨의 변화에 외출 전 코디에 대해 고민하는 시간이 길어짐에 따라, 날씨와 온도에 따른 적합한 옷차림을 제시해주는 서비스를 기획하게 됨
아키텍처 및 설계 산출물
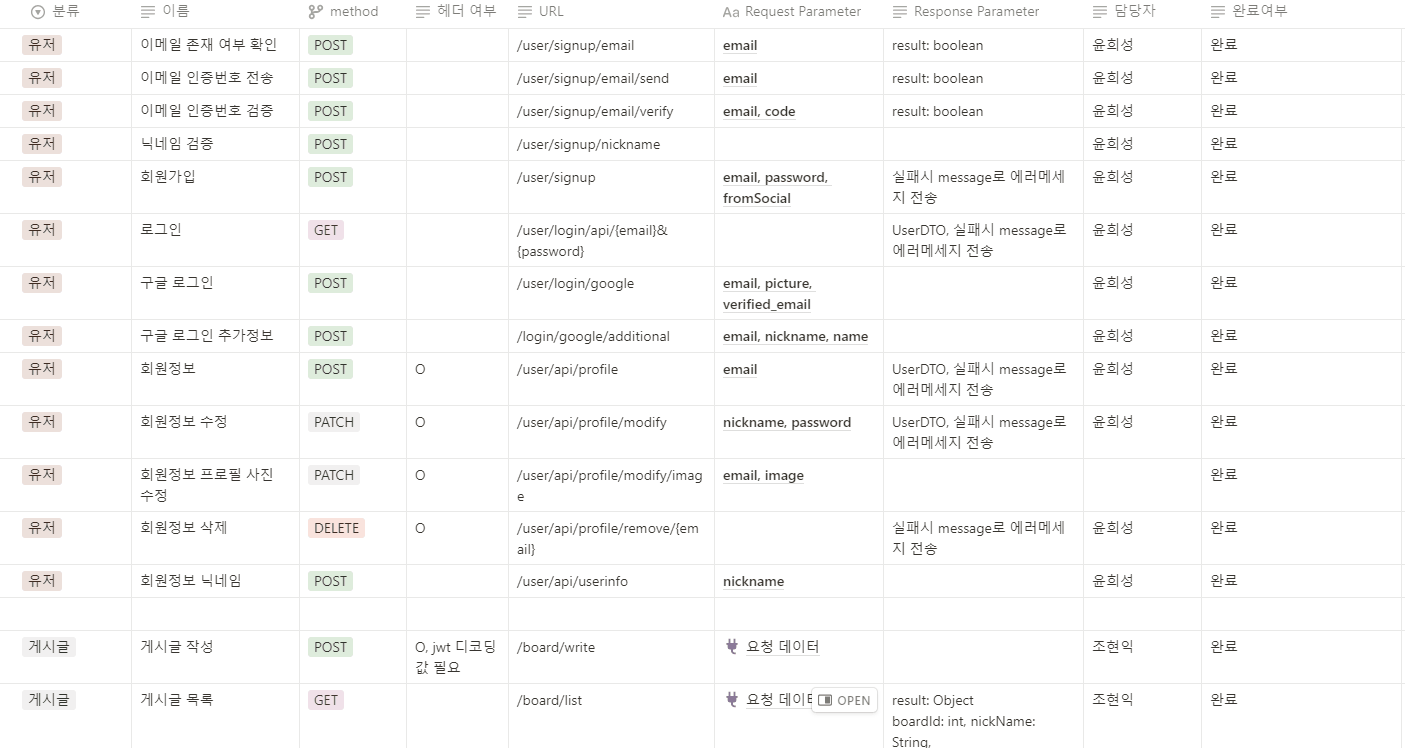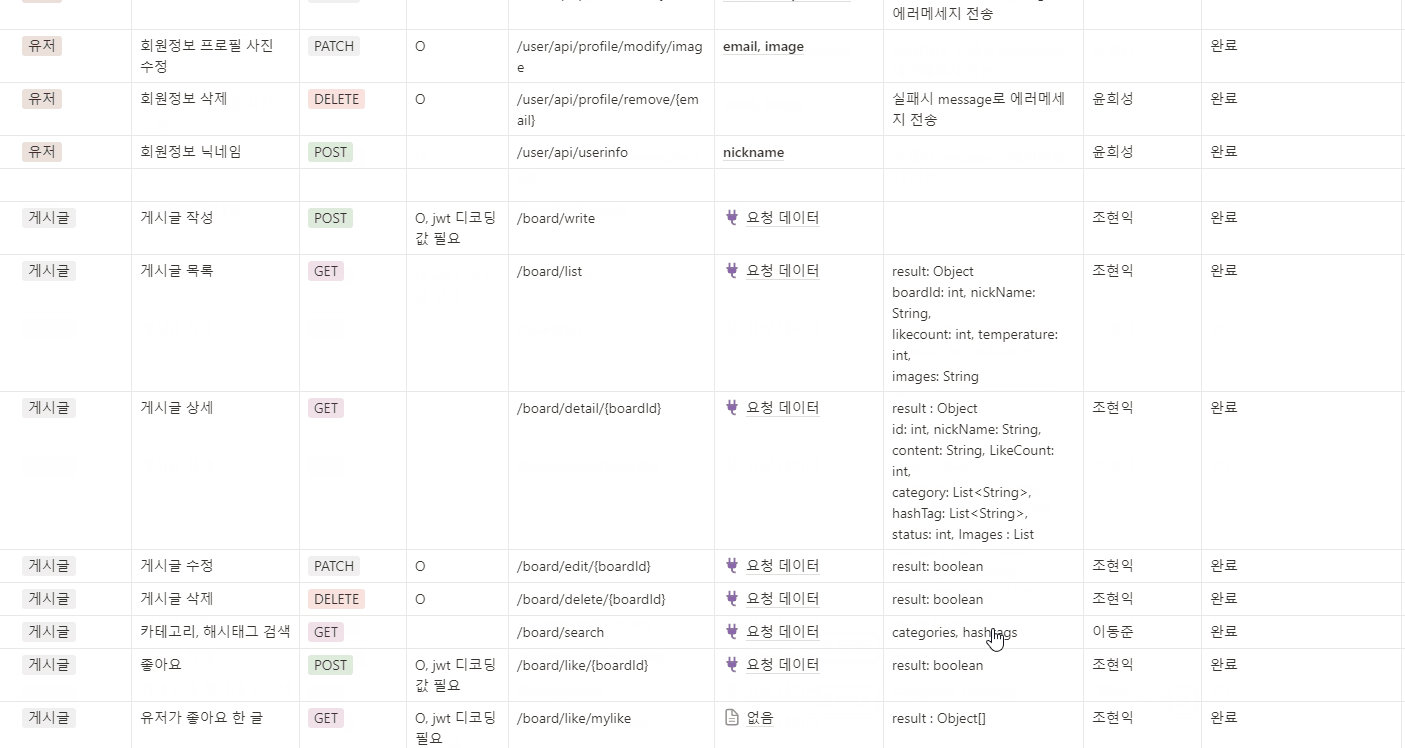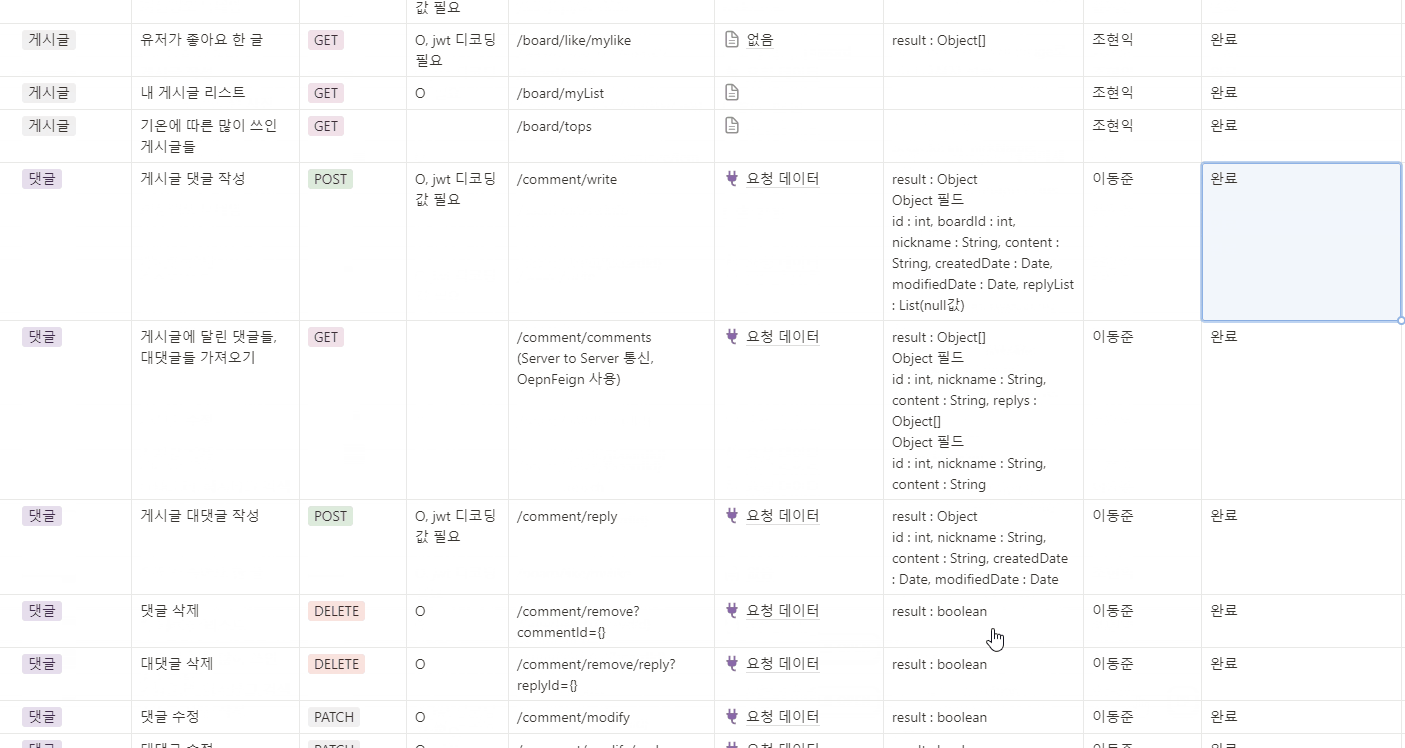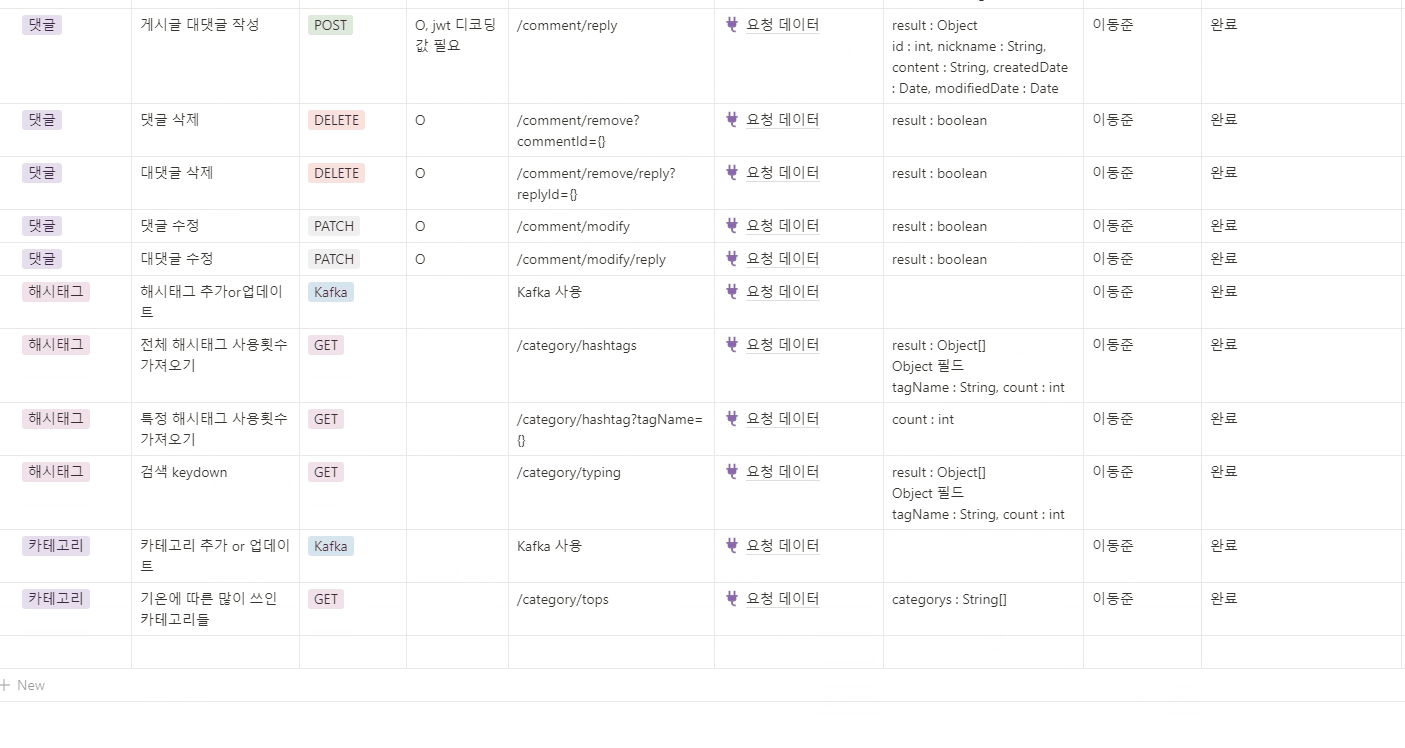
API 명세
ERD
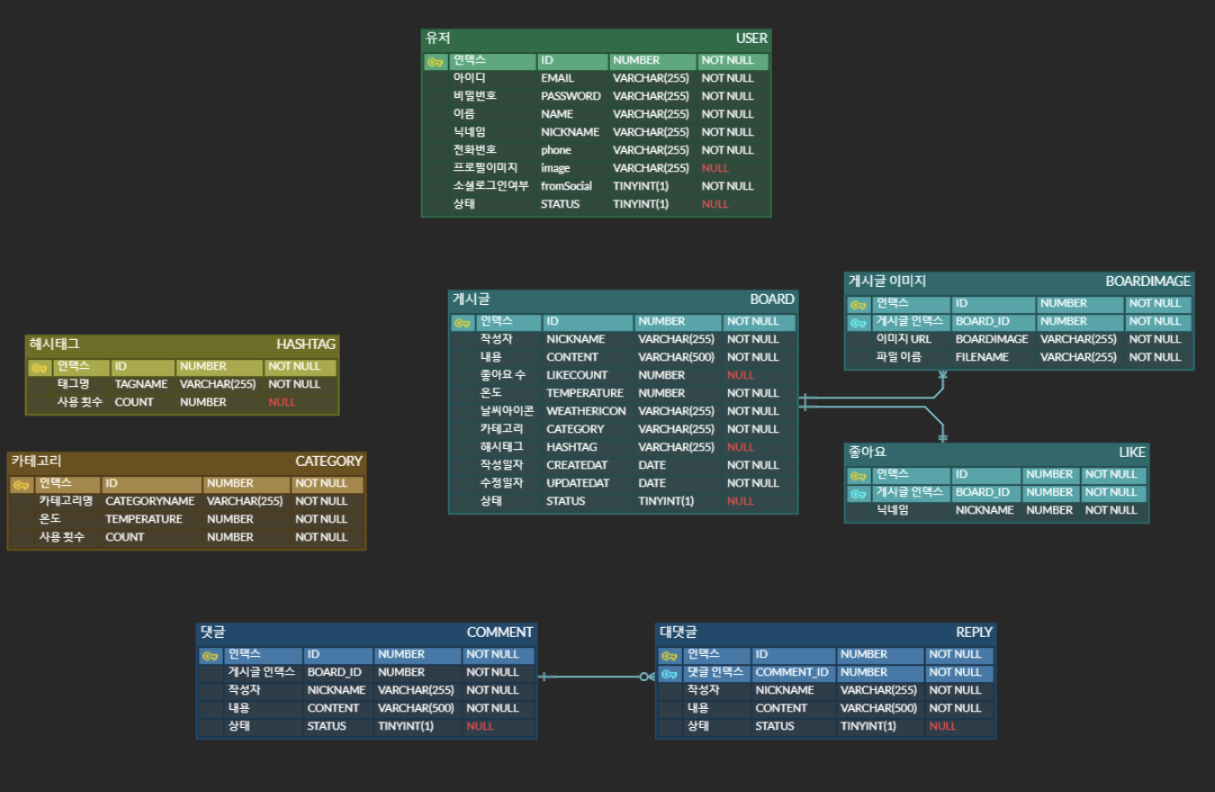
시스템 아키텍처
전체 회고
회고를 하기전, 나는 부트캠프에 합류하기 전 부터 MSA로 구축된 프로젝트를 하고싶던 욕심이 있었다. 그 욕심만큼 이전부터 조금씩 공부해보고, 테스트해보며 MSA를 구축하는데 필요한 내용들(Gateway, Eureka, Server to Server 통신 등)을 학습하였다. 모든 내용들을 다 다루기엔 꽤 많은 내용들이라 간략하게나마 작성하려 한다.
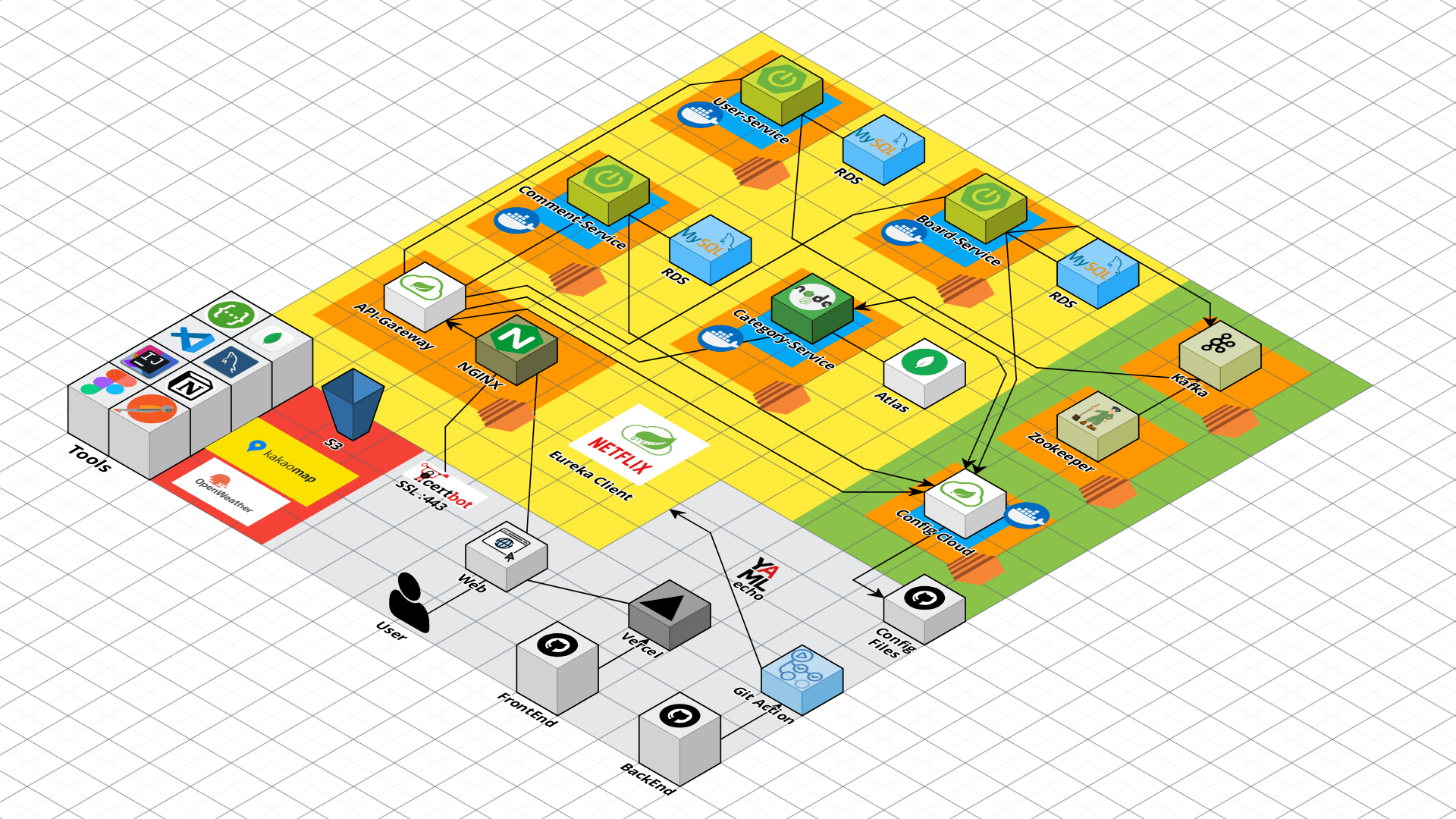
Netflix OSS를 활용한 MSA 설계와 구축
나는 Spring 진영에서 Netflix OSS인 Spring Eureka를 사용하여 프로젝트를 진행하였다.
Eureka는 Netflix에서 개발한 MSA를 위한 Cloud 오픈소스 라이브러리이다.
Eureka는 Server와 Client로 구성이 되있으며, 여기서 Client는 각각의 마이크로 서비스, Server는 Client들의 상태 정보가 등록되어 마이크로 서비스들의 상태를 확인할 수 있다.
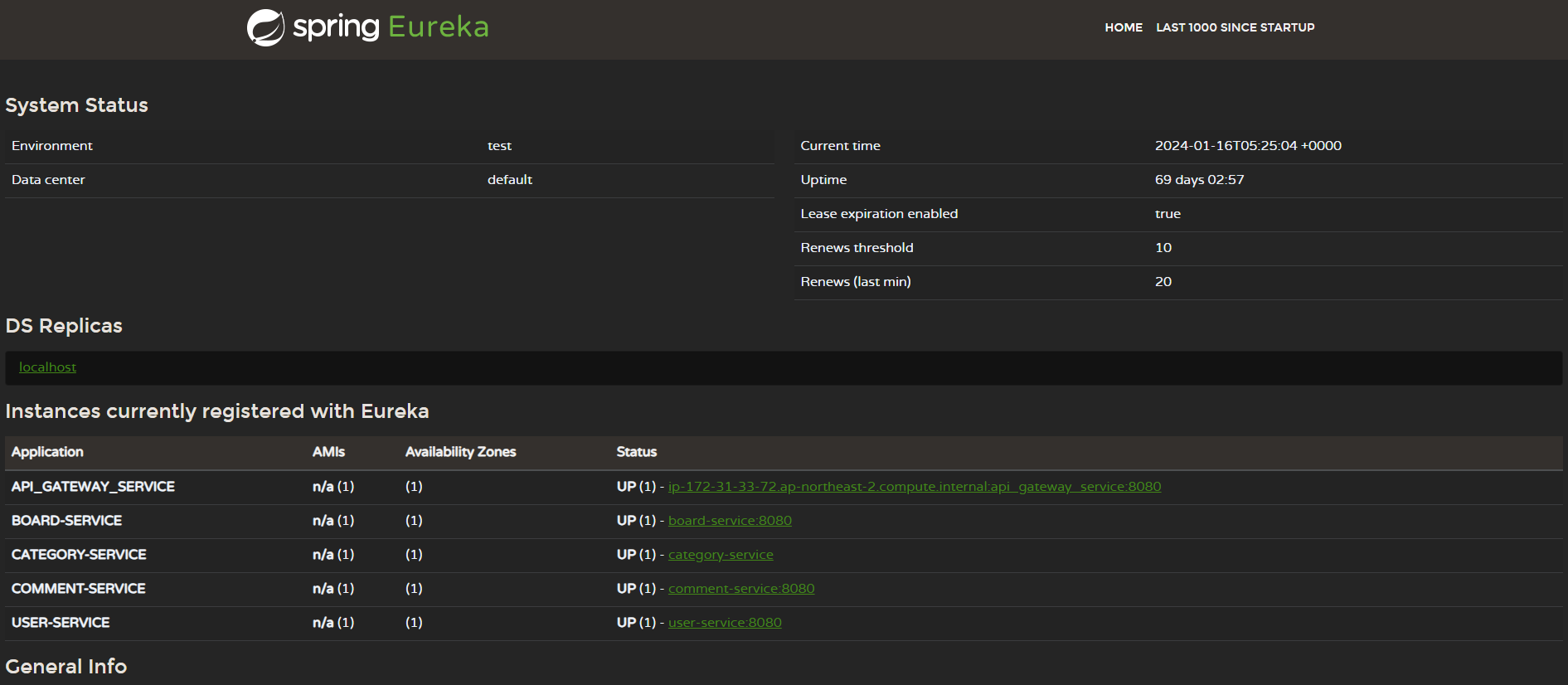 위 사진은 우리 프로젝트의 Eureka Server의 템플릿 페이지다. 보다시피 등록된 Eureka Client에는 나를 포함한 백엔드 팀원들이 개발한 각각의 서비스들이 등록되어 있다.
위 사진은 우리 프로젝트의 Eureka Server의 템플릿 페이지다. 보다시피 등록된 Eureka Client에는 나를 포함한 백엔드 팀원들이 개발한 각각의 서비스들이 등록되어 있다.
Spring API Gateway를 사용하여 요청/응답 처리
API Gateway란 클라이언트와 백엔드 서비스 사이의 리버스 프록시 역할을 하는 서비스이며, 분리되어있는 마이크로 서비스들을 공통적으로 처리하는 통신 중계역할을 한다. 위 등록된 인스턴스 중 API_GATEWAY_SERVICE가 이에 해당된다.
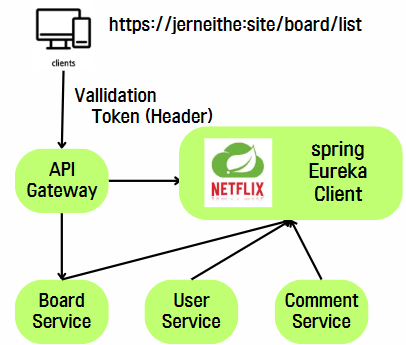 위 사진 중 클라이언트에서
위 사진 중 클라이언트에서 jerneithe.site/board/list 라는 API를 요청하는데, jerneithe.site 는 API Gateway의 도메인이다. 해당 요청을 보내면, API Gateway 서버는 Eureka Server에 등록된 Client 중 board에 해당하는 서비스를 찾아 해당 서비스로 요청을 로드밸런싱해주는 역할을 수행한다.
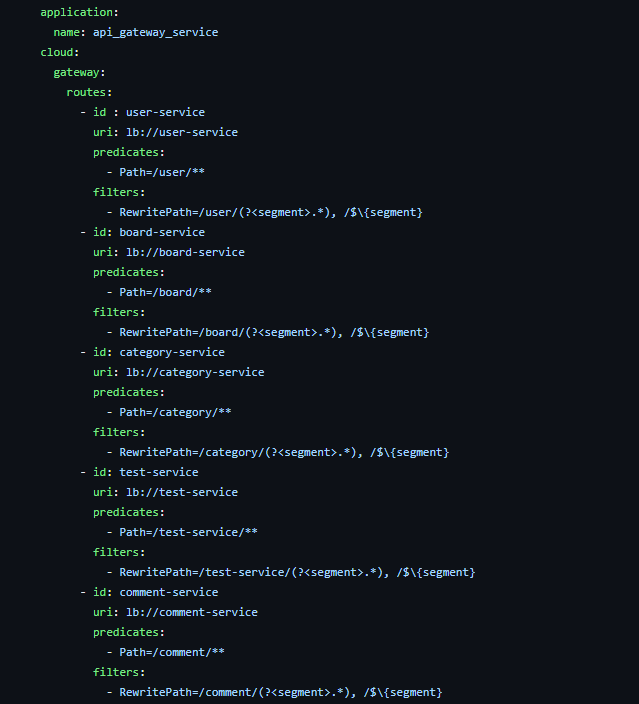 API Gateway의 application.yml을 통해 요청과 매칭되는 서비스를 찾아 해당 서비스로 로드밸런싱을 수행한다.
API Gateway의 application.yml을 통해 요청과 매칭되는 서비스를 찾아 해당 서비스로 로드밸런싱을 수행한다.
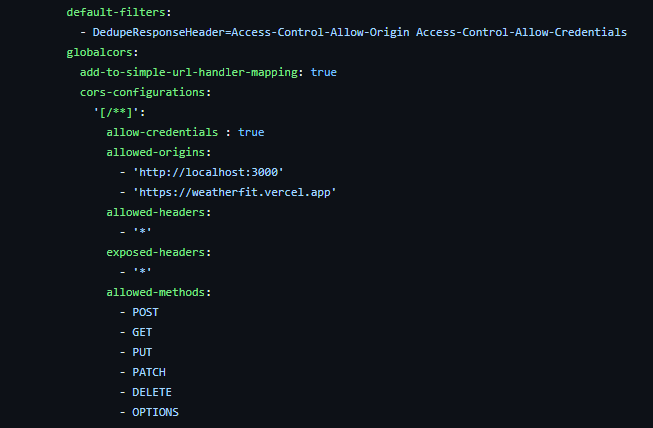 또한, 클라이언트에서 모든 요청은 이 gateway 서비스를 통해 로드밸런싱되기 때문에, gateway 서버만
또한, 클라이언트에서 모든 요청은 이 gateway 서비스를 통해 로드밸런싱되기 때문에, gateway 서버만 CORS 설정을 해주는 것만으로도 마이크로 서비스들은 따로 설정할 필요가 없어진다.
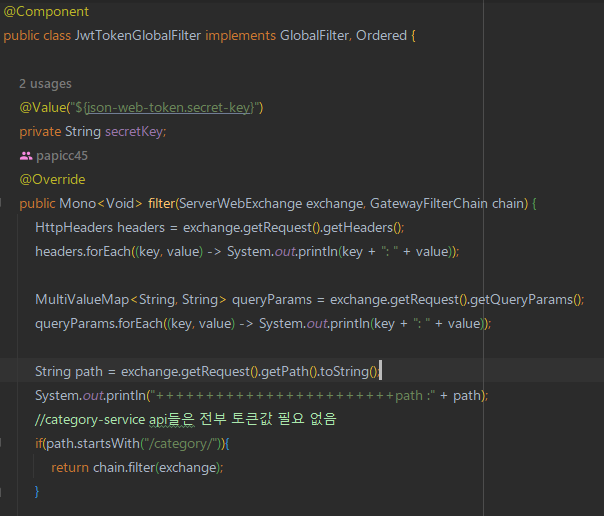
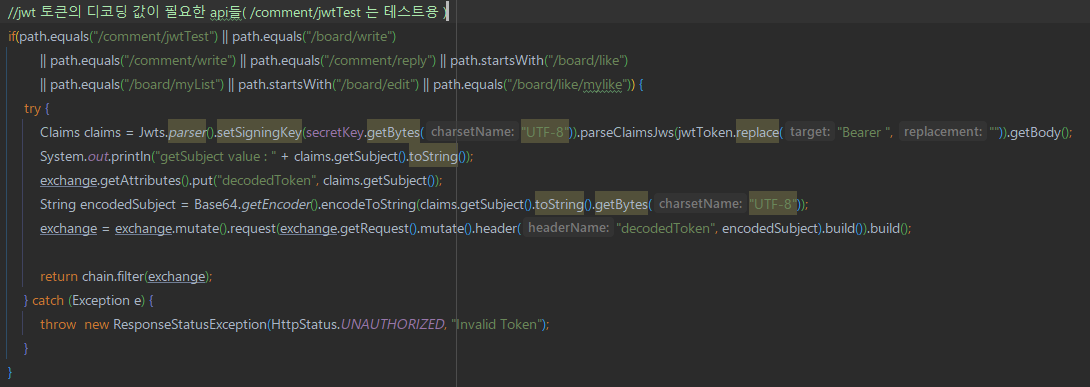 Gateway 서버에서, 모든 요청에 대한 필터를 적용시켰다. 여느 프로젝트와 마찬가지로 클라이언트에서 백엔드에 요청을 보낼 때, 권한에 대한 인증 처리를 적용해야 했는데, 중간의 Gateway 서버를 통해 요청 경로가 권한 인증이 필요없는 경우, 바로 해당 서비스로 로드밸런싱을 수행하며, 인증이 필요한 요청이 왔을 경우, 토큰값을 검증한다. 이때 토큰이 복호화된 값이 필요한 경우, 복호화까지 수행하고, 복호화된 값을 요청의 헤더에
Gateway 서버에서, 모든 요청에 대한 필터를 적용시켰다. 여느 프로젝트와 마찬가지로 클라이언트에서 백엔드에 요청을 보낼 때, 권한에 대한 인증 처리를 적용해야 했는데, 중간의 Gateway 서버를 통해 요청 경로가 권한 인증이 필요없는 경우, 바로 해당 서비스로 로드밸런싱을 수행하며, 인증이 필요한 요청이 왔을 경우, 토큰값을 검증한다. 이때 토큰이 복호화된 값이 필요한 경우, 복호화까지 수행하고, 복호화된 값을 요청의 헤더에 decodedToken 이라는 이름으로 값을 추가하여 로드밸런싱을 수행한다.
이로인해 각각의 서비스들에선 권한인증 로직을 수행하지 않아도 되고, 복호화할 필요 없이 바로 복호화된 토큰값을 사용할 수 있게 된다.
Git Action을 통한 배포자동화
저번 프로젝트때는 Jenkins를 사용하여 배포자동화를 하였다면, 이번엔 Git Action을 통해 배포자동화를 진행하였다.
Git Action을 사용한 이유는, 일단 모든 서비스가 분리되어있고, 백엔드 팀원들 각자 하나의 서비스를 구현해야하기 때문이였다. 백엔드 팀원 2명은 Git Action을 사용해본 적이 없었다. 그러나 프로젝트 초기 설계때 배포자동화 작업을 미리 적용시켜놓고 진행시키면 불필요한 작업을 최소화하고 개발에만 집중할 수 있기 때문에, 내가 직접 Git Action 템플릿을 미리 짜놓고 백엔드 팀원들에게 각각의 파이프라인을 설명해주면서 어떤 흐름으로 적용되는지 알려주면서 진행하였다.
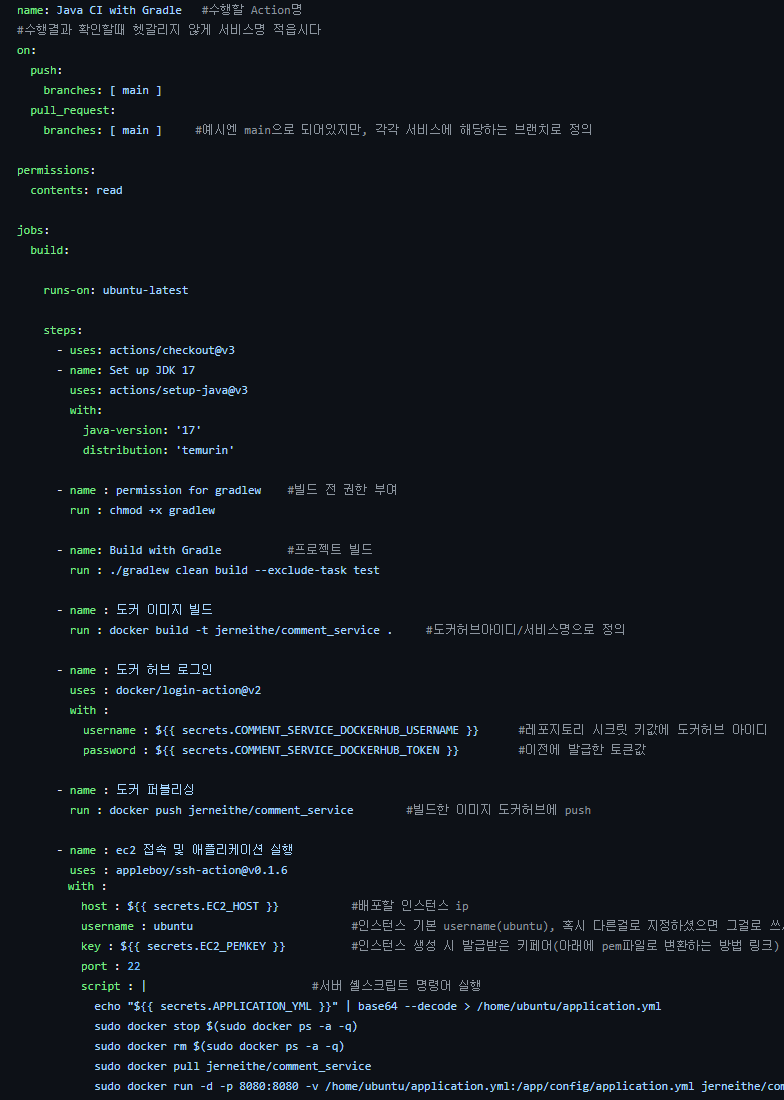 Git Action을 사용해 프로젝트 빌드 → Docker 이미지 빌드 → DockerHub에 이미지 push → EC2 접속 후 프로젝트 실행 순으로 파이프라인을 구성하였다.
Git Action을 사용해 프로젝트 빌드 → Docker 이미지 빌드 → DockerHub에 이미지 push → EC2 접속 후 프로젝트 실행 순으로 파이프라인을 구성하였다.
그런데, 레포지토리가 업데이트 될 때, gitignore 로 인해 application.yml 파일은 올라가지 않는데 수정사항이 있을경우, 직접 EC2에 접속해 코드를 수정하거나, FTP를 사용하여 파일을 옮겨주어야 한다.
이러면 사실상 Git Action을 사용하는 이유가 없어지는거 같아 방법을 찾던 중, Action Secret 값에 프로젝트의 설정파일 코드를 base64로 인코딩하여 저장 후, 파이프라인이 실행 될 때 해당 secret값을 가져와 디코딩 후 EC2 서버의 yml파일에 코드를 옮기는 방법을 선택하였다.
Spring Cloud Config를 사용해 설정파일 통합관리
프로젝트 초중반엔 위와 같은 방법으로 설정파일을 업데이트하였었다. 하지만 진행할때 설정파일에 수정사항이 생기면, 커밋하기 전에 인코딩하고 secret값을 업데이트하는 것을 까먹어서 시간이 지체되는 경우가 있었다. 이러한 문제점을 해결할 수 있는 방법을 찾던 중 Spring Cloud Config 를 발견하였다.
Spring Cloud Config 는, 간단히 말해 여러 서비스들의 설정 정보들을 중앙으로 관리하게 해주는 라이브러리이다.
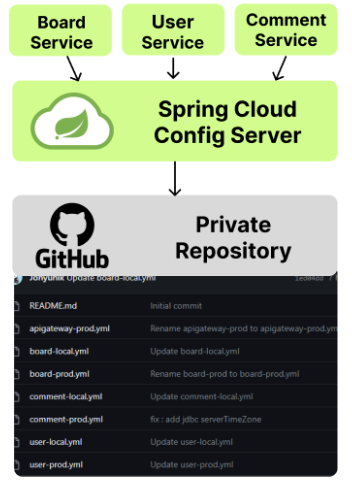 위 사진을 보면, 각각의 서비스들은 Spring Cloud Config Server를 가리키고 있고, Config Server는 Github의 레포지토리를 가리키고 있다.
위 사진을 보면, 각각의 서비스들은 Spring Cloud Config Server를 가리키고 있고, Config Server는 Github의 레포지토리를 가리키고 있다.
먼저 설정파일 코드같은 경우, 보안 이슈로 인해 레포지토리에 올라가지 않기 때문에, 설정파일들만 담을 Private 레포지토리를 따로 만들어주고, 모든 서비스들의 설정파일들을 담아준다.
그다음, spring-cloud-config-server 라이브러리를 사용한 프로젝트를 하나 생성해주고,
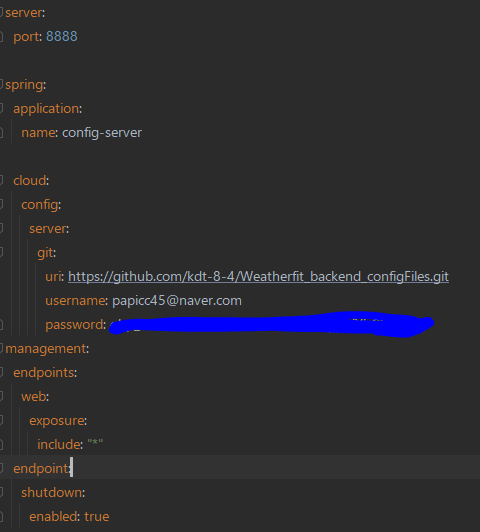 application.yml에 만든 레포지토리를 가리키기 위한 코드를 작성해준다. private한 레포지토리이기 때문에 password에 github 계정의 SSHKey값을 넣어준다. 참고로 config server는 한번만 배포해놓으면 된다.
application.yml에 만든 레포지토리를 가리키기 위한 코드를 작성해준다. private한 레포지토리이기 때문에 password에 github 계정의 SSHKey값을 넣어준다. 참고로 config server는 한번만 배포해놓으면 된다.
그리고 각각의 서비스들의 환경설정 파일을,
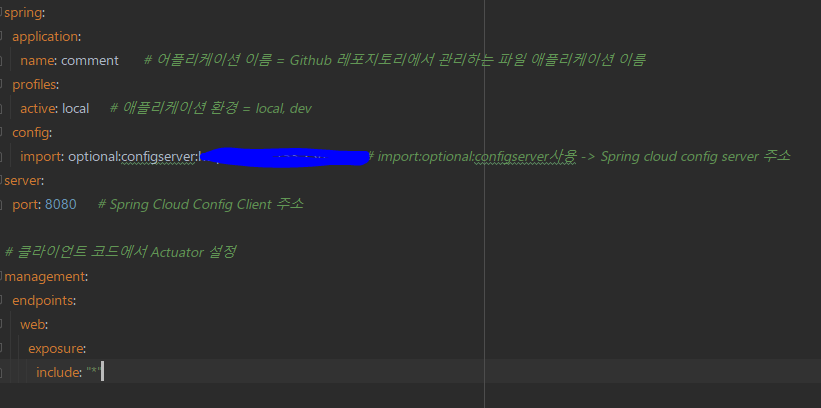 이런식으로 변경해주면 끝이다. Actuator API를 사용할 경우, 레포지토리의 변경사항을 Config Server가 탐지해 서비스들이 설정파일 수정에 대한 재배포가 필요가 없어진다.
이런식으로 변경해주면 끝이다. Actuator API를 사용할 경우, 레포지토리의 변경사항을 Config Server가 탐지해 서비스들이 설정파일 수정에 대한 재배포가 필요가 없어진다.
이렇게 되면, Action Secret값을 위 코드로 고정시키고, 수정사항이 있을 경우 설정파일이 저장되어 있는 레포지토리에서 직접 수정해주면 끝이다. 더이상 배포 전 [인코딩 → secret값 변경]을 할 필요가 없어지는 것이다.
Server To Server 통신(1) - Apache Kafka 사용
MSA 환경에서는 모든 서비스들이 분리되어있다 보니, 서버 간 데이터를 주고받기 위해 Kafka를 사용하였다.
Kafka는, 분산 시스템 환경에서 이벤트 기반 메세지 큐를 사용하여 예측할 수 없는 양의 데이터를 처리하기 위한 스트리밍 플랫폼이다.
사실 이런 프로젝트에서 Kafka를 사용하는 것은 오버스택이라 생각했지만, 그래도 이러한 환경에서 어떻게 쓰이는지, 구현하는지를 직접 사용하면서 느껴보고 싶어 학습해보고, 적용시켰다.
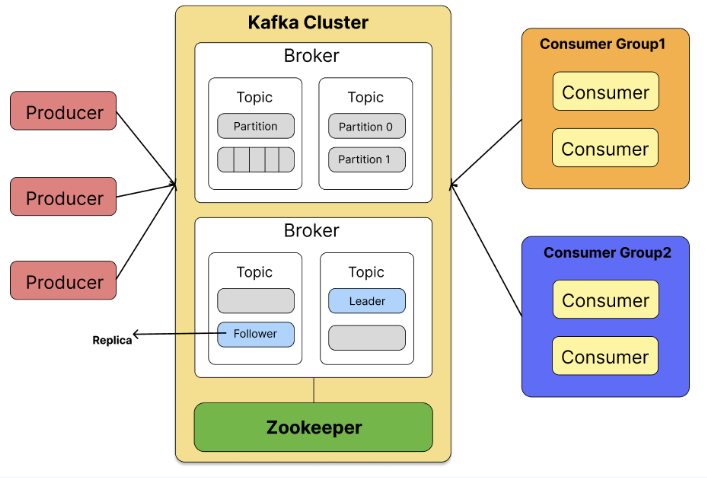 이 사진은 프로젝트 발표때 사용하려고 만들었던 Kafka 구조이다..
이 사진은 프로젝트 발표때 사용하려고 만들었던 Kafka 구조이다..
간단히 구성요소에 대해 말하자면,
Broker - Kafka 애플리케이션이 설치되어 있는 서버
Topic - 데이터를 저장하는 저장소
Producer - 데이터를 담은 메세지를 생산해 Topic으로 보내는 역할
Consumer - Broker의 Topic을 구독을 통해 메세지 데이터를 전달받는 역할
Partition - Topic을 구성하는 실제 데이터 저장소
Replica - Leader와 Follower로 구분, Leader는 실질적으로 데이터가 입출력되며, Leader 파티션의 Broker가 다운되었을 경우, Follower 파티션이 Leader 역할을 이어받음
Zookeeper - 분산 애플리케이션을 위한 코디네이션
기본적으로 분산 시스템에서의 Kafka는 여러개의 브로커를 놓고 구축하는데.. 더이상 만들 수 있는 AWS 서버가 없었기 때문에 단일브로커로 진행하였다. 우리 프로젝트에서는 Board 서비스(Spring)가 프로듀서, Category 서비스(Node)에서 컨슈머 역할을 수행하였다.
Server To Server 통신(2) - FeignClient 사용
또다른 방법으로, 역시 Netflix에서 개발한 FeignClient 를 사용하였다.
Kafka는 다른 서비스에 필요한 데이터를 줄 때 사용하였다면, feignClient는 다른 서비스에 있는 데이터가 필요할 때 사용하였다.
보통 서버에서 HTTP 요청을 보낼 경우, WebClient, RestTemplate를 주로 사용하곤 하지만, 사용하다 보면 중복되는 코드도 많고 가독성도 떨어진다. 이러한 문제를 해결하고, Eureka를 사용하는 이점을 최대한 이용하기 위해 FeignClient를 사용하였다.
FeignClient는 인터페이스와 어노테이션을 사용하여 간단하게 HttpClient를 구현할 수 있다. Spring 진영에서의 REST API 패턴을 그대로 사용할 수 있고, 가독성이 좋다.

 보다시피 인터페이스와 어노테이션만으로 간략하게 SpringMVC 패턴과 같은 HttpClient를 구현할 수 있고, 사용할 때도 구현한 메서드만 호출하면 HTTP 요청을 보낼 수 있다.
보다시피 인터페이스와 어노테이션만으로 간략하게 SpringMVC 패턴과 같은 HttpClient를 구현할 수 있고, 사용할 때도 구현한 메서드만 호출하면 HTTP 요청을 보낼 수 있다.
Layer간 DTO 매핑을 위한 MapStruct 사용
Spiring에서 Controller, Service, Repository 계층 간 데이터를 전달할 때, 보안과 더불어 불필요한 정보를 없애고 비즈니스 로직에만 집중하기 위해 DTO를 사용한다. 계층에 알맞는 DTO를 만들기 위해 Lombok의 Builder를 사용을 하거나, 클래스 내에 직접 DTO를 생성하는 메서드를 구현하는 방식을 사용해왔다. 이러한 방법들은 불필요하게 코드가 중복되거나 길어지고, 직접 구현해야하기 때문에 에러가 발생할 수 있기에 MapStruct를 사용하였다.
MapStruct란 Java Bean들 사이의 매핑을 단순화하는 라이브러리로,
런타임에서 안정성이 뛰어나고, 다른 매핑방법보다 속도가 빠르다. 또한 반복되는 객체 매핑에서의 오류를 줄이며, Annotation Processor를 이용해 객체 간 매핑을 자동으로 제공해 구현 코드를 자동으로 만들어준다.
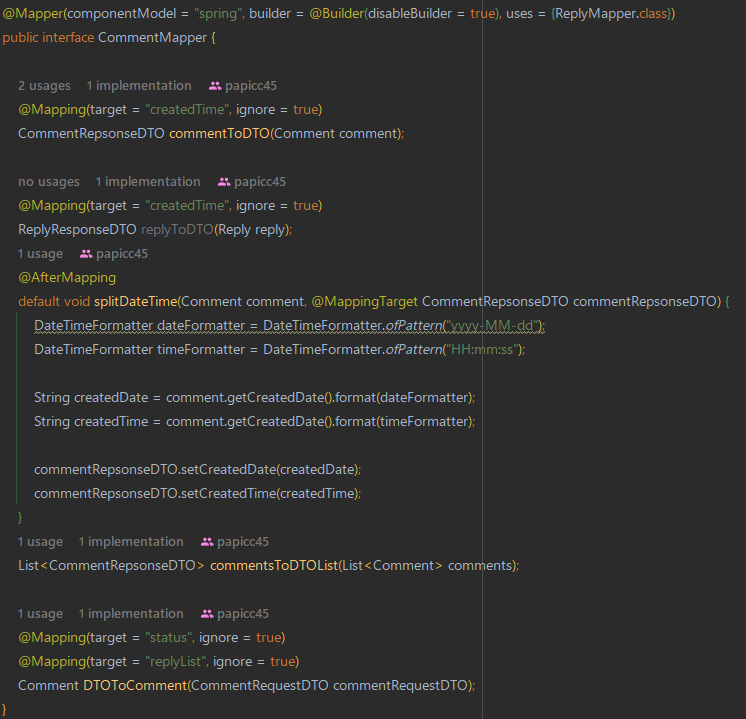 위처럼 어노테이션을 사용하여 엔티티와 DTO 간 매핑을 구현할 수 있다.
위처럼 어노테이션을 사용하여 엔티티와 DTO 간 매핑을 구현할 수 있다.
특정 컬럼을 제외하고 매핑할 수 있고, @AfterMapping처럼 매핑 결과를 바로 반환하지 않고, 원하는 대로 값들을 커스텀하여 적용 후 반환시킬 수 도 있다.(나는 날짜값을 적절한 문자열로 포매팅하는 작업을 추가하였고, 마찬가지로 @BeforeMapping을 사용해 매핑 전에도 커스텀할 수 있다.)
연관관계로 이루어져있는 컬럼도 @Mapper 어노테이션의 uses 를 사용해 해당 엔티티의 Mapper 클래스를 가져와 사용하기 때문에 연관관계 컬럼도 매핑이 가능하다.
