

ProductView
GET요청으로 Query Parameter를 보내면 해당하는 상품 목록을 전송해주자
- 하나의 view로 라우팅했다.

카테고리별 목록과 베스트셀러 목록
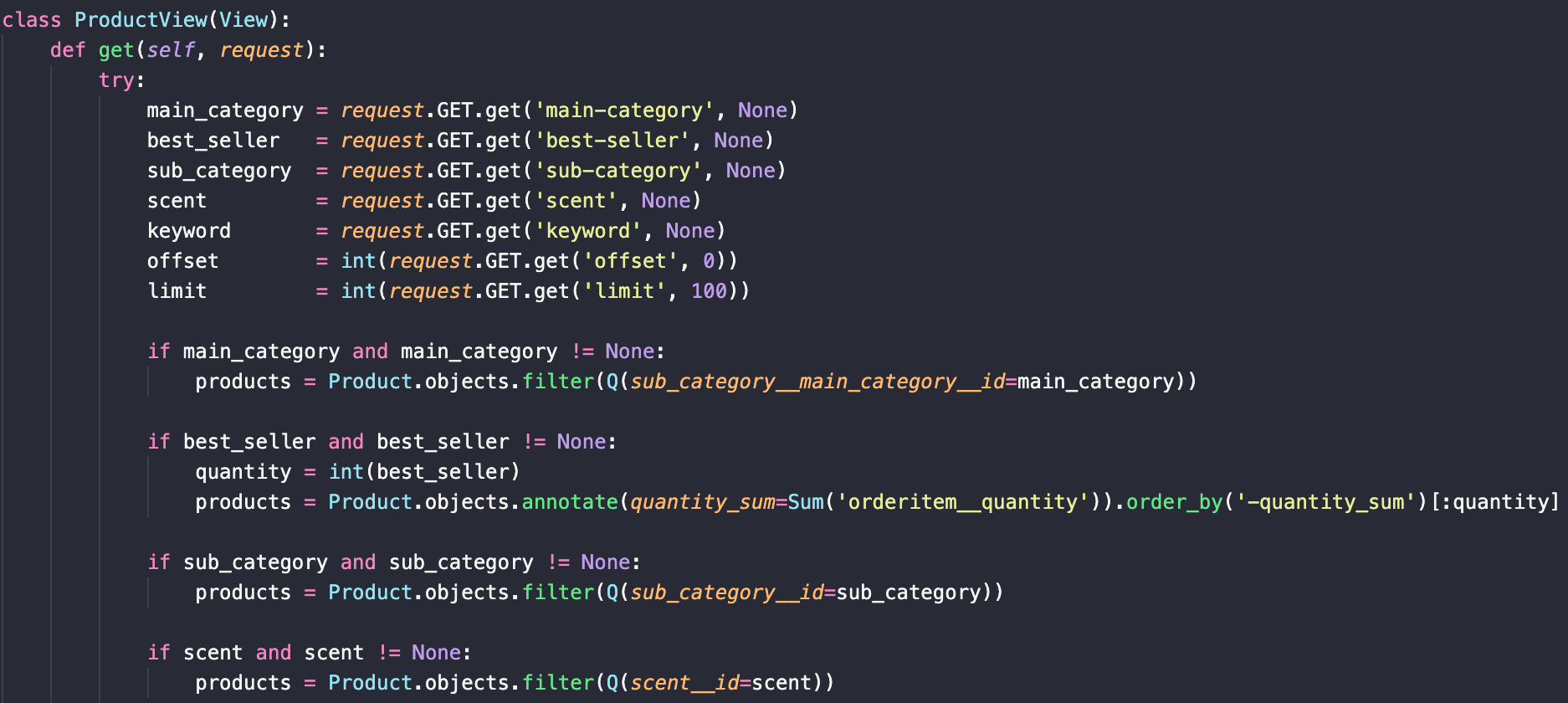
메인카테고리, 서브카테고리, 향은 쿼리 파라미터로 들어오는 아이디 값에 따라 해당하는 상품들을 보내준다.
request.GET.get('(파라미터 키)', None)이런식으로 쿼리 파라미터의 값을 가져와서 해당 값으로 filter 조건을 만든다.
- 처음엔 참조방향에만 신경쓰느라 카테고리로부터 해당 상품을 찾기위해 역참조와 for문을 남발했다.
- Django making queries 를 보면 SQL 조건절을 만들기위한 field lookup들이 나와있다.
이것을 쿼리셋 메소드안에 인자로 넣어서 사용한다.
field__lookuptype=value. (That’s a double-underscore)
- QuerySet API reference 를 보면 다양한 필드 룩업 타입이 예시와 함께 나와있으며,
contains,gte,lte,start_with등이 있다.
베스트셀러는 파라미터 값에 따라 해당하는 갯수만큼 상위 판매 상품 목록을 보내준다.
- 각 상품마다 판매량 합계를 구해서, 내림차순으로 정렬하고 파라미터 값만큼 slice한다.
- 각 상품마다 order_item 테이블에 접근해서 quantity를 모두 더해야 한다. 더한 값을 넣어줄 컬럼이나 테이블이 없기 때문에
annotate를 활용해 가상의 컬럼을 만든다.
(엑셀의 부분합계 테이블을 생각하면 된다.)
annotate컬럼의 이름은 quantity_sum으로 했고 django.db.models의 Aggregation fuction 중 Sum을 이용해 판매수량 합계를 구했다.
- quantity_sum 컬럼을 내림차순 정렬해서 원하는만큼 상품 정보를 보낼 수 있었다.
- 생각해볼점
결국 DB에서 원하는 데이터를 찾기위해선 SQL 조건절을 만들어 보내야 한다.
복잡한 조건이라고 해서 반드시 여러개의 쿼리문을 작성해야 하는 것은 아니다.
상품명 검색

쿼리 파라미터로 받은 검색 키워드가 상품명이나 컬렉션명에 포함되는 경우 상품 목록을 보내준다.
- 조건 : 받아온 키워드가 상품의 name과 collection에 포함된다.
- 상품명 또는 콜렉션명에 포함 여부를 확인하기 때문에
or연산을 해야한다. 하지만 원래 filter 메소드는 안되기 때문에 Q객체를 이용해|으로or연산이 가능하다.
- Q 객체는 Query-related tool 중 하나이며, 조건을 정의하고 재사용할 수 있게 하고 | (OR) 및 & (AND)와 같은 연산자를 사용하여 결합하게 해준다.
SQL의 where 절에 or, and, not 을 추가하고 싶을때 쓴다. 조건을 덩어리화해서 add로 Q끼리 연결할수도 있다.
__icontains필드 룩업을 사용해 대소문자 구별없이 키워드 포함 상품을 찾는다.
- 생각해볼점
Q 객체를 여러번 사용하거나 복잡해졌을때 변수화하여 사용하는 경우를 보았다.
F 객체는 모델 필드의 값이나 annotated 된 컬럼의 값을 대표한다고 하는데 더 알아보자.
페이지네이션
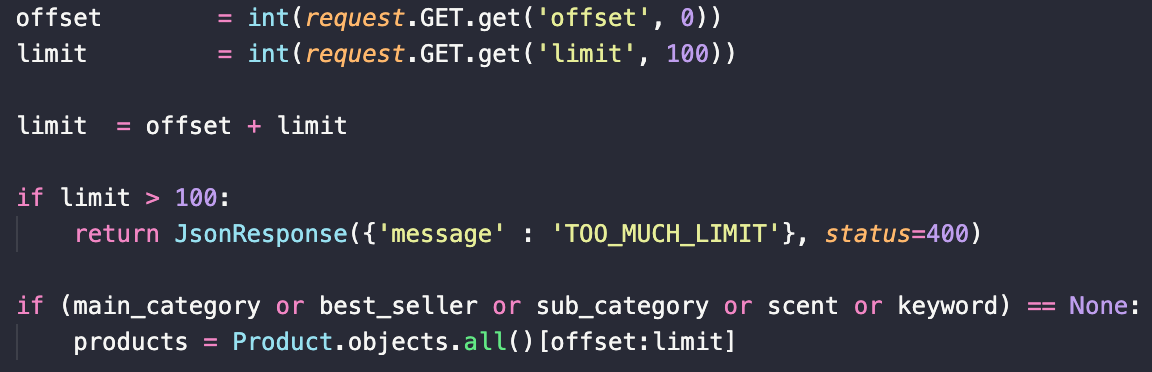
OFFSET과 LIMIT을 이용해 DB에서 전송해주는 데이터의 양을 조절한다.
- 전체 상품을 요청한다고해서 DB의 모든 정보를 보내줄 순 없다. 일반적으로 limit을 100으로 두며 프론트엔드의 UI 계획에 따라 offset과 limit을 정해서 요청하도록 한다.
- Django의 Paginator를 import해서 적용할수도 있지만 기본적으로 offset, limit값을 쿼리 파라미터로 받을 수 있도록 했다.
- offset=10, limit=10 으로 요청했다면 10번째 상품부터 10개를 보내달라는 뜻이다. 그러면 상품번호 기준으로 10번부터 19번까지 보내주는 로직이다.
- 생각해볼점
전통적으로 오프셋 방식을 사용해왔지만, 이제는 Cursor-Based 방식을 주로 사용한다고 한다.
특히 SNS처럼 스크롤이 되는 상황에서 성능 및 효율성 측면에서 이점이 많다고 하니 더 알아보자.
ProductDetailView
product_id를 path parameter로 받으면 해당 상품의 상세정보를 전송한다.
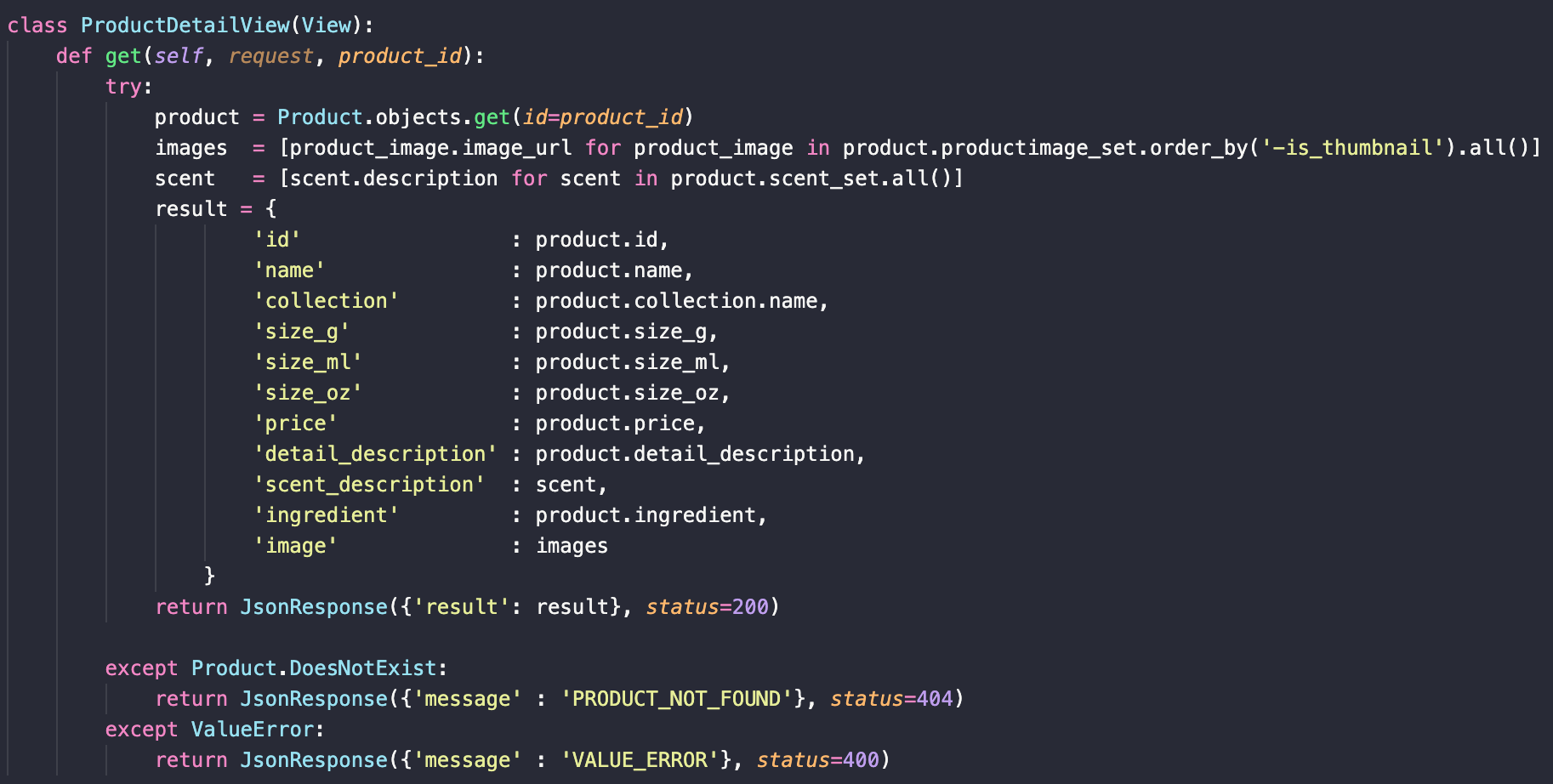
- 하나의 상품은 여러개의 이미지와 향을 가질 수 있다. 따라서 product 테이블에서 역참조로 image와 scent에 접근했고 배열에 담기 위해 for문을 사용했다.
- image 테이블에는 is_thumbnail 불리언 컬럼이 있는데 썸네일 이미지를 가장 앞에 오도록 내림차순 정렬했다. (MySQL에는 불리언타입을 0과 1로 저장한다.)
- 생각해볼점
아무리봐도 images와 scent 정보를 가져오는 방식이 찝찝하다. Lazy loading과 Eager loading의 개념을 이용해 prefetch_related를 사용해볼 수 있는 케이스 일 것 같다.
느낀점
-
정참조, 역참조로 데이터에 접근하는 것은 익숙해졌지만, 이제 테이블 조인이나 서브 쿼리를 만들어 성능을 최적화하는 법을 익혀야겠다. 어떤 경우에 왜 성능에 문제가 있는지 조금씩 느낌이 오고 있다.
-
처음엔 필터링마다 class를 작성해야하나 고민했으나, 2개의 class로 위 기능을 모두 수행할 수 있다는 것을 알았다. 쿼리 파라미터와 패스 파라미터를 적절히 이용한다면 2개의 url 라우팅만으로도 위 기능 구현이 가능했다.
-
쿼리셋 method뿐만 아니라 Q객체, F객체, Field lookup, Aggregation function 등 Django가 제공하는 다양한 기능에 더 익숙해져야겠다.
-
성능면에서 일반적인 for문보다 List Comprehension이 더 좋다는 내용을 보았는데, dis.dis를 이용해 python의 바이트코드를 보는 과정이 흥미로웠다. 이 부분을 더 공부해서 python의 작동 원리를 이해하고, python의 장점을 더 극대화해서 코드를 작성하고 싶다.
-
기능이 작동하게 만드는 것은 당연한거고, 어떠한 상황에서도 잘 작동하게 성능을 높이는 것을 목표로 해야겠다.
