
프로세스와 쓰레드
프로세스(process)란 간단히 말해서 실행 중인 프로그램(program)이다. 프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)을 할당받아 프로세스가 된다.
프로세스는 프로그램을 수행하는 데 필요한 데이터와 메모리 등의 자원 그리고 쓰레드로 구성되어 있으며 프로세스의 자원을 이용해서 실제로 작업을 수행하는 것이 바로 쓰레드이다.
그래서 모든 프로세스에는 최소한 하나 이상의 쓰레드가 존재하며, 둘 이상의 쓰레드를 가진 프로세스를 멀티쓰레드 프로세스(multi-threaded process)라고 한다.
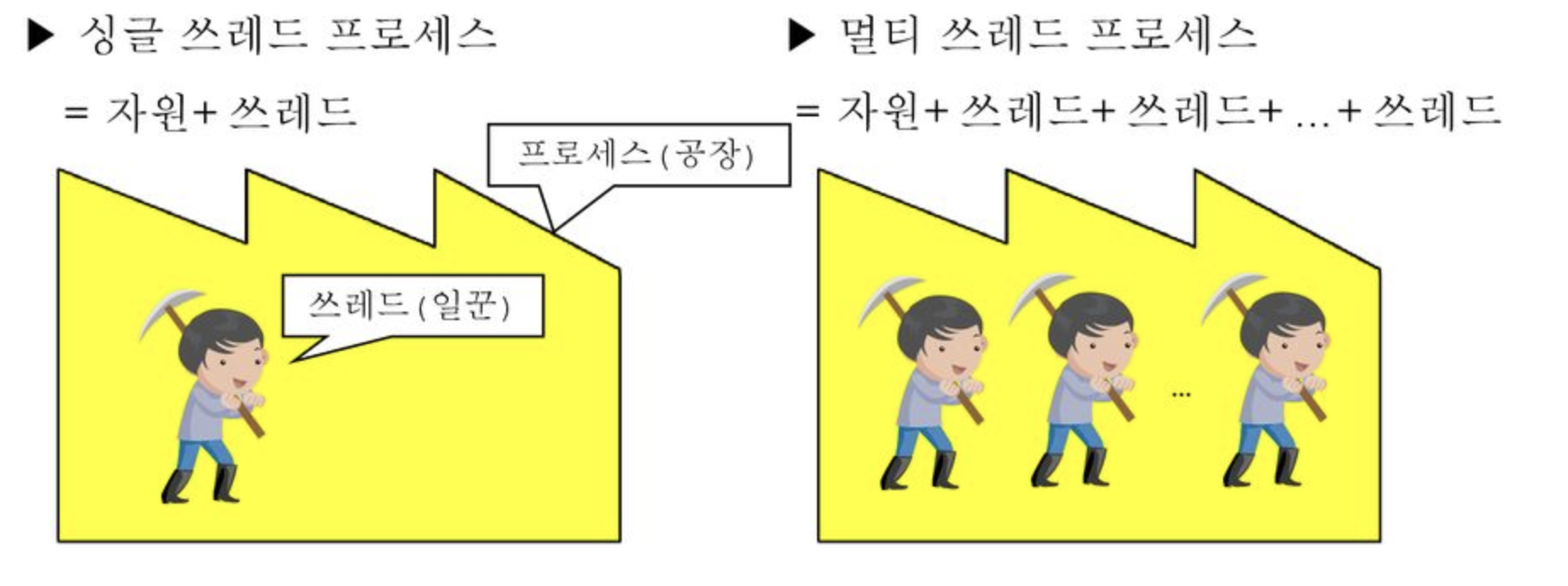
하나의 프로세스가 가질 수 있는 쓰레드의 개수는 제한되어 있지 않으나 쓰레드가 작업을 수행하는ㄷ네 개별적인 메모리 공간(호출스택)을 필요로 하기 때문에 프로세스의 메모리 한계에 따라 생성할 수 있는 쓰레드의 수가 결정된다. 실제로는 프로세스의 메모리 한계에 다다를 정도로 많은 쓰레드를 생성하는 일은 없을 것이니 걱정하지 않아도 된다.
멀티태스킹과 멀티쓰레딩
현재 우리가 사용하고 있는 윈도우나 유닉스를 포함한 대부분의 OS는 멀티태스킹(multi-tasking, 다중작업)을 지원하기 때문에 여러 개의 프로세스가 동시에 실행될 수 있다.
이와 마찬가지로 멀티쓰레딩은 하나의 프로세스 내에서 여러 스레드가 동시에 작업을 수행하는 것이다. CPU의 코어(core)가 한 번에 단 하나의 작업만 수행할 수 있으므로, 실제로 동시에처리되는 작업의 개수는 코어의 개수와 동일하다. 그러나 처리해야하는 스레드의 수는 언제나 코어의 개수보다 훨씬 많기 때문에 각 코어가 아주 짧은 시간 동안 여러 작업을 번갈아가며 수행함으로써 여러 작업들이 모두 동시에 수행되는 것처럼 보인다.
그래서 프로세스의 성능이 단순히 쓰레드의 개수를 비례하는 것은 아니며, 하나의 쓰레드를 가진 프로세스 보다 두 개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수 있다.
멀티쓰레딩의 장단점
멀티 쓰레딩의 장점
- CPU의 사용률을 향상시킨다.
- 자원을 보다 효율적으로 사용할 수 있다.
- 사용자에 대한 응답성이 향상된다.
- 작업이 분리되어 코드가 간결해진다
메신저로 채팅하면서 파일을 다운 받거나 음성대화를 나눌 수 있는 것이 가능한 이유가 바로 멀티쓰레드로 작성되어 있기 때문이다. 만일 싱글쓰레드로 작성되어 있다면 파일을 다운로드 받는 동안에는 다른 일(채팅)을 전혀 할 수 없을 것이다.
여러 사용자에게 서비스를 해주는 서버 프로그램의 경우 멀티쓰레드로 작성하는 것은 필수적이어서 하나의 서버 프로세스가 여러 개의 쓰레드를 생성해서 쓰레드와 사용자의 요청이 일대일로 처리되도록 프로그래밍해야 한다.
만일 싱글쓰레드로 서버 프로그램을 작성한다면 사용자의 요청 마다 새로운 프로세스를 생성해야하는데 프로세스를 생성하는 쓰레드를 생성하는 것에 비해 더 많인 시간과 메모리 공간이 필요하기 때문에 많은 수의 사용자 요청을 서비스하기 어렵다.
그러나 멀티쓰레딩에 장점만 있는 것은 아니어서 멀티쓰레드 프로세스는 여러 쓰레드가 같은 프로세스 내에서 자원을 공유하면서 작업을 하기 떄문에 발생할 수 있는 동기화(synchronization), 교착상태(deadlock)와 같은 문제들을 고려해서 신중히 프로그래밍해야 한다.
쓰레드의 구현과 실행
쓰레드를 구현하는 방법은 Thread 클래스를 상속받는 방법과 Runnable 인터페이스 구현하는 방법, 모두 두 가지가 있다. 어느 쪽을 선택해도 별 차이는 없지만 Thread 클래스를 상속받으면 다른 클래스를 상속받을 수 없기 때문에, Runnable 인터페이스를 구현하는 방법이 일반적이다.
Runnable 인터페이스를 구현하는 방법은 재사용성(reusability)이 높고 코드의 일관성(consistency)을 유지할 수 있기 때문에 보다 객체지향적인 방법이라고 할 수 있겠다.
1. Thrad 클래스를 상속
class MyThread extends Thread {
public void run() { ... } // Thread 클래스의 run()을 오버라이딩
}2. Runnable 인터페이스를 구현
class MyThread implements Runnable {
public void run() { ... } // Runnable 인터페이스의 run()을 구현
}Runnable 인터페이스는 오로지 run()만을 정의되어 있는 간단한 인터페이스이다. Runnable인터페이스를 구현하기 위해서 해야할 일은 추상메서드인 run()의 몸통 {}을 만들어주는 것 뿐이다.
public interace Runnable {
public abstract void run();
}쓰레드를 구현하는 것은, 위의 두 방법 중 어떤 것을 선택하든지, 그저 쓰레드를 통해 작업하고자 하는 내용으로 run()의 몸통 {}을 채우는 것일 뿐이다.
Thread 클래스를 상속받은 경우와 Runnable 인터페이스를 구현한 경우의 인스턴스 생성 방법이 다르다.
ThreadEx1 t1 = new ThreadEx1();
Runnable r = new ThreadEx2();
Thread t2 = new Thread(r);
Thread t2 = new Thread(new ThreadEx2());Runnable 인터페이스를 구현한 경우, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 Thread클래스의 생성자의 매개변수로 제공해야 한다.
아래의 코드는 실제 Thread 클래스의 소스코드(Thread.java)를 이해하기 쉽게 수정한 것인데, 인스턴스 변수로 Runnable타입의 변수 r을 선언해 놓고 생성자를 통해서 Runnable 인터페이스를 구현한 인스턴스를 참조하도록 되어 있는 것을 확인할 수 있다.
그리고 run()을 호출하면 참조변수 r을 통해서 Runnable 인터페이스를 구현한 인스턴의 run()이 호출된다. 이렇게 함으로써 상속을 통해 run()을 오버라이딩하지 않고 외부로부터 run()을 제공받을 수 있다.
public class Thread {
private Runnable r; // Runnable을 구현한 클래스의 인스턴스를 참조하기 위한 변수
public Thread(Runnable r) {
this.r = r;
}
public void run() {
if (r != null) {
r.run(); // Runnable 인터페이스를 구현한 인스턴스의 run()을 호출
}
}
}Thread 클래스를 상속받으면, 자손 클래스에서 조상인 Thread 클래스의 메서드를 직접 호출할 수 있지만, Runnable을 구현하면 Thread 클래스의 static 메서드인 current Thread()를 호출하여 쓰레드에 대한 참조를 얻어 와야만 호출이 가능하다.
static Thread currentThread() // 현재 실행중인 쓰레드의 참조를 반환한다.
static getName() // 쓰레드의 이름을 반환한다.그래서 Thread를 상속받은 ThreadEx1에서는 간단히 getName()을 호출하면 되지만, Runnable을 구현한 ThreadEx2에는 멤버라고는 run()밖에 없기 때문에 Thread클래스의 getName()을 호출하려면, Thread.currentThread().getName()와 같이 해야 한다.
쓰레드의 실행 - start()
쓰레드를 생성했다고 해서 자동으로 실행되는 것은 아니다. start()를 호출해야만 쓰레드가 실행된다.
t1.start(); // 쓰레드 실행
t2.start(); // 쓰레드 실행사실은 start()가 호출되었다고 해서 바로 실행되는 것이 아니라, 일단 실행대기 상태에 있다가 자신의 차례가 되어야 실행된다. 물론 실행대기중인 쓰레드가 하나도 없으면 곧바로 실행상태가 된다.
한 가지 더 알아 두어야 하는 것은 한 번 실행이 종료된 쓰레드는 다시 실행할 수 없다는 것이다. 즉, 하나의 쓰레드에 대해 start()가 한 번만 호출될 수 있다는 뜻이다.
그래서 만일 쓰레드의 작업을 한 번 더 수행해야 한다면 아래의 오른쪽 코드와 같이 새로운 쓰레드를 생성한 다음에 start()를 호출해야 한다. 만일 아래 왼쪽 코드처럼 하나의 쓰레드에 대해 start()를 두 번 이상 호출하면 실행시에 IllegalThreadStateException이 발생한다.
ThreaEx1 t1 = new ThreaEx1();
t1.start();
t1.start(); // 예외 발생ThreaEx1 t1 = new ThreaEx1();
t1.start();
t1 = new ThreaEx1(); // 다시 생성
t1.start();start()와 run()
쓰레드를 실행시킬 때 run()이 아닌 start()를 호출한다는 것에 대해서 다소 의문이 들었을 것이다. 이제 start()와 run()의 차이와 쓰레드가 실행되는 과정에 대해서 자세히 살펴보자.
main메서드에서 run()을 호출하는 것은 생성된 쓰레드를 실행시키는 것이 아니라 단순히 클래스에 선언된 메서드를 호출하는 것일 뿐이다.
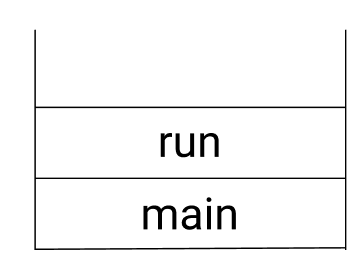 main메서드에서 run()을 호출했을 때의 호출 스택
main메서드에서 run()을 호출했을 때의 호출 스택
반면에 start()는 새로운 쓰레드가 작업을 실행하는데 필요한 호출스택(call stack)dㅡㄹ 생성한 다음에 run()을 호출해서, 생성된 호출스택에 run()이 첫 번째로 올라가게 한다.
모든 쓰레드는 독립적인 작업을 수행하기 위해 자신만의 호출스택을 필요로 하기 때문에, 새로운 쓰레드를 생성하고 실행시킬 때마다 새로운 호출스택이 생성되고 쓰레드가 종료되면 작업에 사용된 호출스택은 소멸된다.
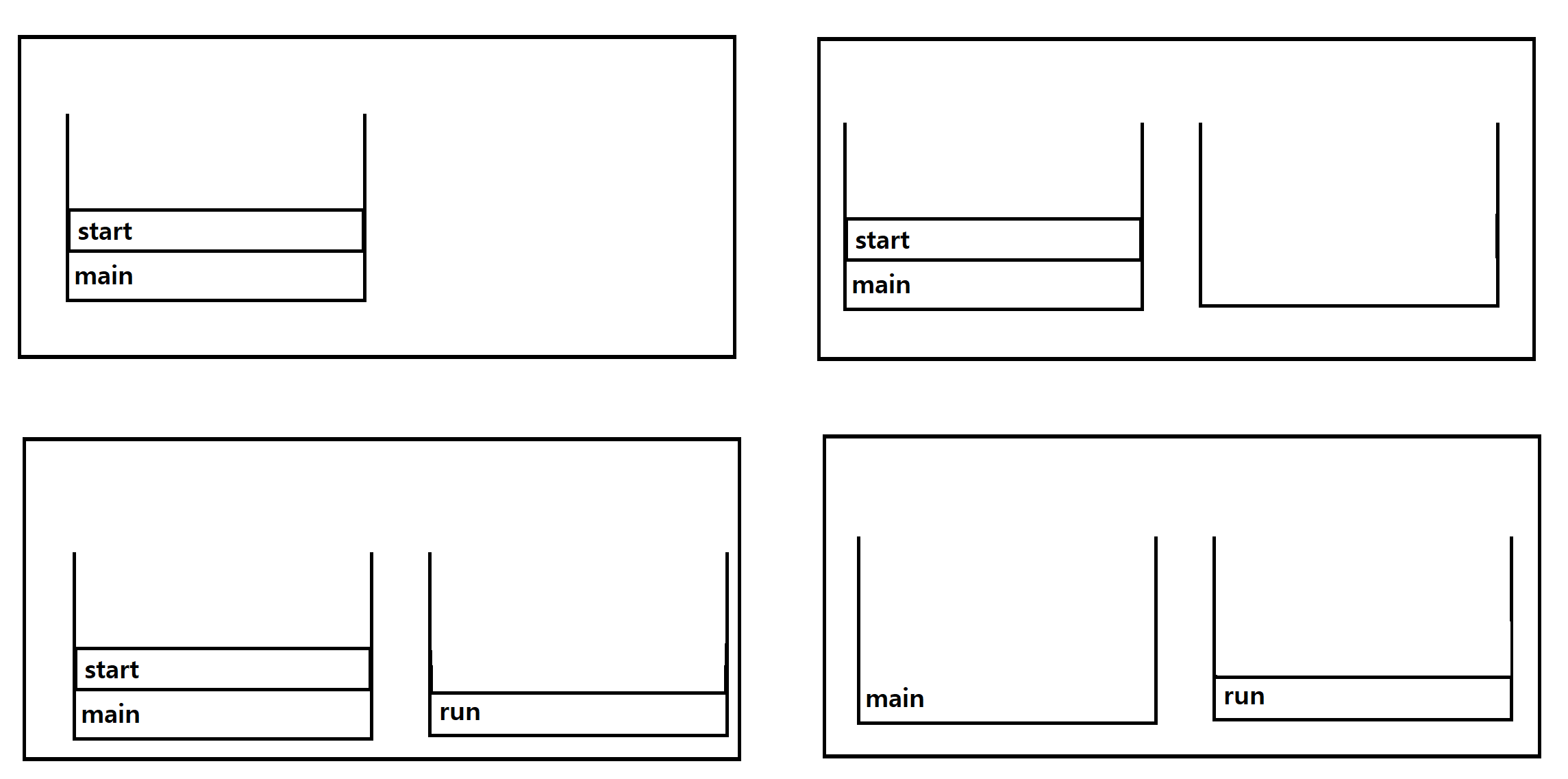
- main메서드에서 쓰레드의 start()를 호출한다.
- start()는 새로운 쓰레드를 생성하고, 쓰레드가 작업하는데 사용될 호출스택을 생성한다.
- 새로 생성된 호출스택에 run()이 호출되어, 쓰레드가 독립된 공간에서 작업을 수행한다.
- 이제는 호출스택이 2개이므로 스케줄러가 정한 순서에 의해서 번갈아 가면서 실행된다.
호출스택에서는 가장 위에 있는 메서드가 현재 실행중인 메서드이고 나머지 메서드들은 대기상태에 있다는 것을 기억할 것이다. 그러나 위의 그림에서와 같이 쓰레드가 둘 이상일 때는 호출스택의 최상위에 있는 메서드일지라도 대기상태에 있을 수 있다.
스케줄러는 실행대기중인 쓰레드들의 우선순위를 고려하여 실행순서와 실행시간을 결정하고, 각 쓰레드들은 작성된 스케줄에 따라 자신의 순서가 되면 지정된 시간동안 작업을 수행한다.
이 때 주어진 시간동안 작업을 마치지 못한 쓰레드는 다시 자신의 차례가 돌아올 때까지 대기상태로 있게 되며, 작업을 마친 쓰레드, 즉 run()의 수행이 종료된 쓰레드는 호출스택이 모두 비워지면서 이 스레드가 사용하던 호출스택은 사라진다.
이는 마치 자바프로그램을 실행하면 호출스택이 생성되고 main메서드가 처음으로 호출되고, main메서드가 종료되면 호출스택이 비워지면서 프로그램이 종료되는 것과 같다.
main쓰레드
이미 눈치 챘겠지만 main메서드의 작업을 수행하는 것도 쓰레드이며, 이를 main 쓰레드라고 한다. 우리는 지금까지 우리도 모르는 사이에 이미 쓰레드를 사용하고 있었던 것이다. 앞서 쓰레드가 일꾼이라고 하였는데, 프로그램이 실행되기 위해서는 작업을 수행하는 일꾼이 최소한 하나는 필요하지 않겠는가. 그래서 프로그램을 실행하면 기본적으로 하나의 쓰레드(일꾼)을 생성하고, 그 쓰레드가 main 메서드를 호출해서 작업이 수행되도록 하는 것이다.

지금까지는 main메서드가 수행을 마치면 프로그램이 종료되었으나, 위의 그림에서와 같이 main메서드가 수행을 마쳤다하더라도 다른 쓰레드가 아직 작업을 마치지 않은 상태라면 프로그램이 종료되지 않는다.
실행 중인 사용자 쓰레드가 하나도 없을 떄 프로그램은 종료된다.
쓰레드는 사용자 쓰레드(user thread)와 데몬 쓰레드(demon thread), 두 종류가 있는데 자세한 것은 곧 설명할 것이다.
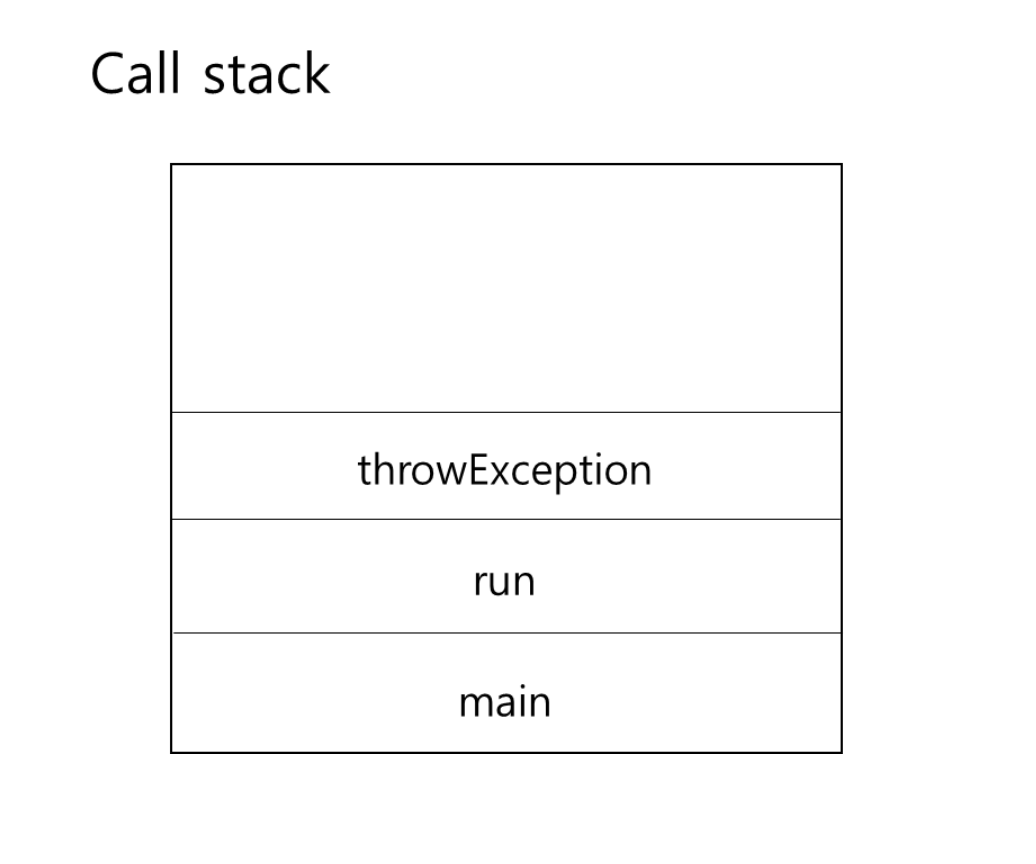
class A {
public static void main(String[] args) throws Exception{
ThreadEx1 t1 = new ThreadEx1();
t1.start()
}
}
class ThreadEx1 extends Thread{
public void run(){
throwException();
}
public void throwException(){
try{
throw new Exception();
}catch(Exception e){
e.printStackTrace();
}
}
}위의 예제는 고의로 예외를 발생시키고 당시의 호출스택을 출력하는 예제이다. 위의 예제의 호출스택은 main 메서드가 아니라 run 메서드인 것을 확인하자.
한 쓰레드가 예외가 발생해서 종료되어도 다른 쓰레드의 실행에는 영향을 미치지 않는다. 아래 그림에 main 쓰레드의 호출스택이 없는 이유는 main 쓰레드가 이미 종료되었기 때문이다.

class B {
public static void main(String[] args) throws Exception{
ThreadEx2 t2 = new ThreadEx2();
t2.run();
}
}
class ThreadEx2 extends Thread{
public void run(){
throwException();
}
public void throwException(){
try{
throw new Exception();
}catch(Exception e){
e.printStackTrace();
}
}
}
위의 코드는 run()을 실행시켰기 때문에 이전 예제와 달리 쓰레드가 새로 생성되지 않는다. 아래 그림은 main 쓰레드의 호출스택이며, main 메서드가 포함되어 있다.
싱글쓰레드와 멀티쓰레드
앞에서 멀티쓰레드 프로세스가 가진 장점을 간단히 설명했는데, 이번에는 예제를 통해서 싱글쓰레드 프로세스와 멀티쓰레드 프로세스의 차이를 보다 깊이 있게 이해할 수 있도록 하고자 한다.
두 개의 작업을 하나의 쓰레드(th1)로 처리하는 경우와 두 개의 쓰레드(th1, th2)로 처리하는 경우를 가정해보자. 하나의 쓰레드로 두 작업을 처리하는 경우는 한 작업을 마친 후에 다른 작업을 시작하지만, 두 개의 쓰레드로 작업하는 경우에는 짧은 시간동안 2개의 쓰레드(th1, th2)가 번갈아 가면서 작업을 수행해서 동시에 두 작업이 처리되는 것과 같이 느끼게 한다.
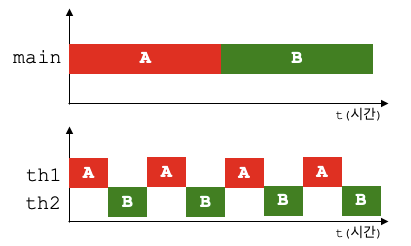
위의 그래프에서 알 수 있듯이 하나의 쓰레드로 두개의 작업을 수행한 시간과 두개의 쓰레드로 두 개의 작업을 수행한 시간은 거의 같다. 오히려 두 개의 쓰레드로 작업한 시간이 싱글쓰레드로 작업한 시간보다 더 걸리게 되는데 그 이유는 쓰레드간의 작업 전환(context switching)에 시간이 걸리기 때문이다.
작업 전환을 할 때는 현재 진행 중인 작업의 상태, 예를 들면 다음에 실행해야할 위치(PC, 프로그램 카운터) 등의 정보를 저장하고 읽어 오는 시간이 소요된다. 참고로 쓰레드의 스위칭에 비해 프로세스의 스위칭이 더 많은 정보를 저장해야하므로 더 많은 시간이 소요된다.
그래서 싱글 코어에서 단순히 CPU만을 사용하는 계산작업이라면 오히려 멀티쓰레드보다 싱글쓰레드로 프로그래밍하는 것이 더 효율적이다.
예제 프로그램을 실행할 때마다 실행할때마다 다른 결과를 얻을 수 있는데 그 이유는 OS의 프로세스 스케줄러의 영향을 받기 때문이다. JVM의 쓰레드 스케줄러에 의해서 어떤 쓰레드가 얼마동안 실행될 것인지 결정되는 것과 같이 프로세스도 프로세스 스케줄러에 의해서 실행순서와 실행시간이 결정되기 때문에 매 순간 상황에 따라 프로세스에게 할당되는 실행시간이 일정하지 않고 쓰레드에게 할당되는 시간 역시 일정하지 않게 된다. 그래서 쓰레드가 이러한
불확실성을 가지고 있다는 것을 염두해야 한다.자바가 OS에 독립적이라고는 하지만 실제로는 OS종속적인 부분이 몇 가지 있는데 쓰레드도 이중 하나이다.
두 쓰레드가 서로 다른 자원을 사용하는 작업에 경우에는 싱글 쓰레드 프로세스보다 멀티 쓰레드
프로세스가 더 효율적이다. 예를 들면 사용자로부터 데이터를 입력받는 작업, 네트워크로 파일을 주고받는 작업등과 같이 외부기기와의 입출력을 필요로 하는 경우가 이에 해당한다.
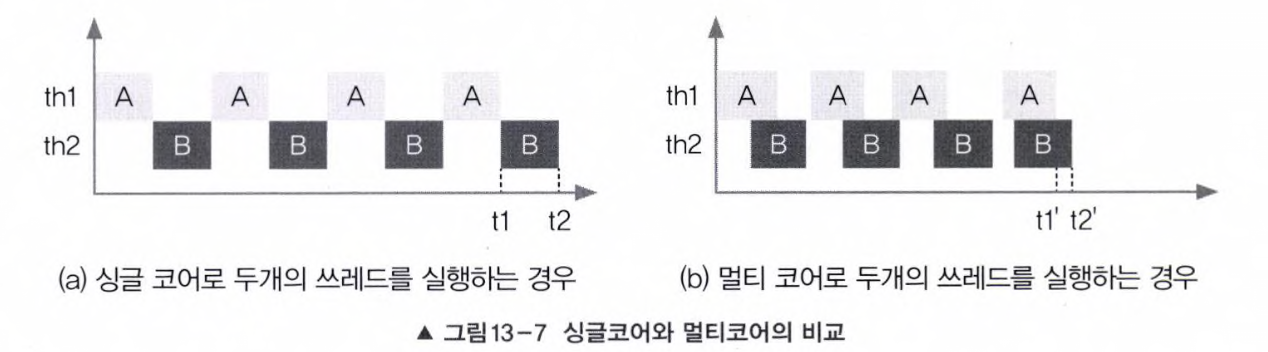
만일 사용자로 부터 입력받는 작업(A)과 화면에 출력하는 작업(B)을 하나의 쓰레드로 처리한다면 위의 그림 첫 번 째 그래프처럼 사용자가 입력을 마칠 때까지 아무 일도 하지 못하고 기다리기만 해야 한다.
그러나 두 개의 쓰레드로 처리한다면 사용자의 입력을 기다리는 동안 다른 쓰레드가 작업을 처리할 수 있기 때문에 보다 효율적인 CPU의 사용이 가능하다.
작업 A와 B가 모두 종료되는 시간 t2와 t2'를 비교하면 t2 > t2'로 멀티 쓰레드 프로세스의 경우가 잦ㄱ업을 더 빨리 마치는 것을 알 수 있다.
import javax.swing.JOptionPane;
class ThreadEx6
{
public static void main(String[] args) throws Exception
{
String input = JOptionPane.showInputDialog("아무값이나 입력하세요."); //락이 걸림
System.out.println("입력하신 값은 " + input + "입니다."); //확인을 누르면 출력 후 for문 실행
for (int i = 10; i > 0; i--)
{
System.out.println(i);
try
{
Thread.sleep(1000);
}
catch (Exception e)
{
System.out.println(e);
}
}
}
}입력하신 값은 1입니다.
10
9
8
7
6
5
4
3
2
1
이 예지는 하나의 쓰레드로 사용자의 입력을 받는 작업에 화면에 숫자를 출력하는 작업을 처리하기 때문에 사용자가 입력을 마치기 전까지는 화면에 숫자가 출력되지 않다가 사용자가 입력을 마치고 나서야 화면에 숫자가 출력된다.
import javax.swing.JOptionPane;
public class ThreadEx7 {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName());
ThreadEx7_1 th1 = new ThreadEx7_1();
th1.start();
String input = JOptionPane.showInputDialog("아무 값이나 입력하세요.");
System.out.println("입력하신 값은 " + input + "입니다.");
}
}
class ThreadEx7_1 extends Thread{
public void run() {
System.out.println(Thread.currentThread().getName());
for (int i = 10; i > 0; i--) {
System.out.println(i);
try { sleep(1000); } catch (Exception e) {}
}
} // run()
}10
9
8
7
6
입력하신 값은 abcd입니다.
5
4
3
2
1
이전 예제와는 달리 사용자로부터 입력받는 부분과 화면에 숫자를 출력하는 부분을 두 개의 쓰레드로 나누어서 처리했기 때문에 사용자가 입력을 마치지 않았어도 화면에 숫자가 출력되는 것을 알 수 있다.
쓰레드의 우선순위
쓰레드는 우선순의(priority)라는 속성(멤버변수)을 가지고 있는데, 이 우선순위의 값에 따라 쓰레드가 얻는 실행시간이 달라진다. 쓰레드가 수행하는 작업의 중요도에 따라 쓰레드의 우선순위를 서로 다르게 지정하여 특정 쓰레드가 더 많은 작업을시간을 갖도록 할 수 있다.
예를 들어 파일 전송기능이 있는 메신저의 경우, 파일다운로드를 처리하는 쓰레드보다 채팅내용을 전송하는 쓰레드의 우선순위가 더 높아야 사용자가 채팅하는데 불편함이 없을 것이다. 대신 파일다운로드 작업에 걸리는 시간은 길어질 것이다
이처럼 시간적인 부분이다 사용자에게 빠르게 반응해야하는 작업을 하는 쓰레드의 우선 순위는 다른 작업을 수행하는 쓰레드에 비해 높아야 한다.
쓰레드의 우선순위 정하기
쓰레드의 우선순위와 관련된 메서드와 상수는 다음과 같다.
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경한다.
int getPriority() // 쓰레드의 우선순위를 반환한다.
public static final int MAX_PRIORITY = 10 // 최대우선순위
public static final int MIN_PRIORITY = 1 // 최대우선순위
public static final int NORM_PRIORITY = 5 // 보통우선순위쓰레드가 가질 수 있는 우선순위의 범위는 1~10이며 숫자가 높을수록 우선순위가 높다.
한 가지 더 알아두어야 할 것은 쓰레드의 우선순위는 쓰레드를 생성한 쓰레드로부터 상속받는다는 것이다. main메서드를 수행하는 쓰레드는 우선순위 5이므로 main메서드내에서 생성하는 쓰레드의 우선순위는 자동적으로 5가 된다.
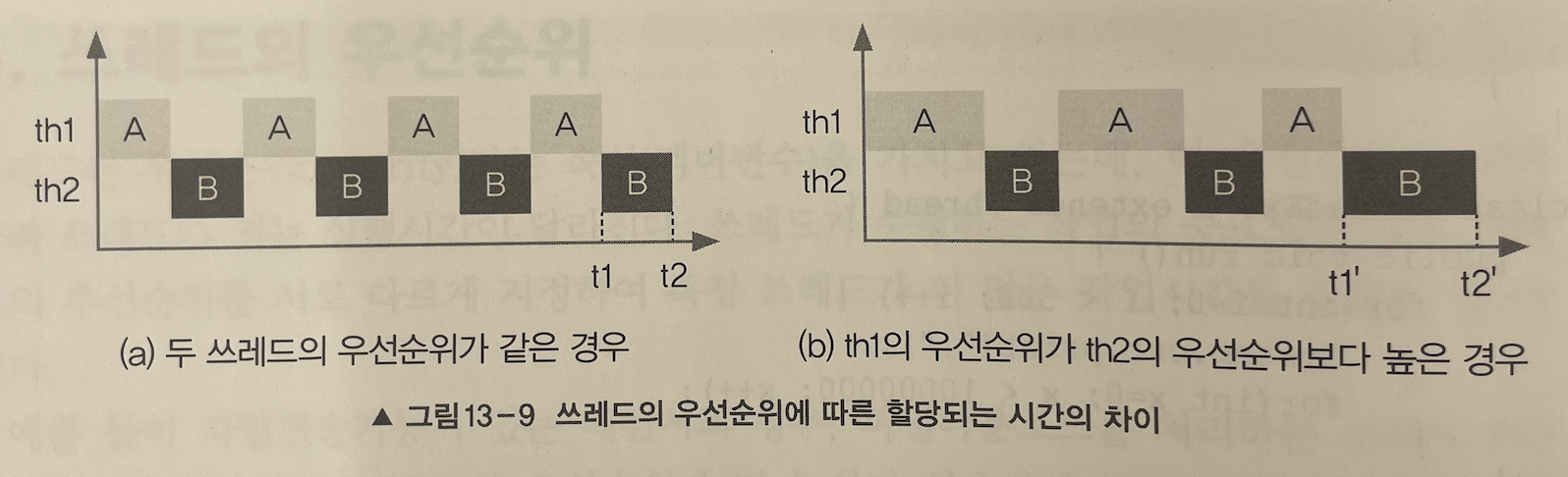
그림 13-9는 윈도우즈에서 싱글 코어로 두 개의 쓰레드로 두개의 작업을 실행했을 때의 결과를 그림으로 나타낸 것인데, 우선순위가 같은 경우 각 쓰레드에게 거의 같은 양의 실행시간이 주어지지만, 우선순위가 다르다면 우선순위가 높은 th1에게 상대적으로 th2보다 더 많은 양의 실행시간이 주어지고 결과적으로 작업 A가 B보다 더 빨리 완료될 수 있다.
그러나 실행결과2에서 알 수 있듯이 멀티코어에서는 쓰레드의 우선순위에 따라 차이가 거의 아니 전혀 없었다. 우선순위를 다르게 하여 여러 번 테스트해도 결과는 같았다. 결국 우선순위에 차등을 두어 쓰레드를 실행시키는 것이 별 효과가 없었다.
그저 쓰레드에 높은 우선순위를 주면 더 많은 실행시간과 실행기회를 갖게 될 것이라고 기대할 수 없는 것이다.
멀티코어라 해도 OS마다 다른 방식으로 스케쥴링하기 때문에, 어떤 OS를 실행하느냐에 따라 다른 결과를 얻을 수 있다. 굳이 우선순위에 차등을 두어 쓰레드를 실행하려면, 특정 OS의 스케쥴링 정책과 JVM의 구현을 직접 확인해봐야 한다. 자바는 쓰레드가 우선 순쉬에 따라 어떻게 다르게 처리되어야 하는지에 대해 강제하지 않으므로 쓰레드의 우선순위와 관련된 구현이 JVM마다 다를 수 있기 때문이다.
만일 확인한다 하더라도 OS의 스케쥴러에 종속적이라서 어느 정도 예측만 가능한 정도일 뿐 정확히 알 수는 없다.
차라리 쓰레드에 우선순위를 부여하는 대신 작업에 우선순위를 두어 PriorityQueue에 저장해 놓고, 우선순위가 높은 작업이 먼저 처리되도록 하는 것이 나을 수 있다.
쓰레드 그룹(thread group)
쓰레드 그룹은 서로 관련된 쓰레드를 그룹으로 다루기 위한 것으로, 폴더를 생성해서 관련된 파일들을 함께 넣어서 관리하는 것처럼 쓰레드 그룹을 생성해서 쓰레드를 그룹으로 묶어서 관리할 수 있다.
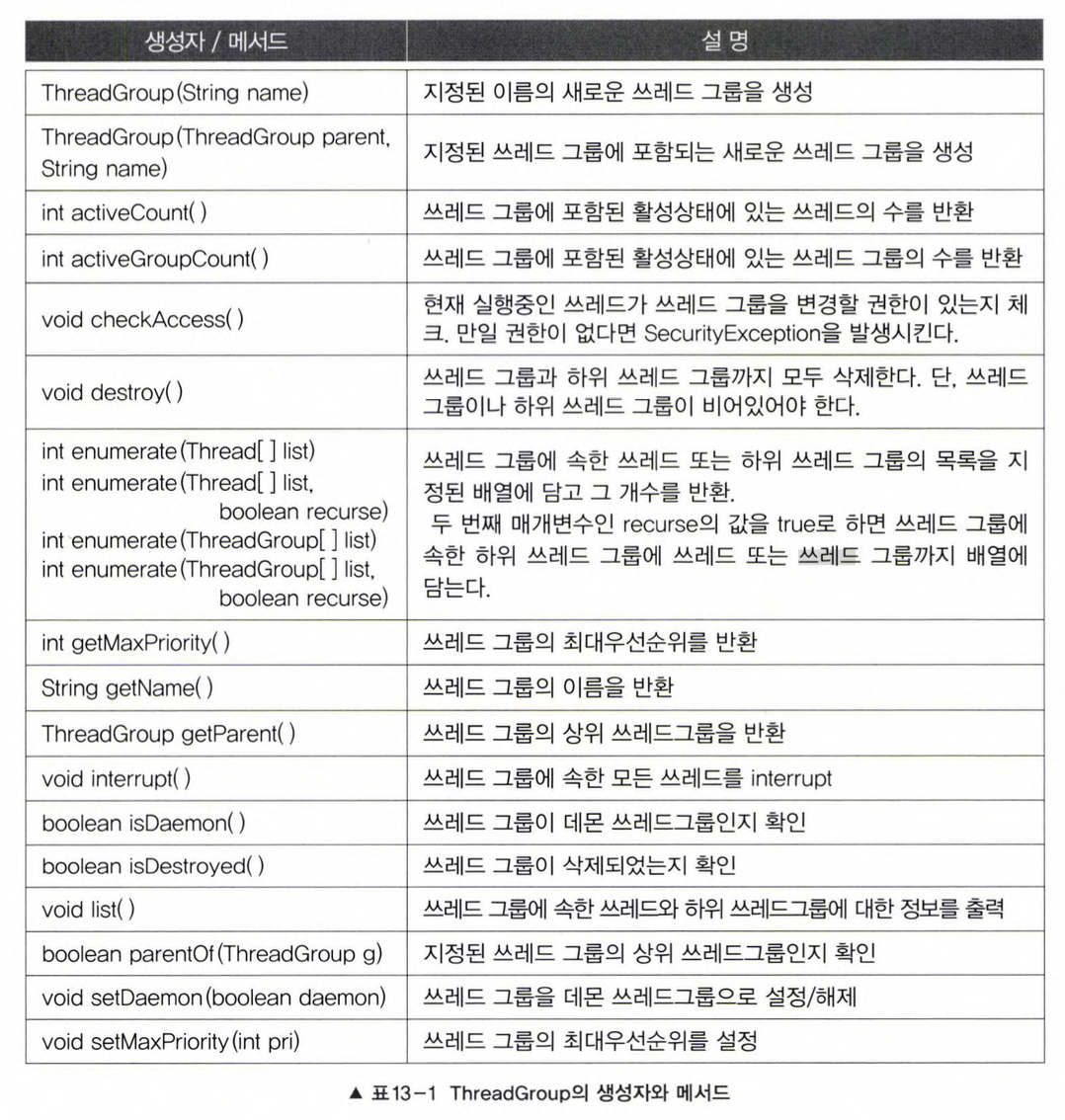
또한 폴더 안에 폴더를 생성할 수 있듯이 쓰레드 그룹에 다른 쓰레드 그룹을 포함 시킬 수 있다. 사실 쓰레드 그룹은 보안상의 이유로 도입된 개념으로, 자신이 속한 쓰레드 그룹이나 하위 쓰레드 그룹은 변경할 수 있지만 다른 쓰레드 그룹의 쓰레드를 변경할 수 없다. ThreadGroup을 사용해서 사용할 수 있으며, 주요 생성자와 메서드는 다음과 같다.
쓰레드를 쓰레드 그룹에 포함시키려면 Thread의 생성자를 이용해야 한다.
Thread(ThreadGroup group, String name)
Thread(ThreadGroup group, Runnable target)
Thread(ThreadGroup group, Runnable target, String name)
Thread(ThreadGroup group, Runnable target, String name, long stackSize)모든 쓰레드는 반드시 쓰레드 그룹에 포함되어 있어야 하기 때문에, 위와 같이 쓰레드 그룹을 지정하는 생성자를 사용하지 않은 쓰레드는 기본적으로 자신을 생성한 쓰레드와 같은 쓰레드 그룹에 속하게 된다.
자바 어플리케이션이 실행되면, JVM은 main과 system이라는 쓰레드 그룹을 만들고 JVM운영에 필요한 쓰레드들을 생성해서 이 쓰레드 그룹에 포함시킨다. 예를 들어 main 메서드를 수행하는 main이라는 이름의 쓰레드는 main 쓰레드 그룹에 속하고, 가비지컬렉션을 수행하는 FInalizer쓰레드는 system쓰레드 그룹에 속한다.
우리가 생성하는 모든 쓰레드 그룹은 main쓰레드 그룹의 하위 쓰레드 그룹이 되며, 쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 자동적으로 main쓰레드 그룹에 속하게 된다.
그 외의 Thread의 쓰레드 그룹과 관련된 메서드는 다음과 같다.
ThreadGroup getThreadGroup() // 쓰레드 자신이 속한 쓰레드 그룹을 반환한다.
void uncaughtException(Thread t, Throwable e)
// -> 쓰레드 그룹의 쓰레드가 처리되지 않은 예외에 의해 실행이 종료되었을때,
// -> JVM에 의해 이 메서드가 자동적으로 호출 된다.데몬 쓰레드(daemon thread)
데몬 쓰레드는 다른 일반 쓰레드(데몬 쓰레드가 아닌 쓰레드)의 작업을 돕는 보조적인 역할을 수행하는 쓰레드이다. 일반 쓰레드가 모두 종료되면 데몬 쓰레드는 강제적으로 자동 종료되는데, 그 이유는 데몬 쓰레드는 일반 쓰레드의 보조역할을 수행하므로 일반 쓰레드가 모두 종료되고 나면 데몬 쓰레드의 존재 의미가 없기 때문이다.
이 점을 제외하고는 데몬 쓰레드와 일반 쓰레드는 다르지 않다. 데몬 쓰레드의 예로는 가비지 컬렉터, 워드프로세서의 자동저장, 화면자동갱신 등이 있다.
데몬 쓰레드는 무한루프와 조건문을 이용해서 실행 후 대기하고 있다가 특정 조건이 만족되면 자업을 수행하고 다시 대기하도록 작성한다.
데몬 쓰레드는 일반 쓰레드의 작성방법과 실행방법이 같으며 다만 쓰레드를 생성한 다음 실행하기 전에 setDamon(true)를 호출하기만 하면 된다. 그리고 데몬 쓰레드가 생성한 쓰레드는 자동적으로 데몬 쓰레드가 된다는 점도 알아두자.
boolean isDaemon() : 쓰레드가 데몬 쓰레드인지 확인한다.
void setDaemon(boolean on) : 쓰레드를 데몬 쓰레드로 또는 사용자 쓰레드로 변경한다. 매개변수 on의 값을 true로 지정하면 데몬 쓰레드가 된다.
Thread t = new Thread(new ThreadEx10());
t.setDaemon(true); // 이 부분이 없으면 종료되지 않는다.
t.start();setDaemon메서드는 반드시 start()를 호출하기 전에 실행되어야 한다. 그렇지 않으면 IllegalThreadStateException이 발생한다.
쓰레드의 실행제어
쓰레드 프로그래밍이 어려운 이유는 동기화(synchronization)와 스케줄링(scheduling)
때문이다. 앞서 우선순위를 통해 쓰레드간의 스케줄링을 하는 방법을 배우기는 했지만, 이것만으로는 한참 부족하다. 효율적인 멀티쓰레드 프로그램을 만들기 위해서는 보다 정교한 스케줄링을 통해 프로세스에게 주어진 자원과 시간을 여러 쓰레드가 낭비없이 잘 사용하도록 프로그래밍 해야 한다.
쓰레드의 스케줄링을 잘하기 위해서는 쓰레드의 상태와 관련 메서드를 잘 알아야 하는데, 먼저 쓰레드의 스케줄링과 관련된 메서드는 다음과 같다.
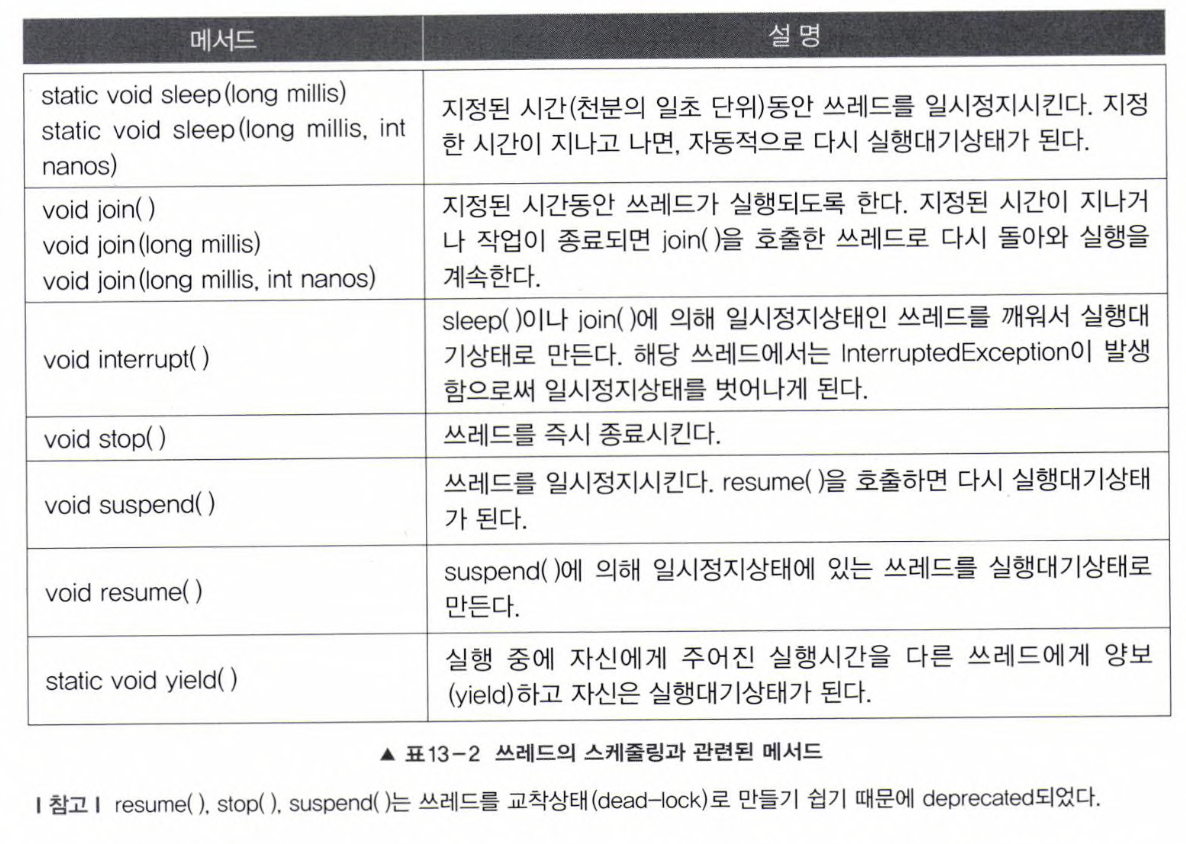
이제 쓰레드의 상태에 대해서 알아보자.
| 상태 | 설명 |
|---|---|
| NEW | 쓰레드가 생성되고 아직 start()가 호출되지 않은 상태 |
| RUNNABLE | 실행 중 또는 실행 가능한 상태 |
| BLOCKED | 동기화블럭에 의해서 일시정지된 상태(lock이 풀릴 때가지 기다리는 상태) |
| WAITING, TIMED_WAITING | 쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은(unrunnable) 일시정지 상태. TIMED_WAITING은 일시정지시간이 지정된 경우를 의미한다. |
| TERMINATED | 쓰레드의 작업이 종료된 상태 |
다음 그림은 쓰레드의 생성부터 소멸까지의 모든 과정을 그린 것인데, 앞서 소개한 메서드들에 의해서 쓰레드의 상태가 어떻게 변화되는지를 잘 보여준다.
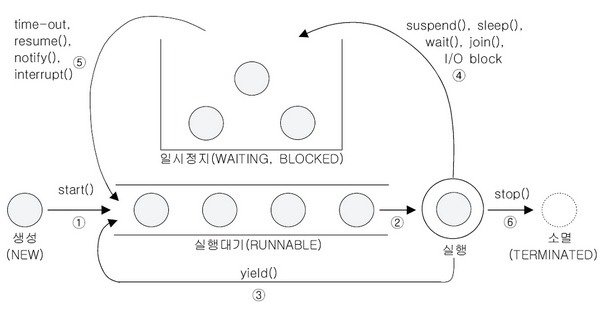
- 쓰레드를 생성하고 start()를 호출하면 바로 실행되는 것이 아니라 실행대기열에 저장되어 자신의 차례가 될 때까지 기다려야 한다. 실행대기열은 큐와 같은 구조로 먼저 실행대기열에 들어온 쓰레드가 먼저 실행된다.
- 실행대기상태에 있다가 자신의 차례가 되면 실행상태가 된다.
- 주어진 실행시간이 다 되거나 yield()를 만나면 다시 실행대기상태가 되고 다음 차례의 쓰레드가 실행 상태가 된다.
- 실행 중에 suspend(), sleep(), wait(), join(), I/O block에 의해 일시정지 상태가 될 수 잇다. I/O block은 입출력작업에서 발생하는 지연상태를 말한다. 사용자의 입력을 기다리는 경우를 예로 들 수 잇는데, 이런 경우 일시정지 상태에 있다가 사용자가 입력을 마치면 다시 실행대기 상태가 된다.
- 지정된 일시정지 시간이 다 되거나(time-out), notify(), resume(), interrupt()가 호출되면 일시정지상태를 벗어나 다시 실행대기열에 저장되어 자신의 차례를 기다리게 된다.
- 실행을 모두 마치거나 stop()이 호출되면 쓰레드는 소멸한다.
sleep(long millis) - 일정시간동안 쓰레드를 멈추게 한다.
sleep()은 지정된 시간동안 쓰레드를 멈추게 한다.
static void sleep(long millis)
static void sleep(long millis, int nanos)sleep()에 의해 일시정지 상태가 된 쓰레드는 지정된 시간이 다 되거나 interrupt()가 호출되면 (InterruptedException 발생), 잠ㅈ에서 깨어나 실행대기 상태가 된다.
그래서 sleep()를 호출할 때는 항상 try-catch문으로 예외를 처리해줘야 한다.
th1.start();
th2.start();
try {
th1.sleep();
} catch (InterruptedException e) {
System.out.println("<<main 종료>>");
}쓰레드 th1과 th2에 대해 start() 호출하자마자 th1.sleep(2000)를 호출하여 쓰레드 th1이 2초 동안 작업을 멈추고 일시정지 상태에 있도록 하였으니까 th1이 가장 늦게 종료되어야 하는데 실제로는 제일 먼저 종료된다.
그 이유는 sleep()이 항상 실행 중인 쓰레드에 대해 작동하기 떄문이 th1.sleep(2000)과 같이 호출하였어도 실제로 영향을 받는 것은 main 메서드를 실행하는 main쓰레드이다.
그래서 sleep()은 static으로 선언되어 있으며 참조변수를 이용해서 호출하기 보다는 Thread.sleep(2000);과 같이 해야 한다.
interrupt()와 interrupted() - 쓰레드의 작업을 취소한다.
진행 중인 쓰레드의 작업이 끝나기 전에 취소시켜야할 때가 있다. 예를 들어 큰 파일을 다운로드 받을 때 시간이 너무 오래 걸리면 중간에 다운로드를 포기하고 취소하고 있어야 한다. interrupt()는 쓰레드에게 작업을 멈추라고 요청한다. 단지 멈추라고 요청만 하는 것일 뿐 쓰레드를 강제로 종료시키지는 못한다. interrupt()는 그저 쓰레드의 interrupted 상태(인스턴스 변수)를 바꾸는 것일 뿐이다.
그리고 interrupted()는 쓰레드에 대해 interrupt()가 호출되었는지 알려준다. interrupt()가 호출되지 않았다면 false를 호출되었다면 true를 반환한다.
Thread th = new Thread();
th.start();
...
th.interrupt(); // 쓰레드 th에 interrupt()를 호출한다.
class MyThread extends Thread {
public void run() {
while(!interrupted()) { // interrupted()의 결과가 false인 동안 반복
...
}
}
}interrupted()가 호출되면, interrupted()의 결과가 false에서 true로 바뀌어 while문을 벗어나게 된다. while문의 조건식에 !가 포함되어 있는 것에 주의하자.
isInterrupted()도 쓰레드의 interrupt()가 호출되었는지 확인하는데 사용할 수 있지만, interrupted()와 달리 isInterrupted()는 쓰레드의 interrupted 상태를 false로 초기화하지 않는다.
void interrupt() // 쓰레드의 interrupted 상태를 false에서 true로 변경
boolean isInterrupted() // 쓰레드의 interrupted 상태를 반환.
static boolean interrupted() // 현재 쓰레드의 interrupted 상태를 반환 후, false로 변경쓰레드가 sleep(), wait(), join()에 의해 일시정지 상태(WAITING)에 있을 때, 해당 쓰레드에 대해 interrupt()를 호출하면, sleep(), wait(), join()에서 InterruptedException이 발생하고 쓰레드는 실행대기 상태(RUNNABLE)로 바뀐다. 즉, 멈춰있던 쓰레드를 깨워서 실행가능한 상태로 만드는 것이다.
class Main {
public static void main(String args[]) throws Exception {
ThreadTest th1 = new ThreadTest();
th1.start();
String input = "test";
th1.interrupt();
}
}
class ThreadTest extends Thread {
public void run() {
int i = 0;
while(i != 0 && !isInterrupted()) {
System.out.println(i--);
for(long x=0; x < 25000000L; x++);
}
}
}class Main {
public static void main(String args[]) throws Exception {
ThreadTest th1 = new ThreadTest();
th1.start();
String input = "test";
th1.interrupt();
}
}
class ThreadTest extends Thread {
public void run() {
int i = 0;
while(i != 0 && !isInterrupted()) {
System.out.println(i--);
try {
Thread.sleep(1000) // 1초 지연
} catch(InterruptedException e ) {
}
}
}
}위 두개의 예제에서 for문을 실행하면 프로그램이 중간에 종료되고 Thread.sleep(1000)으로 1초 동안 지연되도록 변경하면, 출력이 종료되지 않는다. isInterrupted()의 결과를 출력해보면 false이다. 왜 그럴까?
그 이유는 Thread.sleep(1000)에서 InterruptedException이 발생했기 때문이다. sleep()에 의해 쓰레드가 잠시 멈춰있을 때, interrupt()를 호출하면 InterruptedException이 발생되고 쓰레드의 interrupted상태는 fasle로 자동 초기화된다.
try {
Thread.sleep();
} catch (InterruptedException e) {
interrupt(); // 추가
}그럴 때는 위와 같이 catch 블록에 interrupt()를 추가로 넣어줘서 쓰레드의 interrupted 상태를 true로 바꿔줘야 한다.
suspend(), resume(), stop()
suspend()는 sleep()처럼 쓰레드를 멈추게 한다. suspend()에 의해 정지된 쓰레드는 resum()을 호출해야 다시 실행대기 상태가 된다. stop()은 호출되는 즉시 쓰레드가 종료된다.
suspend(), resume(), stop()은 쓰레드의 실행을 제어하는 가장 손쉬운 방법이지만, suspend()와 stop()이 교착상태(deadlock)를 일으키기 쉽게 작성되어있으므로 사용이 권장되지 않는다. 그래서 이 메서드들은 모두 deprecated되었다. JAVA API 문서 stop()을 찾아보면 Deprecated.라고 적혀있다.
yield() - 다른 쓰레드에게 양보한다.
yield()는 쓰레드 자신에게 주어진 실행시간을 다음 차례의 쓰레드에게 양보(yield)한다.
예를 들어 스케쥴러에 의해 1초의 실행을 할당받은 쓰레드가 0.5초의 시간동안 작업한 상태에서 yield()가 호출되면, 나머지 0.5초는 포기하고 다시 실행대기상태가 된다.
yield()와 interrupted()를 적절히 사용하면, 프로그램의 응답성을 높이고 보다 효율적인 실행이 가능하게 할 수 있다.
join() - 다른 쓰레드의 작업을 기다린다.
쓰레드 자신이 하던 작업을 잠시 멈추고 다른 쓰레드가 지정된 시간동안 작업을 수행하도록 할 때 join()을 사용한다.
void join()
void join(long millis)
void join(long millis, int nanos)시간을 지정하지 않으면, 해당 쓰레드가 작업을 모두 마칠때까지 기다리게 된다. 작업 중에 다른 쓰레드의 작업이 수행되어야할 필요가 있을 때 join()을 사용한다.
try {
th1.join(); // 현재 실행중인 쓰레드가 쓰레드 th1의 작업이 끝날때까지 기다린다.
} catch (InterruptedException e) {}join()도 sleep()처럼 interrupt()에 의해 대기상태에서 벗어날 수 있으며, join()이 호출되는 부분을 try-catch문으로 감싸야 한다. join()은 여러모로 sleep()과 유사한 점이 많은데, sleep()과 다른 점은 join()은 현재 쓰레드가 아닌 특정 쓰레드에 대해 동작하므로 static 메서드가 아니라는 것이다.
쓰레드의 동기화
싱글쓰레드 프로세스의 경우 프로세스 내에서 단 하나의 쓰레드만 작업하기 떄문에 프로세스의 자원을 가지고 작업하는데 별문제가 없지만, 멀티쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 주게 된다. 만일 쓰레드A가 작업하던 도중에 다른 쓰레드B에게 제어권이 넘어갔을 때, 쓰레드 A가 작업하던 공유데이터를 쓰레드B가 임의로 변경하였다면, 다시 쓰레드 A가 제어권을 받아서 나머지 작업을 마쳤을 때 원래 의도했던 것과는 다른 결과를 얻을 수 있다.
이러한 일이 발생하는 것을 방지하기 위해서 한 쓰레드가 특정 작업을 끝마치기 전까지 다른 쓰레드에 의해 방해받지 않도록 하는 것이 필요하다. 그래서 도입된 개념이 바로 임계 영역(critical section과 잠금(락, lock)이다.
공유 데이터를 사용하는 코드 영역을 임계 영역으로 지정해놓고, 공유 데이터(객체)가 가지고 있는 lock을 획득한 단 하나의 쓰레드만 이 영역 내의 코드를 수행할 수 있게 한다. 그리고 해당 쓰레드가 임계 영역 내의 모든 코드를 수행하고 벗어나서 lock을 반납해야만 다른 쓰레드가 반납된 lock을 획득하여 임계 영역의 코드를 수행할 수 있게 된다.
이처럼 한 쓰레드가 진행 중인 작업을 다른 쓰레드가 간섭하지 못하도록 막는 것을 쓰레드의 동기화(synchronization)라고 한다.
자바에서는 synchronized 블럭을 이용해서 쓰레드의 동기화를 지원했지만, JDK 1.5부터는 java.util.concurrent.locks와 java.util.concurrent.atomic 패키지를 통해서 다양한 방식으로 동기화를 구현할 수 있도록 지원하고 있다.
synchronized를 이용한 동기화
먼저 가장 간단한 방법인 synchronized 키워드를 이용한 동기화에 대해서 알아보자. 이 키워드는 임계 영역을 설정하는데 사용된다. 아래와 같이 두 가지 방식이 있다.
// 1. 메서드 전체를 임계 영역으로 지정
public synchronized void calcSum() { // 임계 영역
...
} // 임계 영역// 2. 특정한 영역을 임계 영역으로 지정
synchronized(객체의 참조변수) { // 임계영역
...
} // 임계 영역첫 번째 방법은 메서드 앞에 synchronized를 붙이는 것인데, synchronized를 붙이면 메서드 전체가 임계 영역으로 설정된다. 쓰레드는 synchronized 메서드가 호출된 시점부터 해당 메서드가 포함된 객체의 lock을 얻어 작업을 수행하다가 메서드가 종료되면 lock을 반환한다.
두 번째 방법은 메서드 내의 코드 일부를 블럭{}으로 감싸고 앞에 synchronized(참조변수)를 붙이는 것인데, 이때 참조변수는 락을 걸고자하는 객체를 참조하는 것이어야 한다. 이 블럭을 synchronized 블럭이라고 부르며, 이 블럭의 영역 안으로 들어가면서부터 쓰레드는 지정된 객체의 lock을 얻게 되고, 이 블럭을 벗어나면 lock을 반납한다.
두 방법 모두 lock의 획득과 반납을 모두 자동적으로 이루어지므로 우리가 해야 할 일은 그저 임계 영역만 설정해주는 것뿐이다.
모든 객체는 lock을 하나씩 가지고 있으며, 해당 객체의 lock을 가지고 있는 쓰레드만 임계 영역으로 코드를 수행할 수 있다. 그리고 다른 쓰레드들은 lock을 얻을 때까지 기다리게 된다.
임계 영역은 멀티쓰레드 프로그램의 성능을 좌우하기 때문에 가능하면 메서드 전체에 락을 거는 것보다 synchronized블럭으로 임계 영역을 최소화해서 보다 효율적인 프로그램이 되도록 노력해야 한다.
public class ThreadEx {
public static void main(String[] args) {
Runnable r = new RunnableEx();
new Thread(r).start();
new Thread(r).start();
}
}
class Account{
private int balance = 1000; //private으로 해야 동기화가 의미있음.
public int getBalance() {
return balance;
}
public void withdraw(int money) {
if(balance >= money) {
try {
Thread.sleep(1000);
}catch (Exception e) {
// TODO: handle exception
}
balance -= money;
}
}
}
class RunnableEx implements Runnable{
Account acc = new Account();
public void run() {
while(acc.getBalance() > 0) {
//100,200,300중의 한 값을 임의로 선택해서 출금
int money = (int)(Math.random() * 3 + 1) * 100;
acc.withdraw(money);//출금
System.out.println("balance : " + acc.getBalance());
}
}
}실행 결과
balance: 700
balance: 400
balance: 200
balance: 000
balance: -100
은행계좌(account)에서 잔고(balance)를 확인하고 임의의 금액을 출금(withdraw)하는 예제이다. 아래 코드를 보면 잔고가 출금보다 큰 경우에만 출금 가능하도록 되어 있다.
if(balance >= money) {
try {
Thread.sleep(1000);
}catch (Exception e) {
}
balance -= money;
} // withdraw하지만 실행결과를 보면 잔고(balance)가 음수인 것을 볼 수 있다. 어찌된 것일까? 그 이유는 한 쓰레드가 if문의 조건식을 통과하고 출금하기 바로 직전에 다른 쓰레드가 끼어들어서 출금을 먼저 했기 때문이다.
예제에서는 상황을 보여주기 위해 일부로 Thread.sleep(1000)을 사용해서 if문을 통과하자마자 다른 쓰레드에게 제어권을 넘기도록 하였지만, 굳이 이렇게 하지 않더라도 이처럼 한 쓰레드의 작업이 다른 쓰레드에 의해서 영향을 받는 일이 발생할 수 있기 때문에 동기화가 반드시 필요하다. 아래와 같이 withdraw 메소드에 synchronized 키워드를 붙이기만 하면 간단히 동기화가 된다.
public synchronized void withdraw(int money) {
if(balance >= money) {
try {
Thread.sleep(1000);
}catch (Exception e) {
// TODO: handle exception
}
balance -= money;
}
}한 쓰레드에 의해 먼저 withdraw()가 호출되면, 이 메서드가 종료되어 lock이 반납될 때까지 다른 쓰레드는 withdraw()를 호출하더라도 대기상태에 머물게 된다.
메서드 앞에 synchronized를 붙이는 대신, synchronized 블럭을 사용하면 다음과 같다.
public void withdraw(int money) {
synchronized(this) {
if(balance >= money) {
try {
Thread.sleep(1000);
}catch (Exception e) {
// TODO: handle exception
}
balance -= money;
}
}
}wait()과 notify()
synchronized로 동기화해서 공유 데이터를 보호하는 것까지는 좋은데, 특정 쓰레드가 객체의 락을 가진 상태로 오랜 시간을 보내지 않도록 하는 것도 중요하다. 만일 계좌에 출금할 돈이 부족해서 한 쓰레드가 락을 보유한 채로 돈이 입금될 때까지 오랜 시간을 보낸다면, 다른 쓰레드들은 모두 해당 객체의 락을 기다리느라 다른 작업들도 원활히 진행되지 않을 것이다.
이러한 상황을 개선하기 위해 고안된 것이 바로 wait()와 notify()이다. 동기화된 임계 영역의 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니면, 일단 wait()을 호출하여 쓰레드가 락을 반납하고 기다리게 한다. 그러면 다른 쓰레드가 락을 얻어 해당 객체에 대한 작업을 수행할 수 있게 된다. 나중에 작업을 진행할 수 있는 상황이 되면 notify()를 호출해서, 작업을 중단했던 쓰레드가 다시 락을 얻어 작업을 진행할 수 있게 한다.
차이가 있다면, 오래 기다린 쓰레드가 락을 얻는다는 보장이 없다는 것이다. wait()이 호출되면, 실행 중이던 쓰레드는 해당 객체의 대기실(waiting pool)에서 통지를 기다린다. notify()가 호출되면, 해당 객체에 대기실에 있던 모든 쓰레드 중에서 임의의 쓰레드만 통지를 받는다. notifyAll()은 기다리고 있는 모든 쓰레드에게 통보를 하지만, 그래도 lock을 얻을 수 있는 것은 하나의 쓰레드일 뿐이고 나머지 쓰레드는 통보받긴 했지만, lock을 얻지 못하면 다시 lock을 기다리는 신세가 된다.
wait()과 notify()는 특정 객체에 대한 것이므로 Object클래스에 정의되어 있다.
void wait()
void wait(long timeout)
void wait(long timeout, int nanos)
void notify()
void notifyall()wait()은 notify() 또는 notifyAll()이 호출될 때까지 기다리지만, 매개변수가 있는 wait()은 지정된 시간동안만 기다린다. 즉, 지정된 시간이 지난 후에 자동적으로 notify()가 호출되는 것과 같다.
그리고 waiting pool은 객체마다 존재하는 것이므로 notifyAll()이 호출된다고 해서 모든 객체의 waiting pool에 있는 쓰레드가 꺠워지는 것은 아니다. notifyAll()이 호출된 객체의 waiting pool에 대기 중인 쓰레드만 해당된다는 것을 기억하자.
wait(), notify(), notifyAll()
- Object에 정의되어 있다.
- 동기화 블럭(synchronized 블록)내에서만 사용할 수 있다.
- 보다 효율적인 동기화를 가능하게 한다.
기아 현상과 경쟁 상태
지독하게 운이 나쁘면 쓰레드는 계속 통지를 받지 못하고 오랫동안 기다리게 되는데 이걸 기아(starvation) 현상이라고 한다. 이 현상을 막으려면 notify() 대신 notifyAll()을 사용해야 한다.
notifyAll()로 관련된 쓰레드의 기아현상은 막았지만, 관련없는 쓰레드까지 통지를 받아서 불필요하게 연관된 쓰레드와 lock을 위해 경쟁하게 된다.
여러 쓰레드가 lock을 얻기 위해 서로 경쟁하는 것을 경쟁 상태(race condition)이라고 하는데, 이 경쟁 상태를 개선하기 위해서는 관련된 쓰레드와, 관련없는 쓰레드를 구별해서 통지하는 것이 필요하다.
곧 배우게 될 Lock와 Condition을 이용하면, wait() & notify()로는 불가능한 선별적인 통지가 가능하다.
Lock과 Condition을 이용한 동기화
동기화할 수 있는 방법은 synchronized 블럭 외에도 lock 클래스를 이용하는 방법이 있다.
synchronized 블럭으로 동기화를 하면 자동적으로 lock이 잠기고 풀리기 때문에 편리하다. 심지어 synchronized 블럭 내에서 예외가 발생해도 lock은 자동적으로 풀린다. 그러나 때로는 같은 메서드 내에서만 lock을 걸 수 있다는 제약이 불편하기도 하다. 그럴 때 lock 클래스를 사용한다. lock 클래스의 종류는 다음과 같이 3가지가 있다.
ReentrantLock : 재진입이 가능한 lock. 가장 일반적인 배타 lock
ReentrantReadWriteLock : 읽기에는 공유적이고, 쓰기에는 배타적인 lock
StampedLock : ReentrantReadWriteLock에 낙관적인 lock의 기능을 추가
ReentrantLock은 가장 일반적인 lock이다. reentrant(재진입할 수 있는)이라는 단어가 앞에 붙은 이유는 우리가 앞서 wait() & notify()에서 배운 것처럼, 특정 조건에서 lock을 풀고 나중에 다시 lock을 얻고 임계영역으로 들어와서 이후의 작업을 수행할 수 있기 때문이다. 지금까지 우리가 lock이라고 불러왔던 것과 일치한다.
ReentrantReadWriteLock은 이름에서 알 수 있듯이, 읽기를 위한 lock과 쓰기를 위한 lock를 제공한다. ReentrantLock은 배타적인 lock이라서 무조건 lock이 있어야만 임계 영역의 코드를 수행할 수 있지만, ReentrantReadWriteLock은 읽기 lock이 걸려있으면, 다른 쓰레드가 읽기 lock을 중복해서 걸고 읽기를 수행할 수 있다. 읽기는 내용을 변경하지 않으므로 동시에 여러 쓰레드가 읽어도 문제가 되지 않는다. 그러나 읽기 lock이 걸린 상태에서 쓰기 lock을 거는 것은 허용되지 않는다. 반대의 경우에도 마찬가지다. 읽기를 할 때는 읽기 lock를 걸고, 쓰기를 할 때는 쓰기 lock을 거는 것일 뿐 lock을 거는 방법은 같다.
StampedLock은 lock을 걸거나 해지할 때 스탬프(long타입의 정수값)를 사용하며, 읽기와 쓰기를 위한 lock외에 낙관적 읽기 lock(optimistic reading lock)이 추가된 거이다. 읽기 lock이 걸려있으면, 쓰기 lock을 얻기 위해서는 읽기 lock이 풀릴 때까지 기다려야 하는데 비해 낙관적 읽기 lock은 쓰기 lock에 의해 바로 풀린다. 그래서 낙관적 읽기에 실패하면, 읽기 lock을 얻어서 다시 읽어 와야 한다. 무조건 읽기 lock을 걸지 않고, 쓰기와 읽기가 충돌할 때만 쓰기가 끝난 후에 읽기 lock을 거는 것이다.
ReentrantLock의 생성자
ReentrantLock은 다음과 같이 두 개의 생성자를 가지고 있다.
ReentrantLock()
ReentrantLock(boolean fair)생성자의 매개변수를 true로 주면, lock이 풀렸을 때 가장 오래 기다린 쓰레드가 lock을 획득할 수 있게, 즉 공정(fair)하게 처리한다. 그러나 공정하게 처리하려면 어떤 쓰레드가 가장 오래 기다렸는지 확인하는 과정을 거칠 수밖에 없으므로 성능은 떨어진다.
대부분의 경우 굳이 공정하게 처리하지 않아도 문제가 되지 않으므로 공정함보다 성능을 선택한다.
void lock() // lock을 잠근다.
void unlock() // lock을 해지한다.
void isLocked() // lock이 잠겼는지 확인한다.자동적으로 lock의 잠금과 해제는 관리되는 synchronized 블럭과 달리, ReentrantLock과 같은 lock 클래스들은 수동적으로 lock을 잠그고 해제해야 한다. 그래도 lock을 잠그고 푸는 것은 간단하다. 그저 메서드를 호출하기만 하면 될 뿐이다. lock을 걸고 나서 푸는 것을 잊어버리는 실수를 하지 않도록 주의를 기울여아 한다는 것은 잊지 말자.
ReentrantLock과 Condition
앞서 wait() & notify() 예제에 요리사 쓰레드와 손님 쓰레드를 구분해서 통지하지 못한다는 단점을 기억할 것이다. Condition은 이 문제점을 해결하기 위한 것이다.
wait() & notify()로 쓰레드의 종류를 구분하지 않고, 공유 객체의 waiting pool에 같이 몰아넣는 대신, 손님 쓰레드를 위한 Condition과 요리사 쓰레드를 위한 Condition을 만들어서 각각의 waiting pool에서 따로 기다리도록 하면 문제는 해결된다.
Condition은 이미 생성된 lock으로부터 newCondition()을 호출해서 생성한다.
private ReentrantLock lock = new ReentrantLock(); // lock을 생성
// lock으로 condition을 생성
private Condition forCook = lock.newCondition();
private Condition forCust = lock.newCondition();위의 코드에서 두 개의 Condition을 생성했는데, 하나는 요리사 쓰레드를 위한 것이고 다른 하나는 손님 쓰레드를 위한 것이다. 그 다음엔, wait() & notify() 대신 Condition의 await() & signal()을 사용하면 그걸로 끝이다.
| Object | Condition |
|---|---|
| void wait() | void await() void awaitUninterruptibly() |
| void wait(long timeout) | boolean await(long time, TimeUnit unit) long awaitNanos(long nanosTimeout) boolean awaitUntil(Date deadline) |
| void notify() | void signal() |
| void notifyAll() | void signalAll() |
volatile
요즘은 대부분 멀티 코어 프로세서가 장착된 컴퓨터를 사용한다. 멀티 코어 프로세서에서는 코어마다 별도의 캐시를 가지고 있다.
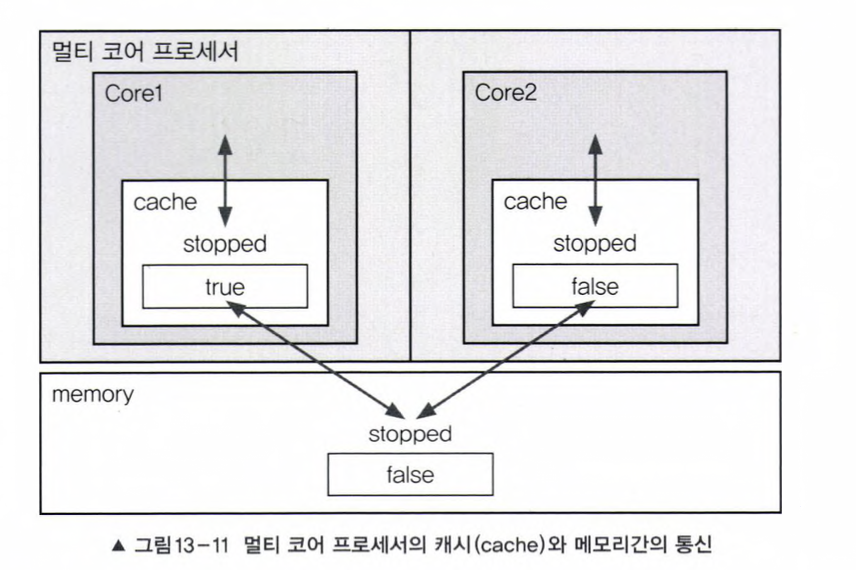
코어는 메모리에서 읽어온 값을 캐시에 저장하고 캐시에서 값을 읽어서 작업한다. 다시 같은 값을 읽어올 때는 먼저 캐시에 있는지 확인하고 없을 때만 메모리에서 읽어온다.
그러다보니 도중에 메모리에 저장된 변수의 값이 변경되었는데도 캐시에 저장된 값이 갱신되지 않아서 메모리에 저장된 값이 다른 경우가 발생한다. 그래서 특정 값이 바뀌었는데도 쓰레드가 멈추지 않고 계속 실행되는 경우가 있는 것이다.
volatile boolean suspend = false;
volatile boolean stopped = false;그러나 위와 같이 voltile을 붙이면, 코어가 변수의 값을 읽어올 때 캐시가 아닌 메모리에서 읽어오기 때문에 캐시와 메모리간의 값의 불일치가 해결된다.
변수에 volatile을 붙이는 대신에 synchronized 블럭을 사용해도 같은 효과를 얻을 수 있다. 쓰레드가 synchronized 블럭으로 들어갈 때와 나올 때, 캐시와 메모리간의 동기화가 이루어지기 때문에 값의 불일치가 해소되기 때문이다.
public synchronized void stop() {
stopped = true;
}volatile로 long과 double을 원자화
JVM은 데이터를 4 byte(=32bit)단위로 처리하기 때문에, int와 int보다 작은 타입들은 한 번에 읽거나 쓰는 것이 가능하다. 즉, 단 하나의 명령어로 읽거나 쓰기가 가능하다는 뜻이다. 하나의 명령어에 더 이상 나눌 수 없는 최소의 작업단위이므로, 작업의 중간에 다른 쓰레드가 끼어들 틈이 없다.
그러나, 크기가 8 byte인 long과 double타입의 변수는 하나의 명령어로 값을 읽거나 쓸 수 없기 때문에, 변수의 값을 읽는 과정에 다른 쓰레드가 끼어들 여지가 있다. 다른 쓰레드가 끼어들지 못하게 하려고 변수를 읽고 쓰는 모든 문장을 synchronized 블럭으로 감쌀 수도 있지만, 더 간단한 방법이 있다. 변수를 선언할 때 volatile을 붙이는 것이다.
volatile long sharedVal; // long 타입의 변수(8 byte)를 원자화
volatile double sharedVal; // double 타입의 변수(8 byte)를 원자화volatile은 해당 변수에 대한 읽거나 쓰기가 원자화된다. 원자화라는 것은 작업을 더 이상 나눌 수 없게 한다는 의미인데, synchronized 블럭도 일종의 원자화라고 할 수 있다. 즉, synchronized 블럭은 여러 문장을 원자화함으로써 쓰레드의 동기화를 구현한 것이라고 보면 된다.
volatile은 변수의 읽거나 쓰기를 원자화 할 뿐, 동기화하는 것은 아니라는 점에 주의하자. 동기화가 필요할때 synchronized 블럭 대신 volatile을 쓸 수 없다.
volatile long balance; // 인스턴스 변수 balance를 원자화 한다.
synchronized int getBalance() { // balance의 값을 반환한다.
return balance;
}
synchronized void withdraw(int money) { // balance의 값을 변경
if (balance >= money) {
balance -= money;
}
}인스턴스변수 balance를 volatile로 원자화했으니까, 이 값을 읽어서 반환하는 메서드 getBalance()를 동기화할 필요가 없다고 생각할 수 있다. 그러나 getBalance()를 synchronized로 동기화하지 않으면, withdraw()가 호출되어 객체에 lock을 걸고 작업을 수행하는 중인데도 getBalance()가 호출되는 것이 가능해진다. 출금이 진행 중일 때는 기다렸다가 출금이 끝난 후에 잔고를 조회할 수 있도록 하려면 getBalance()에 synchronized를 부여서 동기화해야 한다.
fork & join 프레임웍
10년 전까지만 해도 CPU의 속도는 매년 거의 2년씩 빠르게 향상되어 왔다. 그러나 이제 그 한계에 도달하여 속도 보다는 코어의 개수를 늘려서 CPU의 성능을 향상시키는 방향으로 발전해 가고 있다.
이러한 하드웨어의 변화에 발맞춰 프로그래밍도 멀티 코어를 잘 활용할 수 있는 멀티쓰레드 프로그래밍이 점점 더 중요해지고 있다. 지금까지 배워서 잘 알겠지만 멀티쓰레드 프로그래밍이 그리 쉽지는 않다.
그래서 JDK1.7부터 fork & join 프레임웍이 추가되었고, 이 프레임웍은 하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 준다.
먼저 수행할 작업에 따라 RecursiveAction과 RecursiveTask, 두 클래스 중에서 하나를 상속받아 구현해야 한다.
RecursiveAction : 반환값이 없는 작업을 구현할 때 사용
RecursiveTask : 반환값이 있는 작업을 구현할 때 사용
두 클래스가 모두 compute()라는 추상 메서드를 가지고 있는데, 우리는 상속을 통해 이 추상 메서드를 구현하기만 하면 된다.
예를 들어 1부터 n까지의 합을 계산한 결과를 돌려주는 작업의 구현은 다음과 같이 한다.
class SumTask extends RecursiveTask<Long> { // RecursiveTask를 상속받는다.
long from, to;
SumTask(long from, long to) {
this.from = from;
this.to = to;
}
public Long compute() {
// 처리할 작업을 수행하기 위한 문장을 넣는다.
}
}그 다음에는 쓰레드풀과 수행할 작업을 생성하고, invoke()로 작업을 시작한다. 쓰레드를 시작할 때 run()이 아니라 start()를 호출하는 것처럼, fork & join 프레임웍으로 수행할 작업도 compute()가 아닌 invoke()로 시작한다.
ForkJoinPool pool = new ForkJoinPool(); // 쓰레드 풀을 생성
SumTask task = new SumTask(from, to); // 수행할 작업을 생성
Long result = pool.invoke(task); // invoke()를 호출해서 작업을 시작ForkJoinPool은 fork & join 프레임웍에서 제공하는 쓰레드 풀(thread pool)로, 지정된 수의 쓰레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게 한다. 그리고 쓰레드를 반복해서 생성하지 않아도 된다는 장점과 너무 많은 쓰레드가 생성되어 성능이 저하되는 것을 막아준다는 장점이 있다.
쓰레드 풀은 쓰레드가 수행해야하는 작업이 담긴 큐를 제공하며, 각 쓰레드는 자신의 작업 큐를 담긴 작업을 순서대로 처리한다.
compute()의 구현
compute()를 구현할 때는 수행할 작업 외에도 작업을 어떻게 나눌 것인가에 대해서도 알려줘야 한다.
public Long compute() {
long size = to - from + 1; // from <= i <= to
if (size <= 5) { // 더할 숫자가 5개 이하면
return sum; // 숫자의 합을 반환. sum()은 from부터 to까지의 수를 더해서 반환
}
// 범위를 반으로 나눠서 두 개의 작업을 생성
long half = (from + to) / 2;
SumTask leftSum = new SumTask(from, half);
SumTask rightSum = new SumTask(half + 1, to);
leftSum.fork(); // 작업(leftSum)을 작업 큐에 넣는다.
return rightSum.compute() + leftSum.join();
}실제 수행할 작업을 sum()뿐이고 나머지는 수행할 작업의 범위를 반으로 나눠서 새로운 작업을 생성해서 실행시키기 위한 것이다. 좀 복잡해 보이지만, 작업의 범위를 어떻게 나눌 것인지만 정의해 주면 나머지는 항상 같은 패턴이다.
여기서는 지정된 범위를 절반으로 나누어서 나눠진 범위의 합을 계산하기 위한 새로운 SumTask를 생성하는데, 이 과정은 작업이 더 이상 나눠질 수 없을 때까지, size의 값이 5보다 작거나 같을 때까지, 반복한다.
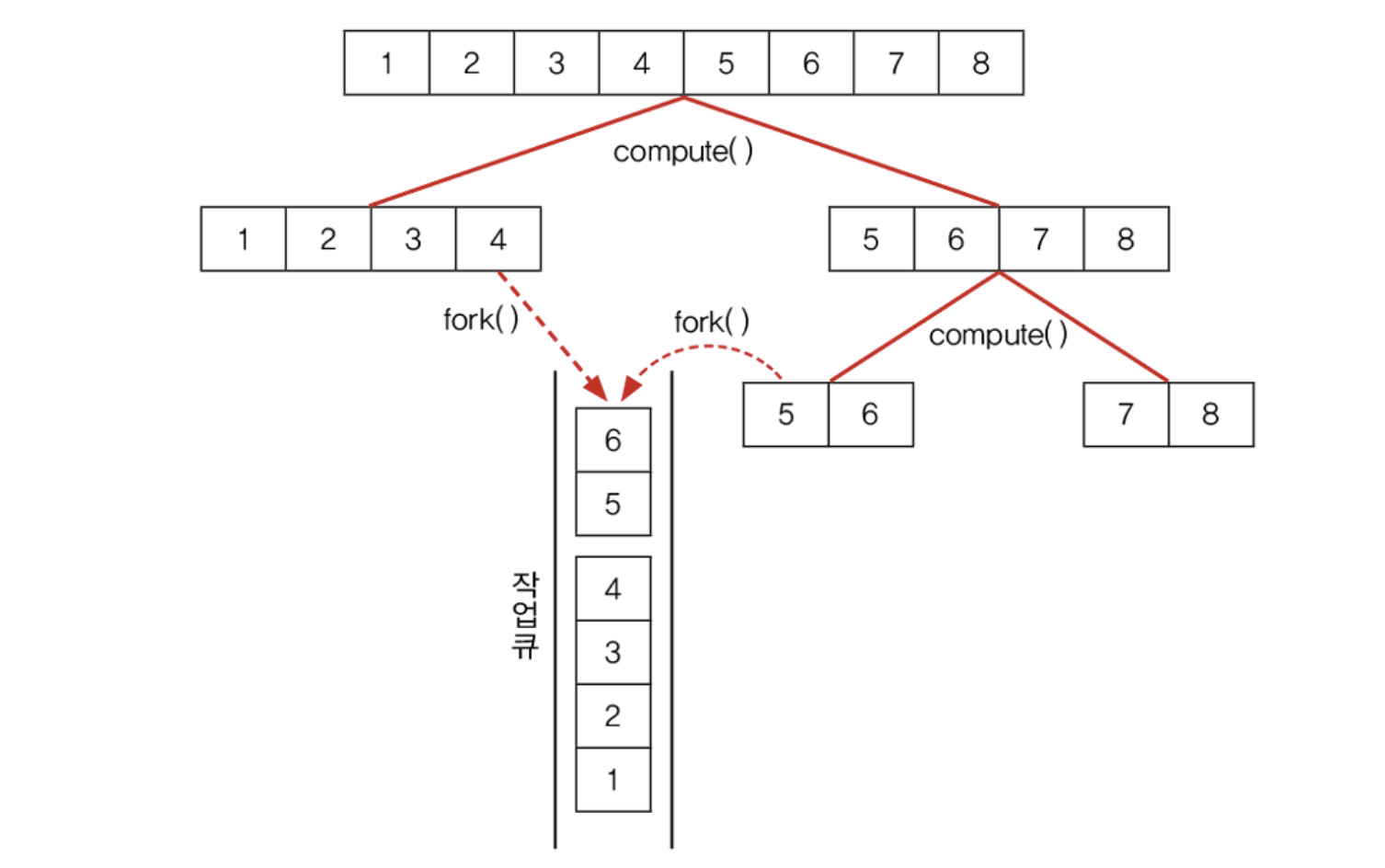
이해를 돕기 위해 1부터 8까지의 숫자를 더하는 과정을 그림으로 그려보았다. 이 그림에서는 작업의 size가 2가 될 때까지 나눈다. compute()가 처음 호출되면, 더할 숫자의 범위를 반으로 나눠서 한 쪽에는 fork()를 호출해서 작업 큐에 저장한다. 하나의 쓰레드는 compute()를 재귀호출하면서 작업을 계속해서 반으로 나누고, 다른 쓰레드는 fork()에 의해 작업 큐에 추가된 작업을 수행한다.
다른 쓰레드의 작업 훔쳐오기
fork()가 호출되어 작업 큐에 추가된 작업 역시, compute()에 의해 더 이상 나눌 수 없을 때까지 반복해서 나뉘고, 자신이 작업 큐가 비어있는 쓰레드는 다른 쓰레드의 작업 큐에서 작업을 가져와서 수행한다. 이것을 작업 훔쳐오기(work stealing)라고 하며, 이 과정은 모두 쓰레드풀에 의해 자동적으로 이루어진다.
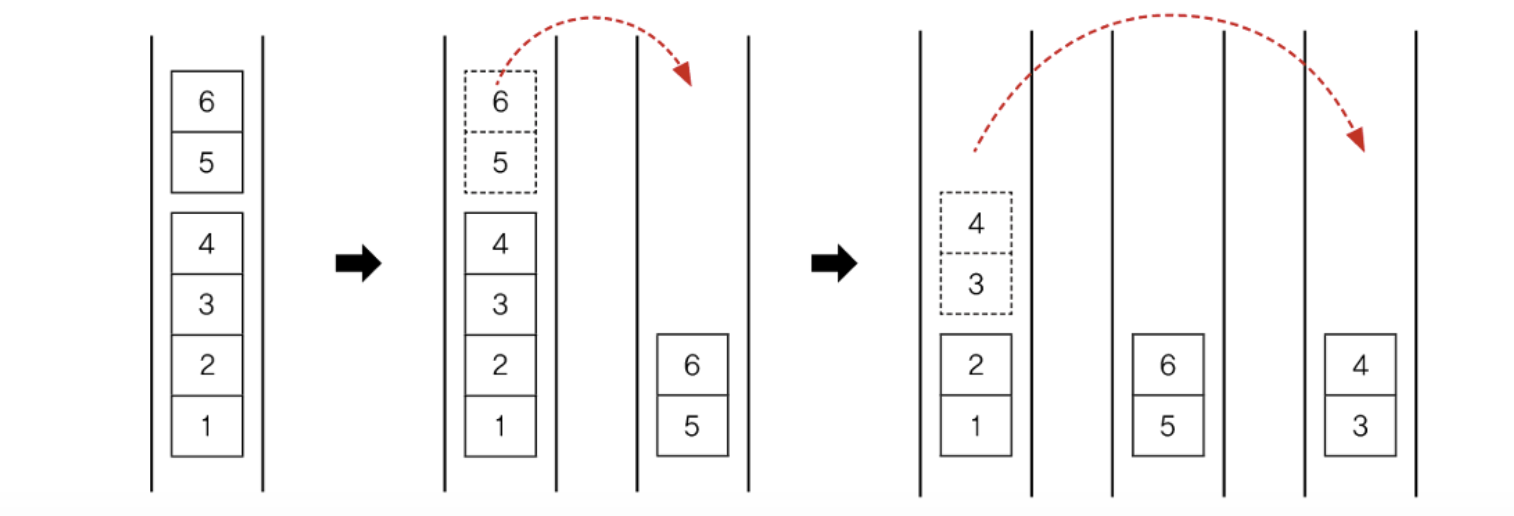
위의 그림은 작업 큐가 비어있는 쓰레드가 다른 쓰레드의 작업을 가져와서 수행하는 것을 그린 것이다. 이런 과정을 통해 한 쓰레드에 작업이 몰리지 않고, 여러 쓰레드가 골고루 작업을 나누어 처리하게 된다.
fork()와 join()
fork()는 작업을 쓰레드의 작업 큐에 넣는 것이고, 작업 큐에 들어간 작업은 더 이상 나눌 수 없을 때까지 나뉜다. 즉 compute()로 나누고 fork()로 작업 큐에 넣는 작업이 계속해서 반복된다. 그리고 나눠진 작업은 각 쓰레드가 골고루 나눠서 처리하고, 작업의 결과는 join()을 호출해서 얻을 수 있다.
for()와 join()의 중요한 차이점이 하나 있는데, 그것은 바로 fork()는 비동기 메서드(asynchronous method)이고, join()은 동기 메서드(synchronous method)라는 것이다.
fork() : 해당 작업을 쓰레드 풀의 작업 큐에 넣는다. 비동기 메서드
join() : 해당 작업의 수행이 끝날 때까지 기다렸다가, 수행이 끝나면 그 결과를 반환한다. 동기 메서드
비동기 메서드는 일반적인 메서드와 달리 메서드를 호출만 할 뿐, 그 결과를 기다리지 않는다. (내부저긍로는 다른 쓰레드에게 작업을 수행하도록 지시만 하고 결과를 기다리지 않고 돌아오는 것이다.) 그래서 아래의 코드에서, fork()를 호출하면 결과를 기다리지 않고 다음 문장인 return문으로 넘어간다.
return문에서 compute()가 재귀호출될 때, join()은 호출되지 않는다. 그러다가 작업을 더 이상 나눌 수 없게 되었을 때, compute()의 재귀호출은 끝나고 join()의 결과를 기다렸다가 더해서 결과를 반환한다. 재귀호출된 compute()가 모두 종료될 때, 최종 결과를 얻는다.
