ParallelStream
Java8에 등장한 Stream은 병렬 처리를 쉽게 할 수 있도록 메소드를 제공해줍니다.
개발자가 직접 스레드 혹은 스레드 풀을 생성할 필요가 없이 parallelStream(), parallel() 만 사용하면 알아서 ForkJoinFramework 관리 방식을 이용하여 작업들을 분할하고 병렬적으로 처리하게 됩니다.
Fork / Join Framework
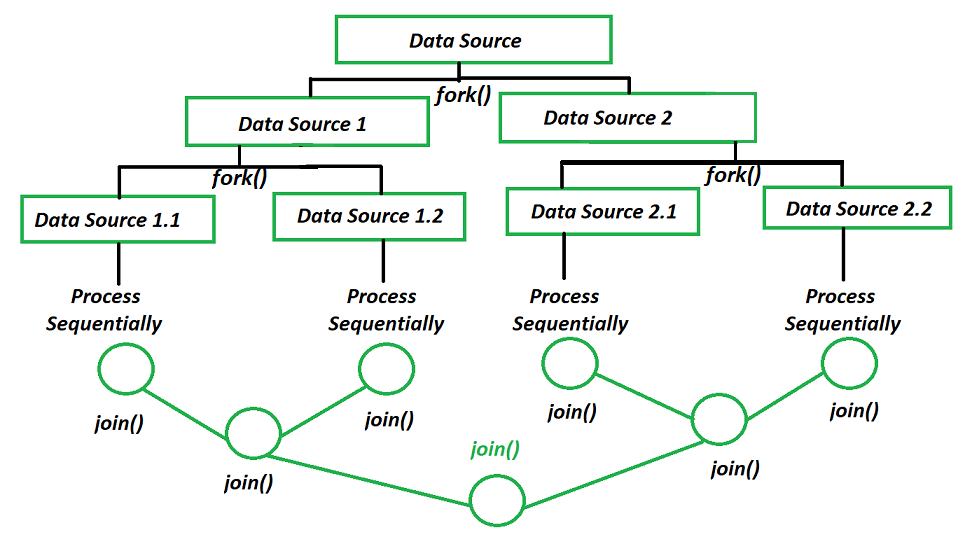
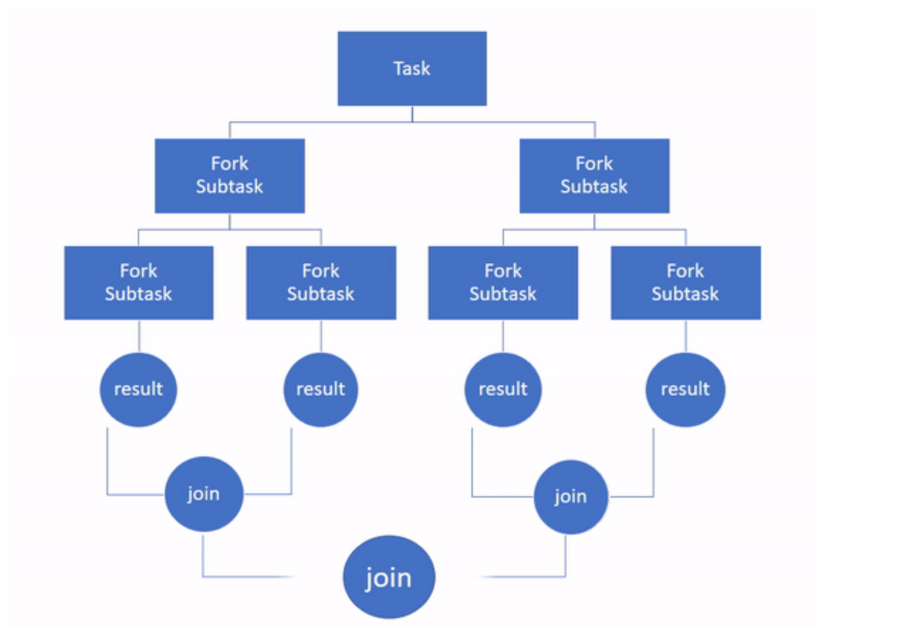
Fork / Join Framework는 작업들을 분할 가능한 만큼 쪼개고, 쪼개진 작업들을 Work Thread를 통해 작업 후 결과를 합치는 과정으로 결과를 만들어 냅니다.
분할 정복(Divide and Conquer) 알고리즘과 흡사하며, Fork를 통해 Task를 분담하고 Join을 통해 결과를 합칩니다.
Fork: 나누다, Join: 합치다
이 프레임워크는 work-stealing 알고리즘을 통해 스레드의 작업 부하를 균형 있게 조절합니다.
ForkJoinPool
작업 중인 스레드를 관리하고 스레드 풀 상태 및 성능에 대한 정보를 얻을 수 있는 도구를 제공하는 ExecutorService의 구현체인 ForkJoinPool은 Fork / Join 프레임워크의 핵심입니다.
work-stealing 알고리즘
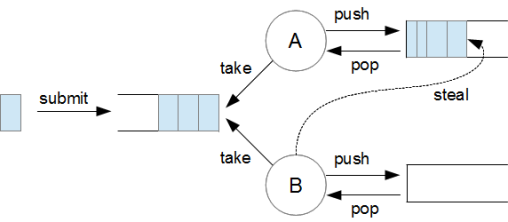
간단히 말하자면, task가 존재하지 않는 스레드는 작업 중인 스레드의 deque에서 작업을 훔쳐옵니다.
위 그림을 보면 작업중인 스레드 A는 자신의 deque에서 작업을 가져옵니다. 작업이 비어있는 스레드 B는 작업이 쌓여있는 스레드 A의 deque의 반대 쪽에서 task를 훔쳐옵니다.
Deque는 양쪽 끝에서 요소를 추가하거나 제거할 수 있는 특징이 있습니다.
Java Stream의 병렬 처리의 장점
병렬 처리란 여러 개의 작업을 동시에 수행하는 처리 방식입니다. 멀티 코어 CPU와 같은 하드웨어를 활용하여 여러 작업을 분산시켜 처리함으로써 처리 속도를 향상시킬 수 있습니다.
직렬 스트림과 병렬 스트림의 성능 비교
직렬 스트림과 병렬 스트림의 성능 비교를 위해 간단한 환경을 구성하여 테스트 코드를 작성해봤습니다.
총 100만건의 더미 데이터를 DB에 넣는 로직입니다.
@Component
@RequiredArgsConstructor
public class ProductInitializer {
private final ProductRepository productRepository;
@PostConstruct
public void init() {
int batchSize = 1000;
List<Product> products = new ArrayList<>();
for (int i = 0; i <= 1000000; i++) {
products.add(new Product((long) i, i));
if (products.size() == batchSize) {
productRepository.saveAll(products);
products.clear();
}
}
// 남은 데이터 저장
if (!products.isEmpty()) {
productRepository.saveAll(products);
}
}
}아래 코드는 간단하게 직렬, 병렬 스트림의 간단한 성능 비교를 위해 소수인 quantity의 합을 구하는 로직으로 구성하였습니다.
filter를 사용한 이유는 filter 연산에서는 입력 값을 검사하고, 조건에 맞으면 통과시키고 그렇지 않으면 버립니다. 이 경우 각 스레드는 독립적으로 작업을 처리할 수 있습니다. 따라서 filter 연산에서는 스레드 간의 동기화 문제가 발생하지 않습니다.
즉, filter 연산은 병렬 스트림에서 잘 작동하도록 설계되어 있습니다.
@SpringBootTest
public class ProductStreamTest {
@Autowired
private ProductRepository productRepository;
@Test
void 순차_스트림과_병렬_스트림_비교_테스트() {
List<Product> products = productRepository.findAll();
System.out.println("Total products: " + products.size());
long sequentialStartTime = System.currentTimeMillis();
long sequentialSum = products.stream()
.mapToInt(Product::getQuantity)
.filter(this::isPrime)
.sum();
long sequentialEndTime = System.currentTimeMillis();
System.out.println("Sequential stream result: " + sequentialSum);
System.out.println("Sequential stream processing time: " + (sequentialEndTime - sequentialStartTime) + "ms");
long parallelStartTime = System.currentTimeMillis();
long parallelSum = products.parallelStream()
.mapToInt(Product::getQuantity)
.filter(this::isPrime)
.sum();
long parallelEndTime = System.currentTimeMillis();
System.out.println("Parallel stream result: " + parallelSum);
System.out.println("Parallel stream processing time: " + (parallelEndTime - parallelStartTime) + "ms");
}
private boolean isPrime(int number) {
if (number <= 1) {
return false;
}
for (int i = 2; i <= Math.sqrt(number); i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
}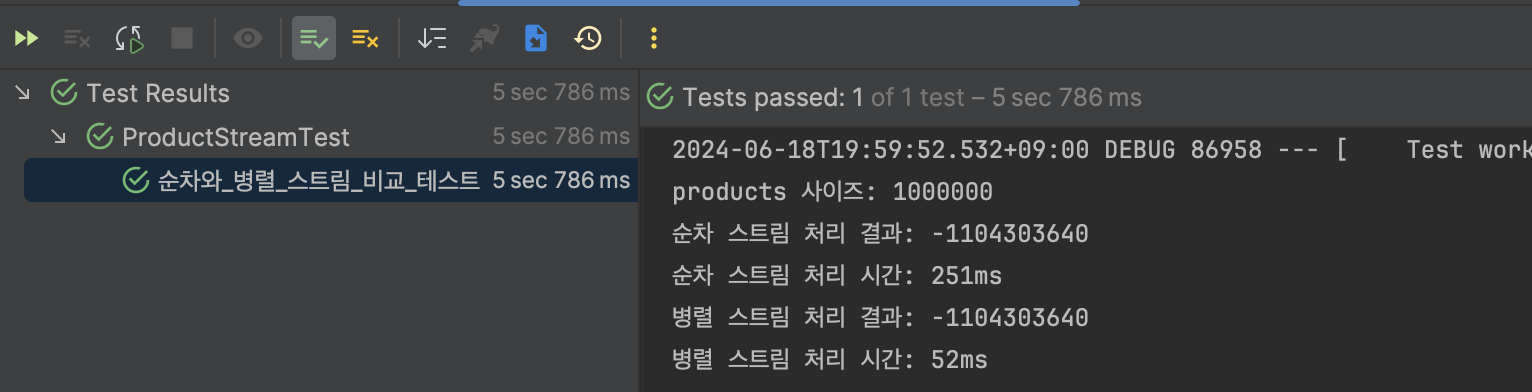
테스트 코드를 실행해보면 위와 같은 결과를 얻을 수 있습니다. 병렬 스트림이 직렬 스트림보다 5배 정도 빠른 것을 확인할 수 있습니다.
그렇다면 병렬 스트림이 직렬 스트림보다 무조건 빠를까요?
코드는 GitHub에 올려놨습니다.
ParallelStream 사용하기 전 주의사항
1. Thread Pool을 공유
parallelStream은 내부적으로 common ForkJoinPool을 사용하여 작업을 병렬화시킵니다.
즉, parallelStream 별로 Thread Pool을 만드는게 아니라는 것입니다.
별도의 설정이 없다면 하나의 Thread Pool을 모든 parallelStream이 공유하게 되고 Thread Pool을 사용하는 다른 Thread에 영향을 줄 수 있으며, 반대로 영향을 받을 수 있습니다.
이 문제는 ForkJoinPool의 개수 설정을 통해 해결할 수 있습니다.
# application.yml
spring:
task:
execution:
pool:
core-size: 8
max-size: 16
스프링 TaskExecutor 빈의 스레드 풀 크기를 설정합니다. 이 설정은 parallelStream에도 적용됩니다.
import java.util.concurrent.ForkJoinPool;
@Configuration
public class ForkJoinPoolConfig {
@Bean
public ForkJoinPool forkJoinPool() {
return new ForkJoinPool(8);
}
}직접 ForkJoinPool 인스턴스를 생성하고 스프링 빈으로 등록합니다. 이렇게 등록된 ForkJoinPool 인스턴스는 parallelStream에서 사용됩니다.
2. Custom Thread Pool 사용 시 Memory Leak 주의
별도의 스레드 풀 생성 개수 설정은 실행 중인 CPU 코어 수를 기준으로 생성하는 것입니다.
물리적인 코어 수를 초과하여 생성할 경우, 생성은 되지만 스레드 관리 오버헤드와 스레드 간의 빈번한 컨텍스트 스위칭(Context-Switching) 등의 문제로 성능 저하가 발생할 수 있습니다.
parallelStream 별로 ForkJoinPool을 인스턴스화하여 사용하면 OOME(OutOfMemoryError)이 발생할 수 있습니다.
개수를 커스텀한 ForkJoinPool 객체는 참조 해제되지 않거나, GC(Garbage Collection)로 수집되지 않을 수 있습니다.
이 문제의 해결방법은 커스텀한 ForkJoinPool을 사용 후 다음 과 같이 스레드 풀을 명시적으로 종료하면 됩니다.
ForkJoinPool customForkJoinPool = new ForkJoinPool(16);
// ...
customForkJoinPool.shutdown();3. Collection 별 성능 차이
parallelStream은 분할되는 작업의 단위가 균등하게 나눠져야 하고, 작업의 비용이 높지 않아야 순차적 방식보다 효율적입니다.
array, arrayList와 같이 전체 사이즈를 알 수 있는 경우에는 분할 처리가 빠르고 비용이 적게 들지만, LinkedList 와 같이 사이즈를 정확히 알 수 없는 데이터 구조는 성능 효과를 보기 어렵습니다.
4. 병렬 처리 시 작업의 독립성
예를 들어 stream()의 중간 연산에서 sorted(), distinct(), filter() 등의 작업을 수행할 경우, 내부적으로 상태에 대한 변수를 공유하게 됩니다.
이러한 경우 순차적으로 실행하는 것보다 효과적이며, 각각 완전히 분리된 task들에 대해서 병렬로 처리하는 경우에 성능상 이점이 있을 수 있습니다.
5. 요소의 수 그리고 요소당 처리 시간
컬렉션에 요소의 수가 적고 요소당 처리 시간이 짧으면 순차적으로 처리하는게 더 빠를 수 있습니다. 병렬 처리는 작업들을 분할(fork)하고 다시 합치는(Join) 비용, 스레드 간의 컨텍스트 스위칭 비용, 스레드 생성과 소멸 등도 포함되기 때문입니다.
정리하자면 parallelStream()은 세부 설정이나 복잡한 로직 없이 기존 stream()과 동일하게 사용할 수 있지만 병렬 처리가 무조건 더 나은 결과를 보장한다고 할 수 없습니다.
따라서 병렬 스트림을 사용하기 위해선 분할이 잘 이루어질 수 있는 데이터 구조 혹은 작업이 독립적이면서 CPU 사용이 높은 작업에 적합합니다.
병렬 스트림이 정말 성능 개선에 도움을 줄지 예상치 못한 장애를 발생시키진 않을찌 충분히 고민하고 사용할 필요가 있습니다.
참고
https://dev-coco.tistory.com/183
https://peterica.tistory.com/689
