"코딩은 알고리즘과 자료구조, 이 두가지로 이루어진다" - 리누스 토르발스
빅오 (Big-O)
개념
빅오란 입력값이 무한대로 향할때 함수의 상한을 설명하는 수학적 표기 방법이다.
알고리즘의 효율성을 나타내는 지표이다.
-
입력값 n이 무한대를 향할 때 함수의 실행 시간의 추이를 의미한다.
- 입력의 크기가 충분히 커야 알고리즘의 효율성을 따질 수 있다. -> 수행 시간의 차이를 비교한다.
-
점근적 실행 시간(시간 복잡도)을 표기하는 방법 중 하나이다.
-
시간 복잡도란 어떤 알고리즘을 수행하는 데 걸리는 시간을 설명하는 계산 복잡도를 의미하며, 이를 표기하는 방법이 빅오다.
-
시간 복잡도를 표현할 때는 최고차항만을 비교한다.
-
-
시간 복잡도(Time Complexity): 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.
-
공간 복잡도(Space Complexity): 알고리즘이 실행될 때 사용하는 메모리의 양을 나타낸다.
일반적으로 알고리즘은 시간과 공간의 트레이드 오프 관계이다.
실행 시간이 빠르면 공간을 많이 차지하고, 공간을 적게 차지하면 실행 시간이 느리다.
빅오 표기법
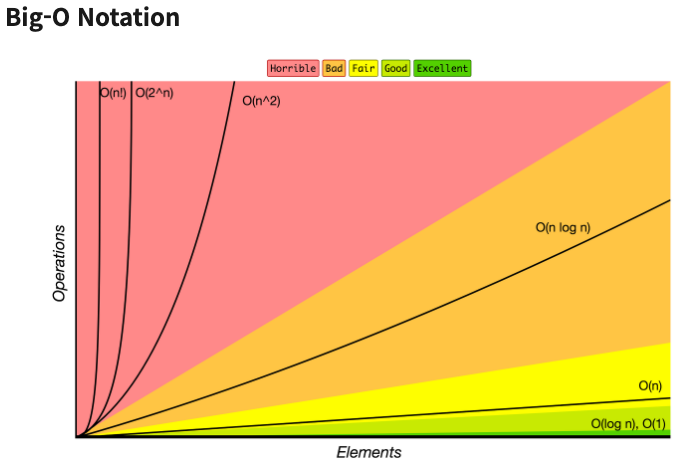
알고리즘 실행 시간의 추이에 따른 빅오 표기법의 종류는 크게 아래와 같다.
O(1)
-
입력값이 아무리 커도 실행 시간은 일정하다. 상수 시간을 갖는 것은 최고의 알고리즘이라 할 수 있다. 다만, 상수 값이 상상을 초월할 정도로 매우 크다면 의미가 없다.
-
EX) 해시 테이블의 조회 및 삽입
O(log n)
-
실행 시간은 입력값에 영향을 받는다. 그래도 log는 n값에 크게 영향을 받지 않기 때문에 입력값이 커도 견고하다.
-
EX) 이진 탐색 (binary search)
O(n)
-
실행 시간은 입력값에 비례한다. 이러한 알고리즘을 선형 시간(Linear-Time) 알고리즘이라 한다.
-
EX) 정렬되지 않은 리스트에서 최댓값 또는 최소값을 찾을때 -> 모든 입력값을 한 번 이상 확인해야한다.
O(n log n)
-
병합 정렬을 비롯해 효율좋은 정렬 알고리즘이 이에 해당한다.
-
입력값이 최선이어서 비교를 건너 뛰면 O(n)이 될 수 있다 (ex:Timesort)
-
모든 입력값을 최소 한 번 이상 비교해야 하는 비교 기반 정렬 알고리즘은 절대 이보다 빠를 수 없다.
O(n^2)
- 버블 정렬 같은 비효율적인 정렬 알고리즘이 이에 해당한다.
O(2^n)
-
피보나치 수를 재귀로 계산하는 알고리즘이 이에 해당한다.
-
n이 커질 수록 n^2와 비교했을때 2^n 값이 훨씬 크다. (ex: n=15 일때 145배 이상 차이가 난다.)
O(n!)
-
가장 느린 알고리즘으로 입력값이 조금만 커져도 계산이 어렵다.
-
각 도시를 방문하고 돌아오는 가장 짧은 경로를 찾는 외판원 문제(Travelling Salesman Problem)를 브루트 포스로 풀이하는 경우.
분할 상환 분석
빅오 표기법은 주어진 경우에 대한 수행 시간의 상한(upper bound)을 나타낸다.
-
빅오메가(하한), 빅세타(평균) 도 존재하지만 업계에선 단순화해서 빅오만 사용한다.
-
빅오 표기법은 n이 매우 클 때의 전체적인 큰 그림에 집중한다. -> 적당히 정확하게
-
최악의 경우, 평균적인 경우에 대한 시간 복잡도는 다른 개념이다.
알고리즘의 복잡도를 계산할때, 전체를 보지 않고 최악의 경우만 살펴보는 것은 지나치게 비관적이라는 이유로 분할 상환 분석 이 등장했다.
-
분할 상환 분석(Amortized Analysis)은 빅오와 함께 함수의 동작을 설명할때 중요한 분석 방법이다.
-
최악의 경우를 여러 번으로 나누는 형태로 시간 복잡도를 계산한다. -> 최악의 경우에 대한 평균
-
동적 배열의 추가연산은 최악의 경우 O(n)이고, 분할 상환 분석을하면 O(1)이 된다.
ex) 자동으로 리사이징하는 동적 배열의 공간이 꽉차는 경우엔 더블링이 일어나고 O(n)이 된다.
병렬화
일부 알고리즘은 병렬화로 실행 속도를 높일 수 있으며, 병렬화 가능 여부로 알고리즘의 우수성을 평가하기도 한다.
-
GPU는 병렬 연산을 위한 대표적인 장치이다. 각 코어는 CPU보다 훨씬 느리지만 수천여 개로 구성되어 있다.
-
같은 시간 안에 목적지까지 훨씬 더 많은 짐을 나를 수 있는 것이다.
-
딥러닝의 인기와 함께 큰 주목을 받고 있다.
자료구조 (Data structure)
개념
-
자료구조란 데이터에 편리하게 접근하고 조작하기 위한 데이터 조직, 관리, 저장주소이다.
-
자료구조의 종류에는 여러가지가 있다. 각각의 자료구조가 갖는 장점과 한계를 잘 이해하고 상황에 맞게 올바른 자료 구조를 선택하고 사용하는 것이 중요하다.
-
자료구조는 언어별로(ex. JavaScript, Python...) 지원하는 양상이 다르다.
-
각 언어가 가진 자료구조의 종류와 그것에 대한 사용 방법을 익히는 것이 중요하지만, 무엇보다 각 자료구조의 본질과 컨셉을 이해하고 상황에 맞는 적절한 자료 구조를 선택하는 것이 중요하다.
-
언어별로 지원하는 자료구조의 양상이 다르더라도 개념을 올바르게 이해한다면 해당 언어에 맞추어서 사용하기만 하면 되므로, 자료구조들의 개념과 응용 방법을 이해해야 한다.
분류
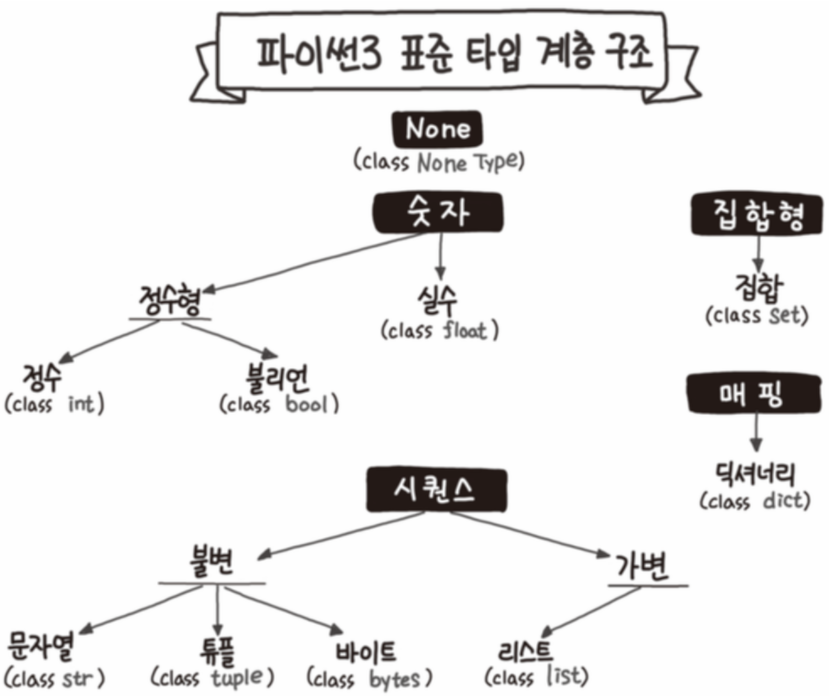
여기선 그림을 바탕으로 일반적인 자료구조 분류와 파이썬의 자료형에 대해 알아보겠다.
파이썬 자료형의 구체적인 특징과 활용법은 알고리즘 풀이를 하며 자세히 공부하려한다.
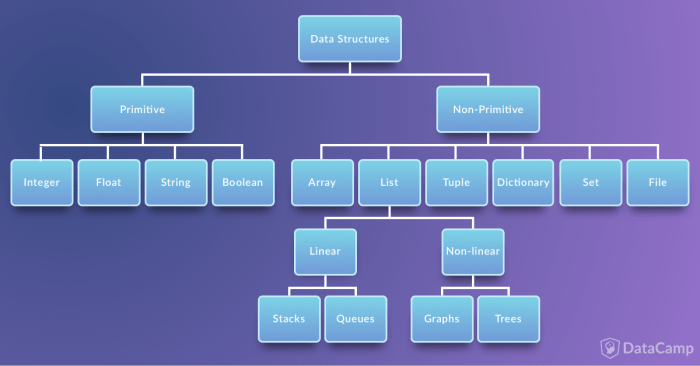
-
Primitive - -Data Structure(단순 구조)
: 프로그래밍에서 사용되는 기본 데이터 타입 -
None-Primitive Data Structure(비단순 구조)
: 단순한 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료 구조-
Linear Data Structure(선형 구조)
: 저장되는 자료의 전후 관계가 1:1 (ex. List, Stacks, Queues) -
Non-Linear Data Structure(비선형 구조)
: 데이터 항목 사이의 관계가 1:n 또는 n:m (ex. Graphs, Trees )
-
자료구조, 자료형, 추상 자료형의 구분
각 용어에 대한 정의를 알아보고 명확하게 구분하도록 하자
-
자료형 (Data Type)
-
일종의 데이터 속성(Attrubute)으로 자료구조에 비해 훨씬 더 구체적이다.
-
프로그래머가 해당 데이터를 어떻게 사용하는지 컴파일러 또는 인터프리터에게 알려주는 것이다.
-
정수, 실수, 문자열 등 해당 언어에서 지원하는 원시 자료형까지 포함한 모든 자료의 유형을 말한다.
-
-
자료구조 (Data Structure)
-
원시 자료형을 기반으로 하는 배열, 연결 리스트, 객체 등을 말한다.
-
자료형의 관점에서 여러 원시 자료형을 조합한 자료구조는 복잡 자료형이라 볼 수 있다.
-
-
추상 자료형 (Abstract Data Type)
-
해당 유형의 자료에 대한 연산들을 명기한 것으로, 자료형에 대한 수학적 모델을 지칭한다.
-
행동만 정의할 뿐 실제 구현 방법은 명시하지 않기 때문에 자료구조와 다르다.
-
OOP의 추상화처럼 인터페이스(필수 속성)만 보여주고 실제 구현(불필요한 정보)은 감추는 개념이다.
-
- 참고자료
도서 : 파이썬 알고리즘 인터뷰
알고리즘의 기초 Big-O Notation과 복잡도(Complexity)
알고리즘의 시간 복잡도와 Big-O 쉽게 이해하기
