
객체지향 프로그래밍
객체지향 언어의 역사
객체지향이론의 기본개념은 실제 세계는 사물(객체)로 이루어져 있으며, 발생하는 모든 사건들은 사물간의 상호작용이다.라는 것이다. 실제 사물의 속상과 기능을 분석한 다음, 데이터(변수)와 함수로 정의함으로써 실제 세계를 컴퓨터 속에 옮겨놓은 것과 같은 가상 세계를 구현하고 이 가상세계에서 모의실험을 함으로써 많은 시간과 비용을 절약할 수 있었다.
객체지향언어의 특징
- 코드의 재사용성이 높다
- 새로운 코드를 작성할 때 기존의 코드를 이용하여 쉽게 작성할 수 있다.
- 코드의 관리가 용이하다
- 코드간의 관계를 이용해서 적은 노력으로 쉽게 코드를 변경할 수 있다.
- 신뢰성이 높은 프로그래밍을 가능하게 한다.
- 제어자와 메서드를 이용해서 데이터를 보호하고 올바른 값을 유지하도록 하며, 코드의 중복을 제거하여 코드의 불일치로 인한 오동작을 방지할 수 있다.
클래스와 객체
클래스와 객체의 정의와 용도
클래스란란 객체를 정의해놓은 것 또는 클래스는 객체의 설계도 또는 틀이라고 정의할 수 있다.
클래스의 정의 : 클래스란 객체를 정의해 놓은 것이다.
클래스의 용도 : 클래스는 객체를 생성하는데 사용된다.
객체의 사전적 정의는 실제로 존재하는 것이다.
객체의 정의 : 실제로 존재하는 것. 사물 또는 개념
객체의 용도 : 클래스는 객체를 생성하는데 사용된다.유형의 객체 : 책상, 의자, 자동차, TV와 같은 사물
무형의 객체 : 수학공식, 프로그램 에러와 같은 논리와 개념
| 클래스 | 객체 |
|---|---|
| 제품 설계도 | 제품 |
| TV 설계도 | TV |
| 붕어빵 기계 | 붕어빵 |
클래스 한번만 잘 만들어 놓기만 하면, 매번 객체를 생성할 때마다 어떻게 객체를 만들어야 할지를 고민하지 않아도 된다. 그냥 클래스로부터 객체를 생성해서 사용하기만 하면 되는 것이다.
객체와 인스턴스
클래스로부터 객체를 만드는 과정을 클래스의 인스턴스화(instantiate)라고 하며, 어떤 클래스로부터 만들어진 객체를 그 클래스의 인스턴스(instance)라고 한다.
객체의 구성요소
속성(Property) : 멤버변수(member variable), 특성(attribute), 필드(field), 상태(state)
기능(function) : 메서드(method), 함수(function), 행위(behavior)
인스턴스의 생성과 사용
클래스명 변수명; // 클래스의 객체를 참조하기 위한 참조변수를 선언
변수명 = new 클래스명(); // 클래스의 객체를 생성 후, 객체의 주소를 참조변수에 저장
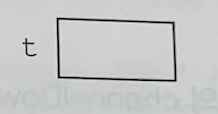
Tv t; // Tv 클래스 타입의 참조변수 t를 선언
t = new Tv(); // Tv 인스턴스를 생성한 후, 생성된 Tv인스턴스의 주소를 t에 저장Class Tv {
String color;
boolean power;
int channel;
void power() { power = !power; }
void channelUp() { ++channel; }
void channelDown() { --channel; }
}
class TvTest {
public static void main(String args[]) {
Tv t;
t = new Tv();
t.channel = 7;
t.channelDown();
System.out.println("현재 채널은 " + t.channel + " 입니다.");
}
}- Tv t;
Tv 클래스 타입의 참조변수 t를 선언한다. 메모리에 참조변수 t를 위한 공간이 마련된다. 아직 인스턴스가 생성되지 않았으므로 참조변수로 아무것도 할 수 없다.
- t = new Tv();
연산자 new에 의해 Tv클래스의 인스턴스가 메모리의 빈 공간에 생성된다. 주소가 0x100인 곳에 생성되었다고 가정하자. 이 때, 멤버변수는 각 자료형에 해당하는 기본값으로 초기화 된다.
color는 참조형이므로 null로, power는 boolean이므로 false로, 그리고 channel은 int이므로 0으로 초기화 된다.

그 다음에 대입연산자(=)에 의해서 생성된 객체의 주소값이 참조변수 t에 저장된다. 이제는 참조변수 t를 통해 Tv인스턴스에 접근할 수 있다. 인스턴스를 다루기 위해서는 참조변수가 반드시 필요하다.

-
t.channel = 7;
참조변수 t에 저장된 주소에 있는 인스턴스의 멤버변수 channel에 7을 저장한다. 여기서 알 수 있는 것처럼, 인스턴스의 멤버변수 (속성)를 사용하려면참조변수.멤버변수와 같이 하면 된다. -
t.channelDown();
참조변수 t가 참조하고 있는 Tv인스턴스의 channelDown메소드를 호출한다. channel Down메서드는 멤버변수 channel에 저장되어 있는 값을 1 감소시킨다.
void channelDown () { --channel; }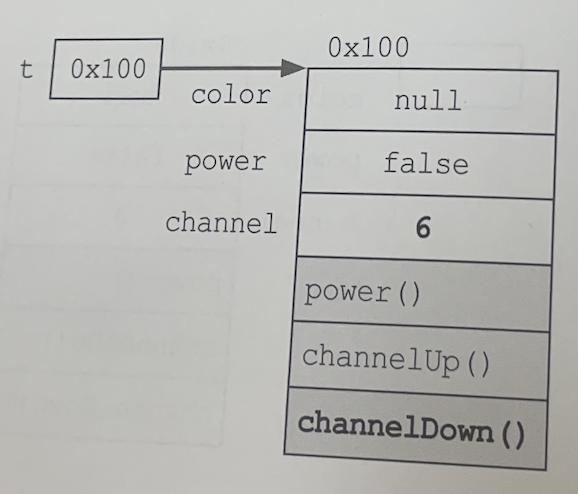
인스턴스는 참조변수를 통해서만 다룰 수 있으며, 참조변수의 타입은 인스턴스의 타입과 일치해야 한다.
객체 배열
많은 수의 객체를 다뤄야할 때, 배열로 다루면 편리할 것이다. 객체 역시 배열로 다루는 것이 가능하며, 이를 객체 배열이라고 한다.
Tv[] tvArr = new Tv[3]; // 참조변수 배열(객체 배열)을 생성
// 객체를 생성해서 배열의 각 요소에 저장
tvArr[0] = new Tv();
tvArr[1] = new Tv();
tvArr[2] = new Tv();
// 배열의 초기화 블럭을 사용함
Tv[] tvArr = { new Tv(), new Tv(), new Tv() };클래스의 또 다른 정의
클래스는 객체를 생성하기 위한 틀이며 클래스는 속성과 기능으로 정의되어있다
프로그래밍언어에서 데이터 처리를 위한 위한 데이터 저장형태의 발전과정은 다음과 같다.
1. 변수 하나의 데이터를 저장할 수 있는 공간
2. 배열 같은 종류의 여러 데이터를 하나의 집합으로 저장할 수 있는 공간
3. 구조체 서로 관련된 여러 데이터를 종류에 관계없이 하나의 집합으로 저장할 수 있는 공간
4. 클래스 데이터와 함수의 결합(구조체 + 함수)
변수와 메서드
선언 위치에 따른 변수의 종류
변수는 클래스변수, 인스턴스변수, 지역변수 모두 세 종류가 있다. 변수의 종류를 결정짓는 중요한 요소는 변수의 선언된 위치이므로 변수의 종류를 파악하기 위해서는 변수가 어느 영역에 선언되었는지를 확인하는 것이 중요하다.
멤버 변수를 제외한 나머지 변수들은 모두 지역변수이며, 멤버변수 중 static이 붙은 것은 클래스 변수, 붙지 않은 것은 인스턴스 변수이다.
class Variables { // 클래스 영역
int iv; // 인스턴스 변수
static int cv; // 클래스 변수 (static 변수, 공유변수)
void method() { // 메서드 영역
int lv = 0; // 지역변수
}
}| 변수의 종류 | 선언 위치 | 생성 시기 |
|---|---|---|
| 클래스변수 (class variable) | 클래스 영역 | 클래스가 메모리에 올라갔을때 |
| 인스턴스변수 (instance variable) | 클래스 영역 | 인스턴스가 생성되었을 때 |
| 지역변수 (local variable) | 클래스 영역 이외의 영역 (메서드, 생성자, 초기화 블럭 내부) | 변수 선언문이 수행되었을 때 |
인스턴스변수는 인스턴스가 생성될 때 마다 생성되므로 인스턴스마다 각기 다른 값을 유지할 수 있지만, 클래스 변수는 모든 인스턴스가 하나의 저장공간을 공유하므로, 항상 공통된 값을 갖는다.
메서드
메서드(method)는 특정 작업을 수행하는 일련의 문장들을 하나로 묶은 것이다.
메서드를 사용하는 이유
-
높은 재사용성(reusability)
이미 자바 API에서 제공하는 메서드들을 사용하면서 경험한 것처럼 한번 만들어 놓은 메서드는 몇 번이고 호출할 수 있으며, 다른 프로그램에서도 사용이 가능하다. -
중복된 코드의 제거
-
프로그램의 구조화
메서드의 선언과 구현
메서드는 크게 두 부분, 선언부(header)와 구현부(body)로 이루어져 있다. 메서드를 정의한다는 것은 선언부와 구현부를 작성하는 것을 뜻한다.
메서드 선언부는 메서드의 이름 매개변수 선언, 그리고 반환타입으로 구성되어 있다.
int add (int x, int y) {
int result = x + y;
return result; // 결과를 반환
}여기서 int가 반환타입(출력), add가 메서드 이름, int x, int y가 매개변수 선언이다.
메서드 내에 선언된 변수들은 그 메서드 내에서만 사용할 수 있으므로 서로 다른 메서드라면 같은 이름의 변수를 선언해도 된다. 이처럼 메서드 내에 선언된 변수를 지역 변수라고 한다.
메서드의 호출
메서드이름(값1, 값2, ...);
print99danAll();
helloWorldPrint();
int result = add(3, 5);JVM의 메모리 구조
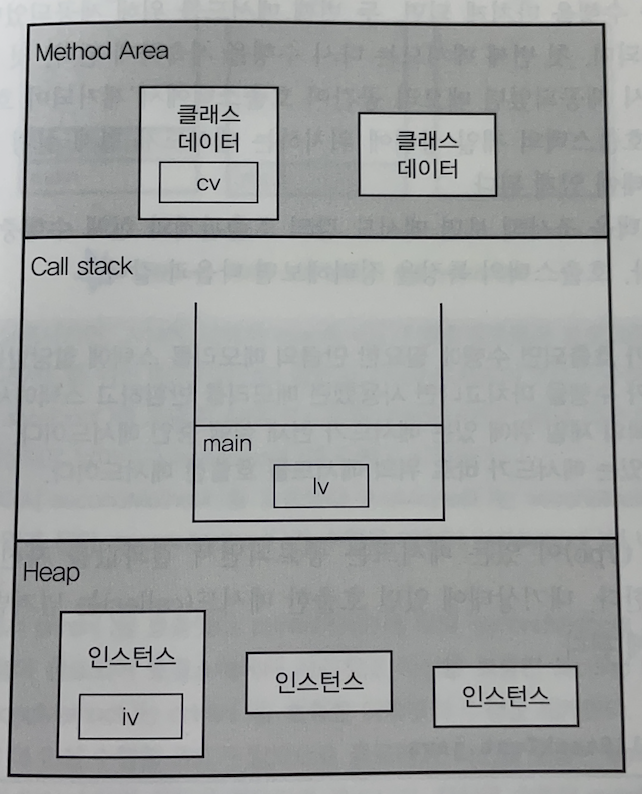
응용프로그램이 실행되면 JVM은 시스템으로부터 프로그램을 수행하는데 필요한 메모리를 할당받고 JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
-
메서드 영역(method area)
프로그램 실행 중 어떤 클래스가 사용되면, JVM은 해당 클래스의 클래스파일(*.class)을 읽어서 분석하여 클래스에 대한 정보(클래스 데이터)를 이곳에 저장한다. 이 때, 그 클래스의 클래스변수(class variable)도 이 영역에 함께 생성된다. -
힙(heap)
인스턴스가 생성되는 공간. 프로그램 실행 중 생성되는 인스턴스는 모두 이곳에 생성된다. 즉, 인스턴스변수 (instance variable)들이 생성되는 공간이다. -
호출스택(call stack 또는 execution stack)
호출스택은 메서드의 작업에 필요한 메모리 공간을 제공한다. 메서드가 호출되면, 호출스택에 호출된 메서드를 위한 메모리가 할당되며 이 메모리는 메서드가 작업을 수행하는 동안 지역변수 (매개변수 포함)들과 연산의 중간결과 등을 저장하는데 사용한다. 그리고 메서드가 작업을 마치면 할당되었던 메모리 공간은 반환되어 비워진다.
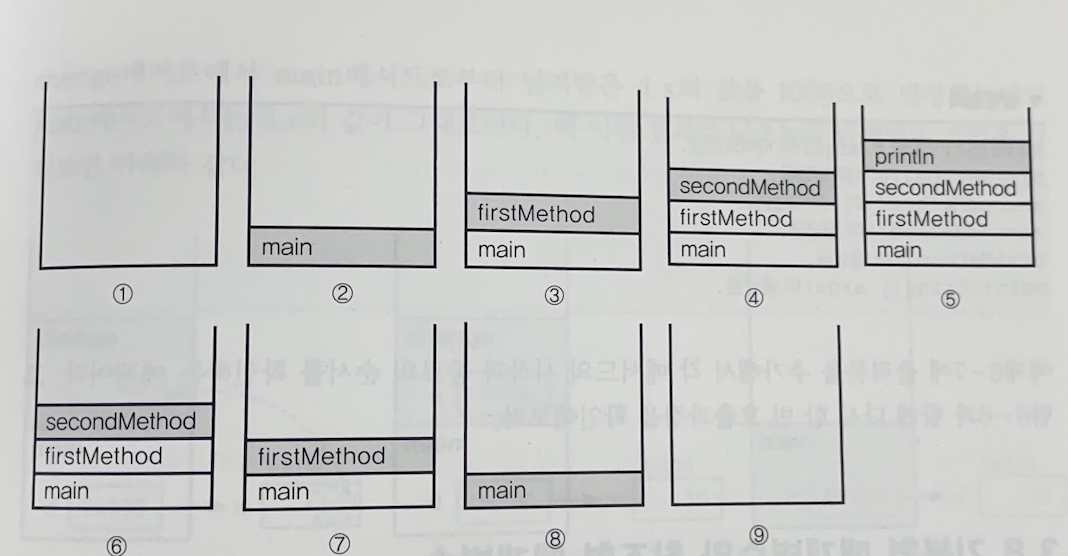
class StackTest {
public static void main(String args[]) {
firstMethod(); // static메서드는 객체 생성없이 호출가능하다.
}
static void firstMethod() {
secondMethod();
}
static void secondMethod() {
System.out.println("secondMethod()");
}
}위 코드 실행 시 호출 스택의 변화
기본형 매개변수와 참조형 매개변수
메서드의 매개변수를 기본형으로 선언하면 단순히 저장된 값을 얻지만, 참조형으로 선언하면 값이 저장된 곳의 주소를 알 수 있기 때문에 값을 읽어 오는 것은 물론 값을 변경하는 것도 가능하다.
기본형 매개변수: 변수의 값을 읽기만 할 수 있다.(readonly)
참조형 매개변수: 변수의 값을 읽고 변경할 수 있다.(read & write)
참조형 반환타입
매개변수 뿐만 아니라 반환타입도 참조형이 될 수 있다. 반환타입이 참조형이라는 것은 반환하는 값의 타입이 참조형이라는 얘긴데, 모든 참조형 타입의 값은 객채의 주소이므로 그저 정수값이 반환되는 것일 뿐 특별할 것이 없다.
class Data { int x; }
class Example {
public static void main(String args[]) {
Data d = new Data();
d.x = 10;
Data d2 = conpy(d);
System.out.println(d.x); // 10
System.out.println(d2.x); // 10
}
static Data copy(Data d) {
Data tmp = new Data();
tmp.x = d.x;
return tmp;
}
}copy메서드를 호출하면서참조변수 d의 값이매개변수 d에 복사된다.- 새로운 객체를 생성한 다음,
d.x에 저장된 값을tmp.x에 복사한다. copy메서드가 종료되면서 반환한tmp의 값은참조변수 d2에 저장된다.copy메서드가 종료되어tmp가 사라졌지만d2로 새로운 객체를 다룰 수 있다.
반환타입이
참조형이라는 것은 메서드가객체의 주소를 반환한다는 것을 의미한다.
재귀호출(recursive call)
메서드의 내부에서 메서드 자신을 다시 호출하는 것을 재귀호출이라고 하고, 재귀호출을 하는 메서드를 재귀 메서드라 한다.
void method() {
method(); // 재귀호출. 메서드 자신을 호출한다.
}위의 코드처럼 재귀호출뿐이면, 무한히 자기 자신을 호출하기 때문에 무한반복에 빠지게 된다. 무한반복문이 조건문과 함께 사용되어야하는 것처럼, 재귀호출도 조건문이 필수족으로 따라다닌다.
void method(int n) {
if (n == 0) return; // n의 값이 0일 때, 메서드를 종료
System.out.println(n);
method(--n); // 재귀호출. method (int n)을 호출
}반복문은 그저 같은 문장을 반복해서 수행하는 것이지만, 메서드를 호출하는 것은 반복문보다 몇 가지 과정, 예를 들면 매개변수 복사와 종료 후 복귀할 주소저장 등이 추가로 필요하기 때문에 반복분보다 재귀호출의 수행시간이 더 오래 걸린다.
재귀 호출을 사용하는 이유는 재귀 호출이 주는 논리적 간결함 때문이다.
클래서 메서드(static메서드)와 인스턴스 메서드
변수에는 그랬던 것과 같이, 메서드 앞에 static이 붙어 있으면 클래스 메서드이고 붙어 있지 않으면 인스턴스 메서드이다.
인스턴스 메서드는 인스턴스 변수와 관련된 작업을 하는, 즉 메서드의 작업을 수행하는데 인스턴스 변수를 필요로 하는 메서드이다.
클래스 메서드는 인스턴스와 관계없는(인스턴스 변수나 인스턴스 메서드를 사용하지 않는) 메서드이다.
- 클래스를 설계할 때, 멤버변수 중 모든 인스턴스에 공통으로 사용하는 것에
static을 붙인다.
- 생성된 각 인스턴스는 서로 독립적이기 때문에 각 인스턴스의 변수는 서로 다른 값을 유지한다. 그러나 모든 인스턴스에서 같은 값이 유지되어야 하는 변수는
static을 붙여서 클래스변수로 정의해야 한다.
- 클래스 변수(static변수)는 인스턴스를 생성하지 않아도 사용할 수 있다.
static이 붙은 변수 (클래스 변수)는 클래스가 메모리에 올라갈 때 이미 자동적으로 생성되기 때문이다.
- 클래스 메서드(static메서드)는 인스턴스 변수를 사용할 수 없다.
- 인스턴스 변수는 인스턴스가 반드시 존재해야만 사용할 수 있는데, 클래스 메서드(static이 붙은 메서드)는 인스턴스 생성 없이 호출가능하므로 클래스 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수도 있다. 그래서 클래스 메서드에서 인스턴스 변수의 사용을 금지한다.
반면에 인스턴스 변수나 인스턴스 메서드에서는static이 붙은 멤버들을 사용하는 것이 언제나 가능하다. 인스턴스 변수가 존재하나는 것은static변수가 이미 메모리에 존재한다는 것을 의미하기 때문이다.
- 메서드 내에서 인스턴스 변수를 사용하지 않는다면,
static을 붙이는 것을 고려한다.
- 메서드의 작용내용 중에서 인스턴스 변수를 필요로 한다면,
static을 붙일 수 없다. 반대로 인스턴스 변수를 필요로 하지 않는다면static을 붙이자. 메서드 호출시간이 짧아지므로 성능이 향상된다.static을 안 붙인 메서드(인스턴스 메서드)는 실행 시 호출되어야할 메서드를 찾는 과정이 추가적으로 필요하기 때문에 시간이 더 걸린다.
- 클래스의 멤버변수 중 모든 인스턴스에 공통된 값을 유지해야하는 것이 있는지 살펴보고 있으면,
static을 붙여준다.- 작성한 메서드 중에서 인스턴스 변수나 인스턴스 메서드를 사용하지 않는 메서드에
static을 붙일 것을 고려한다.
클래스 멤버와 인스턴스 멤버간의 참조와 호출
같은 클래스에 속한 멤버들 간에는 별도의 인스턴스를 생성하지 않고도 서로 참조 또는 호출이 가능하다. 단, 클래스 멤버가 인스턴스 멤버를 참조 또는 호출하고자 하는 경우에는 인스턴스를 생성해야 한다.
그 이유는 인스턴스 멤버가 존재하는 시점에 클래스 멤버는 항상 존재하지만, 클레스 멤버가 존재하는 시점에 인스턴스 멤버가 존재하지 않을 수도 있기 때문이다.
class Testclass {
void instanceMethod() {} // 인스턴스 메서드
static void staticMethod() {} // static 메서드
void instanceMethod2() {
instanceMethod();
staticMethod();
}
static void staticMethod2() {
instanceMethod(); // 호출할 수 없다. (에러!!)
staticMethod();
}
int iv; // 인스턴스 변수
static int cv; // 클래스 변수
void instanceMethod3() {
System.out.println(iv);
System.out.println(cv);
}
static void staticMethod3() {
System.out.println(iv); // 사용할 수 없다. (에러!!)
System.out.println(cv);
}
}메서드간의 호출과 마찬가지로 인스턴스 메서드는 인스턴스 변수를 사용할 수 있지만, static 메서드는 인스턴스 변수를 사용할 수 없다.
class Testclass {
void instanceMethod() {} // 인스턴스 메서드
static void staticMethod() {} // static 메서드
int iv; // 인스턴스 변수
static int cv; // 클래스 변수
static void staticMethod2() {
instanceMethod(); // 호출할 수 없다. (에러!!)
staticMethod();
TestClass t = new TestClass();
t.instanceMethod(); // 인스턴스를 생성한 후 호출 가능
System.out.println(t.iv); // 인스턴스를 생성한 후 호출 가능
}
}오버로딩(overloading)
오버로딩이란?
메서드도 변수와 마찬가지로 같은 클래스 내에서 서로 구별될 수 있어야 하기 때문에 각기 다른 이름을 가져야 한다. 그러나 자바에서는 한 클래스 내에 이미 사용하려는 이름과 같은 이름을 가진 메서드가 있더라도 매개변수의 개수 또는 타입이 다르면, 같은 이름을 사용해서 메서드를 정의할 수 있다.
이처럼, 한 클래스 내에 같은 이름의 메서드를 여러 개 정의하는 것을 메서드 오버로딩(method overloading) 또는 간단히 오버로딩(overloading)이라 한다.
오버로딩의 조건
- 메서드 이름이 같아야 한다.
- 매개변수 개수 또는 타입이 달라야 한다.
비록 메서드의 이름이 같다 하더라도 매개변수가 다르면 서로 구별될 수 있기 때문에 오버로딩이 가능한 것이다. 위의 조건을 만족시키지 못하는 메서드는 중복 정의로 간주되어 컴파일 시에 에러가 발생한다. 그리고 오버로딩된 메서드들은 매개변수에 의해서만 구별될 수 있으므로 반환 타입은 오버로딩을 구현하는데 아무런 영향을 주지 못한다
오버로딩의 예
int add(int a, int b) { return a+b; }
int add(int x, int y) { return x+y; }위의 두 메서드는 매개변수의 이름만 다를 뿐 매개변수의 타입이 같기 때문에 오버로딩이 성립하지 않는다.
int add(int a, int b) { return a+b; }
long add(int a, int b) { return (long) (a+b) };이번 경우는 리턴 타입만 다른 경우이다. 매개변수의 타입과 개수가 일치하기 때문에 add(3,3)과 같이 호출하엿을 때 어떤 메서드가 호출된 것인지 결정할 수 없기 때문에 오버로딩으로 간주되지 않는다.
long add(int a, long b) { return a + b; }
long add(long a, int b) { return a + b; }두 메서드 모두 int형과 long형 매개변수가 하나씩 선언되어 있지만, 서로 순서가 다른 경우이다 이 경우에는 호출 시 매개변수의 값에 의해 호출될 메서드가 구분될 수 있으므로 중복된 메서드 정의가 아닌, 오버로딩으로 간주한다.
오버로딩의 장점
지금까지 오버로딩의 정의와 성립하기 위한 조건을 알아보았다. 그렇다면 오버로딩을 구현함으로써 얻는 이득은 무엇인가에 대해서 생각해보자.
만일 메서드도 변수처럼 단지 이름만으로 구별된다면, 한 클래스내의 모든 메서드들은 이름이 달라야한다. 그렇다면, 이전에 예로 들었던 10가지 println 메서드들은 각기 다른 이름을 가져야 한다.
모두 근본적으로 같은 기능을 하는 메서드들이지만, 서로 다른 이름을 가져야 하기 때문에 메서드를 작성하는 쪽에서는 이름을 짓기도 어렵고, 메서드를 사용하는 쪽에서는 이름을 일일이 구분해서 기억해야하기 때문에 서로 부담이 된다.
하지만 오버로딩을 통해 여러 메서드들이 println이라는 하나의 이름으로 정의될 수 있다면, println이라는 이름만 기억하면 되므로 기억하기도 쉽고 이름도 짧게 할 수 있어서 오류의 가능성을 많이 줄일 수 있다.
생성자(Constructor)
생성자란?
생성자는 인스턴스가 생성될 때 호출되는 인스턴스 초기화 메서드이다. 따라서 인스턴스 변수의 초기화 작업에 주로 사용되며, 인스턴스 생성 시에 실행되어야 할 작업을 위해서도 사용된다.
- 생성자의 이름은 클래스의 이름과 같아야 한다.
- 생성자는 리턴 값이 없다.
생성자는 다음과 같이 정의한다. 생성자도 오버로딩이 가능하므로 하나의 클래스에 여러 개의 생성자가 존재할 수 있다.
클래스이름 (타입 변수명, 타입 변수명, ...) {
// 인스턴스 생성 시 수행될 코드,
// 주로 인스턴스 변수의 초기화 코드를 적는다.
}
class Card {
Card() { // 매개변수가 없는 생성자.
...
}
Card(String k, int num) { // 매개변수가 잇는 생성자.
}
}연산자 new가 인스턴스를 생성하는 것이지 생성자가 인스턴스를 생성하는 것이 아니다.
생성자라는 용어 때문에 오해하기 쉬운데, 생성자는 단순히 인스턴스 변수들의 초기화에 사용되는 조금 특별한 메서드일 뿐이다.
Card c = new Card();
- 연산자 new에 의해서 메모리(heap)에 Card클래스의 인스턴스가 생성된다.
- 생성자 Card()가 호출되어 수행된다.
- 연산자 new의 결과로, 생성된 Card 인스턴스의 주소가 반환되어 참조변수 c에 저장된다.
지금까지 인스턴스를 생성하기 위해 사용해왔던 클래스이름()이 바로 생성자였던 것이다. 인스턴스를 생성할 때는 반드시 클래스 내에 정의된 생성자 중의 하나를 선ㄴ택하여 지정해주어야 한다.
기본 생성자(default constructor)
지금까지는 생성자를 모르고도 프로그래밍을 해왔지만, 사실 모든 클래스에는 반드시 하나 이상의 생성자가 정의되어 있어야 한다.
그러나 지금까지 클래스에 생성자를 정의하지 않고도 인스턴스를 생성할 수 있었던 이유는 컴파일러가 제공하는 기본 생성자(default constructor) 덕분이었다.
컴파일 할 때, 소스파일(*.java)의 클래스에 생성자가 하나도 정의되지 않은 경우 컴파일러는
자동적으로 아래와 같은 내용의 기본 생성자를 추가하여 컴파일 한다.
클래스 이름() { }
Card() { }class Data1 { int value; }
class Data2 {
int value;
Data2(int x) {
value = x;
}
}
class Test() {
public static void main(String args[]){
Data1 d1 = new Data1();
Data2 d2 = new Data2(); // compile 에러 발생
Data2 d2 = new Data2(10); // OK
}
}위 코드에서 에러가 나는 이유는 Data1에는 정의되어 있는 생성자가 하나도 없으므로 컴파일러가 기본 생성자를 추가해주었지만, Data2에는 이미 생성자 Data2(int x)가 정의되어 잇으므로 기본 생성자가 추가되지 않았기 때문이다.
컴파일러가 자동적으로 기본 생성자를 추가해주는 경우는 클래스 내에 생성자가 하나도 없을 때뿐이라는 것을 명심해야 한다.
매개변수가 있는 생성자
생성자도 메서드처럼 매개변수를 선언하여 호출 시 값을 넘겨받아서 인스턴스의 초기화 작업에 사용할 수 있다. 인스턴스마다 각기 다른 값으로 초기화 되어야하는 경우가 많기 때문에 매개변수를 사용한 초기화는 매우 유용하다.
class Car {
String color;
String gearType;
int door;
Car() {}
Car(String c, String g, int d) {
color = c;
gearType = g;
door = d;
}
}class Test() {
public static void main(String args[]) {
Car c = new Car();
c.color = "white";
c.gearType = "auto";
c.door = 4;
Car c = new Car("white", "auto", 4);
}
}위의 코드를 살펴보면 둘 다 같은 코드이지만 Car c = new Car("white", "auto", 4); 코드가 더 간결하고 직관적이다. 이처럼 클래스를 작성할 때 다양한 생성자를 제공함으로써 인스턴스 생성 후에 별도로 초기화를 하지 않아도 되도록 하는 것이 바람직하다.
생성자에서 다른 생성자 호출하기 - this(), this
같은 클래스의 멤버들간에 호출할 수 있는 것처럼 생성자 간에도 서로 호출이 가능하다. 단, 다음의 두 조건을 만족시켜야 한다.
- 생성자의 이름으로 클래스이름 대신 this를 사용한다.
- 한 생성자에서 다른 생성자를 호출할 때는 반드시 첫 줄에서만 호출이 가능하다.
Car(String color) {
door = 5;
Car(color, "auto", 4); //에러1. 생성자의 두번째 줄에서 다른 생성자 호출
//에러2. this(color, "auto", 4);로 해야함
}생성자 내에서 다른 생성자를 호출할 때는 클래스 이름인 Car대신 this를 사용해야하는데 그러지 않아서 에러이고, 또 다른 에러는 생성자 호출이 첫 번째 줄이 아닌 두 번째 줄이기 때문에 에러이다.
생성자에서 다른 생성자를 첫 줄에서마 호출이 가능하도록 한 이유는 생성자 내에서 초기화 작업도중에 다른 생성자를 호출하게 되면, 호출된 다른 생성자 내에서도 멤버변수들의 값을 초기화 할 것이므로 다른 생성자를 호출하기 이전에 초기화 작업이 무의미해질 수 있기 때문이다.
Car (String c, String g, int d) {
color = c;
gearType = g;
door = d;
}
Car (String color, String gearType, int door) {
color = this.color;
gearType = this.gearType;
door = this.door;
}위의 코드에서 Car (String color, String gearType, int door)는 생성자의 매개변수로 선언된 변수 이름이 color로 인스턴스 변수 color와 같을 경우에는 이름만으로 두 변수가 구별이 안된다. 이런 경우에는 인스턴스 변수 앞에 this를 사용하면 된다.
this: 인스턴스 자신을 가리키는 참조변수, 인스턴스의 주소가 저장되어 있다.
모든 인스턴스에 지역변수로 숨겨진 채로 존재한다.this(), this(매개변수): 생성자, 같은 클래스의 다른 생성자를 호출할 때 사용한다.
변수의 초기화
변수의 초기화
변수를 선언하고 처음으로 값을 저장하는 것을 변수의 초기화라고 한다. 변수의 초기화는 경우에 따라서 필수적이기도 하고 선택적이기도 하지만, 가능하면 선언과 동시에 적절한 값으로 초기화 하는 것이 바람직하다.
멤버 변수는 초기화를 하지 않아도 자동적으로 변수의 자료형에 맞는 기본값으로 초기화가 이루어지므로 초기화하지 않고 사용해도 되지만, 지역변수는 사용하기 전에 반드시 초기화 해야한다.
class InitTest {
int x; // 인스턴스변수
int y = x; // 인스턴스변수
void method1() {
int i; // 지역변수
int j = i; // 에러. 지역변수를 초기화하지 않고 사용
}
}멤버변수(클래스변수와 인스턴스변수)와 배열의 초기화는 선택적이지만, 지역변수의 초기화는 필수적이다.
멤버변수의 초기화 방법
1. 명시적 초기화(explicit intialization)
2. 생성자(constructor)
3. 초기화 블럭(initialization block)
- 인스턴스 초기화 블럭: 인스턴스변수를 초기화하는데 사용
- 클래스 초기화 블럭: 클래스변수를 초기화하는데 사용
명시적 초기화
변수를 선언과 동시에 초기화하는 것을 명시적 초기화라고 한다. 가장 기본적이면서도 간단한 초기화 방법이므로 여러 초기화 방법 중에서 가장 우선적으로 고려되어야 한다.
class Car {
int door = 4; // 기본형 변수의 초기화
Engine e = new Engine(); // 참조형 변수의 초기화
//...
}초기화 블럭(initialization block)
초기화 블럭에는 클래스 초기화 블럭과 인스턴스 초기화 블럭 두 가지 종류가 있다.
클래스 초기화 블럭: 클래스변수의 복잡한 초기화에 사용된다.
인스턴스 초기화 블럭: 인스턴스변수의 복잡한 초기화에 사용된다.
class InitBlock {
static { /* 클래스 초기화 블럭 */ }
{ /* 인스턴스 초기화블럭 */ }
//...
}클래스 초기화 블럭은 클래스가 메모리에 처음 로딩될 때 한번만 수행되며, 인스턴스 초기화 블럭은 생성자와 같이 인스턴스를 생성할 때 마다 수행된다.
그리고 생성자 보다 인스턴스 초기화 블럭이 먼저 수행된다.
멤버변수의 초기화 시기와 순서
클래스변수의 초기화시점: 클래스가 처음 로딩될 때 단 한번 초기화 된다.
인스턴스변수의 초기화시점: 인스턴스가 생성될 때마다 각 인스턴스별로 초기화가 이루어진다.클래스변수의 초기화 순서: 기본값 -> 명시적 초기화 -> 클래스 초기화 블럭
인스턴스변수의 초기화 순서: 기본값 -> 명시적 초기화 -> 인스턴스 초기화 블럭 -> 생성자
프로그램 실행도중 클래스에 대한 정보가 요구될 때, 클래스는 메모리에 로딩된다. 예를 들면, 클래스 멤버를 사용했을 때, 인스턴스를 생성할 때 등이 이에 해당한다.
하지만, 해당 클래스가 이미 메모리에 로딩되어 있다면, 또다시 로딩하지 않는다. 또다시 로딩하지 않는다. 물론 초기화도 다시 수행되지 않는다.
