정규표현식의 기본 패턴
Regular Expressions Tutorial @ZVON.org
위 링크에서 참조했다.
-
정규표현식은 case-sensitive하다. (Hello ≠ hello)

-
띄어쓰기를 포함한 각각의 문자는 모두 중요하다. (Hello, world ≠ Hello, world)
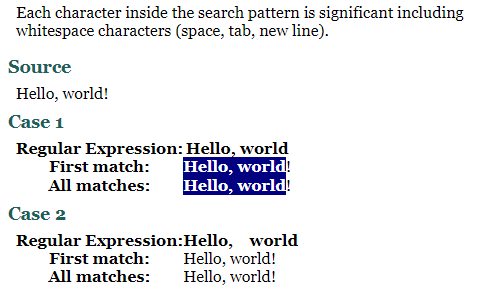
-
^는 한 줄의 시작을 의미하며, $는 한 줄의 끝을 의미한다.

-
\ 는 뒤에 오는 문자를 기능이 아닌 문자 그 자체로 받아들인다.

-
. 은 모든 문자와 대응한다.

Case 2는 6개의 덩어리씩 끊어서 본다.
-
. 은 문자로 읽기 위해서 escaped되어야 한다.

-
[ ]는 안에 든 문자들 중 하나라도 매칭된다면 찾아준다. [ ] 안에 든 것은 문자 하나이며 예를 들어 [dH].이라고 적는다면 d나 H 중 한 문자와 그 뒤 아무 문자 하나를 매칭한다.

-
[ ] 안에 - 를 사용한다면 범위를 지정할 수 있다. 예를 들어 [A-Z]라면 A부터 Z 중 하나라는 의미이다.

- [ ] 속의 ^은 not의 의미이며 [ ] 속 문자들은 선택하지 않는다는 의미이다.

- subpattern : ( ) 속 |으로 구분된 문자들 중 하나를 선택한다.

-
수량자(Quantifiers) : *, +, ?
- : * 앞의 문자가 0~n개 (있을 수도, 없을 수도) → 기준점을 b로 잡으면 편함
- : + 앞의 문자가 1~n개
- ? : ? 앞의 문자가 0 or 1개

-
*의 예시들
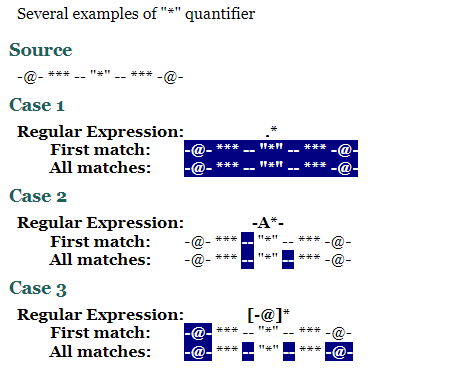
-
+의 예시들
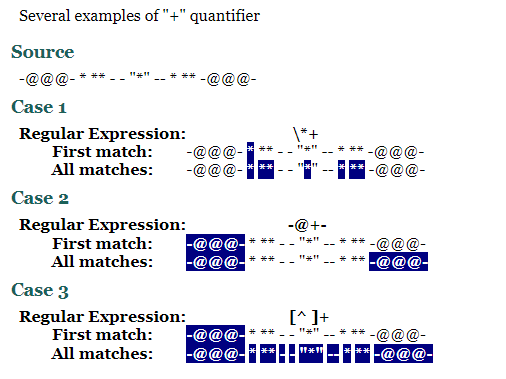
-
?의 예시들

-
{ } 안의 숫자는 { } 앞의 문자가 몇 번 나오는지 지정한다. {m}은 m번, {m,n}은 m 이상 n 이하, {m,}은 m 이상을 의미한다.

-
*, +, ? 는 { }의 특별한 형태이며 { }로 모두 표현할 수 있다.
- : {0,}
- : {1,}
- ? : {0, 1}

-
*, +, ? 뒤에 ?가 붙는다면 각각 수량자가 택할 수 있는 가장 작은 범위가 선택된다.


-
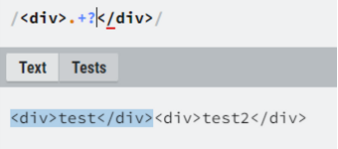
Greedy vs Lazy
-
Greedy
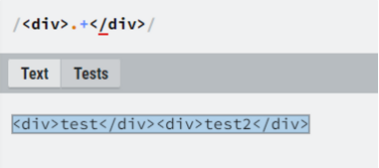
-
Lazy
-
-
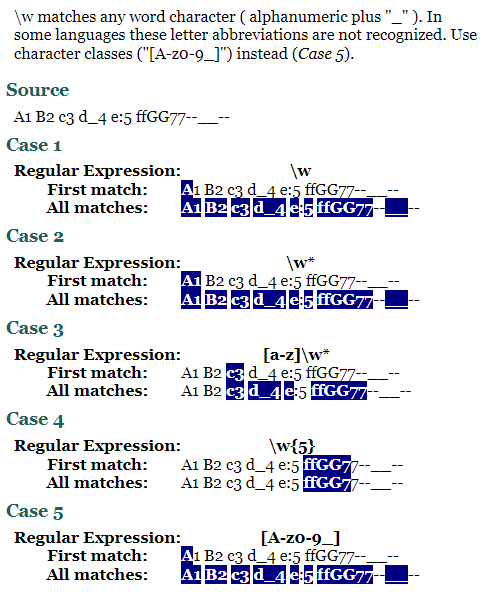
Chactacter class
- \w : 단어 (word) : 알파벳, 숫자, _
-
\W : not word → 알파벳, 숫자, _를 제외한 모두

-
\s와 \S
- \s : 공백 (space)
- \S : 공백이 아닌 것

-
\d와 \D
- \d : digit, 숫자
- \D : ~digit, 숫자가 아닌 것

-
\b는 word boundary로 단어의 경계를 나타낸다. \b\w는 단어의 경계의 첫 부분(단어의 첫 글자), \w\b는 단어의 경계의 마지막 부분(단어의 마지막 글자)를 나타낸다. \b\w{n,}\b는 알파벳 개수가 n개 이상인 단어를 나타낸다.

-
\B는 word boundary가 아닌 곳을 의미한다.

- \B.\B는 단어 바운더리가 아닌 모든 곳을 선택함
-
\A 는 단어의 시작점을 의미한다 (^와 비슷함). \Z는 단어의 마지막을 의미한다($와 비슷함).
- \A와 ^, \Z와 $의 차이 → ^와 $는 multi-line일 때 각 행의 시작/끝을 모두 찾지만 \A, \Z는 multi-line이라 하더라도 글의 첫/마지막 글자만 찾는다.

-
?=은 문자열을 검색할 때는 을 사용하지만, 선택할 때에는 을 제외한다는 의미이다.

-
?!은 문자열을 검색할 때 을 사용한 후, 이 존재하지 않는 부분만 선택한다는 의미이다.

