
2025년 AWS Summit에 참석해서 여러 세션을 들었는데, 특히 실제 운영 중인 서비스들의 기술적 도전과 해결 과정을 다룬 세션들이 인상적이었다. 이론적인 내용보다는 현실에서 마주한 문제들과 그 해결책에 대한 생생한 경험담들을 정리해보고자 한다.
넥슨: 대규모 클라우드 접근 관리 개선기
넥슨이 직면한 현실적 문제
넥슨의 현황을 들어보니 규모가 상당했다. AWS 계정 300개 이상, 웹 콘솔 접속 가능한 IAM User가 1,500명 이상이라는 수치부터 압도적이었다. 이 정도 규모에서는 권한 관리가 얼마나 복잡할지 짐작이 간다.
기존에는 각 조직의 자율성을 최대한 보장하는 방향으로 운영했다고 한다. 다양한 수단과 방법으로 관리하고 있었지만, 규모가 커질수록 한계가 명확해졌을 것이다.
AWS IAM Identity Center 도입 과정
넥슨이 선택한 해결책은 AWS IAM Identity Center였다. 여러 AWS 계정 및 애플리케이션에 대한 직원 사용자 관리를 중앙화하는 솔루션이다.
핵심 설계 원칙:
- 그룹 : 퍼미션셋 : 계정 = 1:1:1 구조
- 퍼미션셋 이름 자체에 계정 별칭과 권한을 직관적으로 표기
- 백오피스에서 유저/그룹 권한 이력을 중앙 관리
이들이 구축한 별도 제어 콘솔이 흥미로웠다. 각 계정 담당자들에게 직접 권한을 줄 수 없는 상황에서, 레코드 구조를 단순하게 만들어 셀프서비스 형태로 제공한 것이다.
실제 운영에서 발견한 장점들
압도적인 사용자 수 감소: 기존 1,500명 이상의 IAM User에서, 계정 1/3이 IAM Identity Center를 활성화한 시점에 생성된 총 SSO User 수가 100명 이상으로 줄어들었다. 이는 관리 복잡성을 크게 줄인 결과다.
멀티 세션 지원: 5개의 계정을 동시에 접속할 수 있는 기능을 활용해서 운영 효율성을 높였다고 한다.
정책 관리 개선: 인라인 정책을 조직 공통 정책으로 활용하고, 1만 자까지 입력 가능한 유연성을 제공한다. 하드 리밋은 서포트 케이스를 통해 20개까지 확장 가능하다.
현실적인 한계와 해결 과제
솔직한 단점 공유가 인상적이었다:
기능적 한계:
- 계정 관리자급 사용자를 위한 전용 콘솔이 부재
- 그룹에 그룹을 추가하는 기능 불가
- 조직 레벨 기능이다 보니 일반 사용자를 위한 관리 콘솔이 없음
예상치 못한 기술적 이슈:
- SSO 유저 프로필에 한글, 콤마 미지원으로 인한 장애 발생
- 계정 비활성화 기능이 API로 제공되지 않아 SCIM 프로토콜을 통해서만 가능
이런 디테일한 함정들은 실제로 운영해보지 않으면 알기 어려운 부분들이라 매우 유용한 정보였다.
당근페이: Amazon Bedrock 기반 Text-to-SQL 혁신

브로쿼리 - 데이터 분석의 민주화
당근페이에서 개발한 브로쿼리는 AI 기반 데이터 분석 봇으로, 전 직원이 데이터 기반 인사이트를 더 가볍고 빠르게 발견할 수 있도록 지원하는 AI 파트너다.
예시로 보여준 "2024년 1년간 당근페이 가입자 수를 월별 오름차순으로 알려줘" 같은 자연어 질문을 SQL로 변환해서 결과를 제공한다. 심지어 표나 차트로 시각화까지 해준다.
5가지 핵심 설계 원칙
당근페이가 정의한 요구사항들이 체계적이었다:
- 누구나 쉽게 사용: 비개발 직군도 데이터 활용 가능
- 사용자의 진짜 질문 의도 파악: 애매한 질문도 적절히 해석
- 대화 흐름 속 문맥 인식: 이전 대화 맥락을 고려한 응답
- 잘못된 SQL 스스로 점검/개선: 자체 검증 및 수정 기능
- 정확하고 신뢰할 수 있는 답변: 높은 정확도 보장
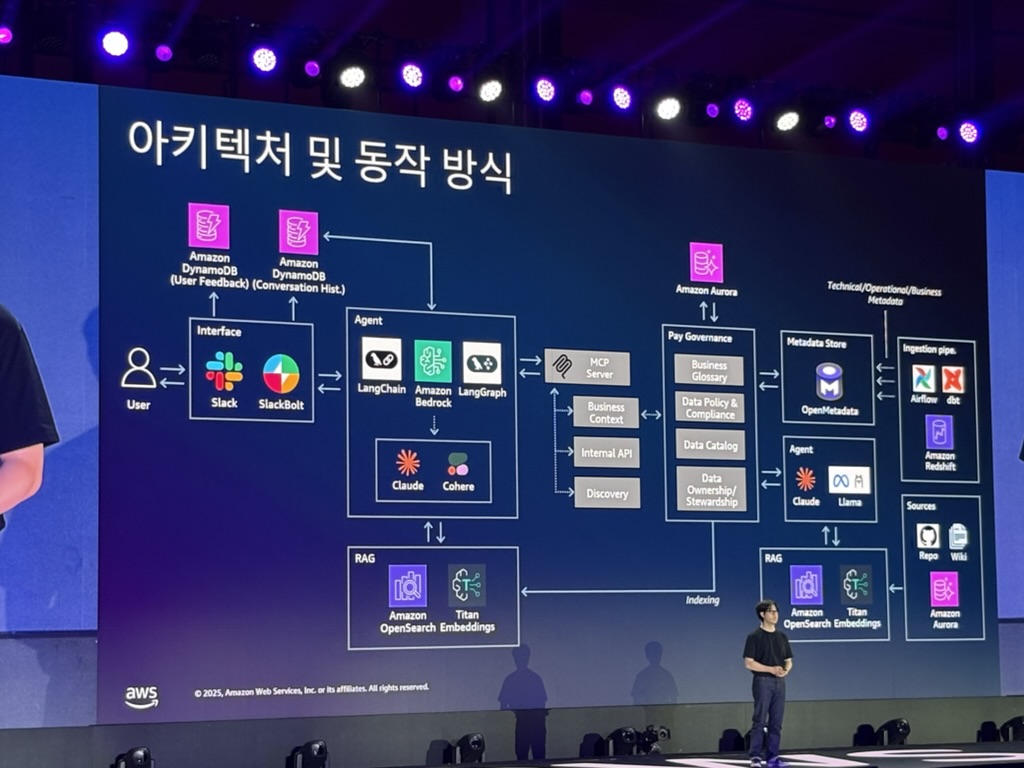
LangGraph 기반 정교한 워크플로우
아키텍처 구성:
- DynamoDB: 이전 대화 저장 및 문맥 파악
- OpenSearch: 정확한 SQL 생성을 위한 하이브리드 검색
- 서브그래프: SQL 생성, 쿼리 점검, 수정 처리를 독립적으로 관리
데이터 분석이 필요하다고 판단되면 전용 워크플로우로 분기되어 처리되는 구조가 인상적이었다.
데이터 품질이 핵심 - 메타데이터 관리
메타데이터가 품질을 결정한다는 점이 가장 중요한 인사이트였다. 기술적 구현보다 데이터 자체의 품질 관리가 더 중요하다는 것이다.
3가지 메타데이터 유형:
- 비즈니스 메타데이터: 업무 맥락과 의미
- 기술 메타데이터: 스키마, 데이터 타입 등
- 운영 메타데이터: 업데이트 주기, 데이터 소스 등
스키마 정보 관리:
- 데이터 연동 자동화 도구를 통한 셀프서비스 형태의 테이블 연동
- dbt property file 활용: 테이블명, 테이블 설명, 컬럼명, 컬럼 설명, 개인식별정보, 비즈니스 민감정보 등을 체계적으로 관리
- ENUM 타입 관리: 소스코드 기반으로 ENUM 값과 설명을 자동으로 증강
신뢰할 수 있는 학습 데이터 구축
샘플 쿼리 관리: 브로쿼리가 참고할 수 있는 "신뢰할 수 있는 답안지"를 입력받을 수 있는 웹 인터페이스를 별도로 구축했다. 이를 통해 AI가 참고할 레퍼런스를 사람이 직접 관리할 수 있게 했다.
히든 키워드: 브로쿼리가 채팅을 통해 직접 학습할 수 있는 기능도 제공한다.
용어 사전: Term, Synonym, Abbreviation 등을 정의해서 다양한 표현을 이해할 수 있게 했다.
비즈니스 컨텍스트: 단순한 데이터 정보를 넘어서 비즈니스 맥락까지 포함한 설명과 관련 테이블, 컬럼, 값 등의 추가 정보를 제공한다.
성능 개선을 위한 지속적 노력
- Retrieval 최적화: 검색 성능 개선
- Supervised Fine Tuning: 모델 자체 성능 향상
- Business Context 강화: 비즈니스 맥락 이해도 향상
- Evaluation 체계: 지속적인 성능 측정 및 개선
보안상 자체 구축 모델을 사용하고 있다는 점도 흥미로웠다. 내부 보안 규정에 따라 자체 모델을 구축하고 서빙하는 환경을 만들었다고 한다.
트웰브랩스: 초거대 영상 이해 모델의 AI 인프라 고도화
영상 이해 AI의 도전과제
트웰브랩스는 영상 이해 AI 전문 스타트업으로, 인간이 보고 듣고 이해하는 것처럼 영상 데이터를 이해하여 검색과 요약 등을 제공하는 AI를 개발한다. 마렝고, 페가수스 같은 모델명도 센스 있게 지었다.
분산 학습이 필요한 이유:
1. 모델 크기의 폭발적 증가: 초거대 모델 학습 필요
2. 방대한 데이터량: 영상 데이터 특성상 큰 데이터셋 필요
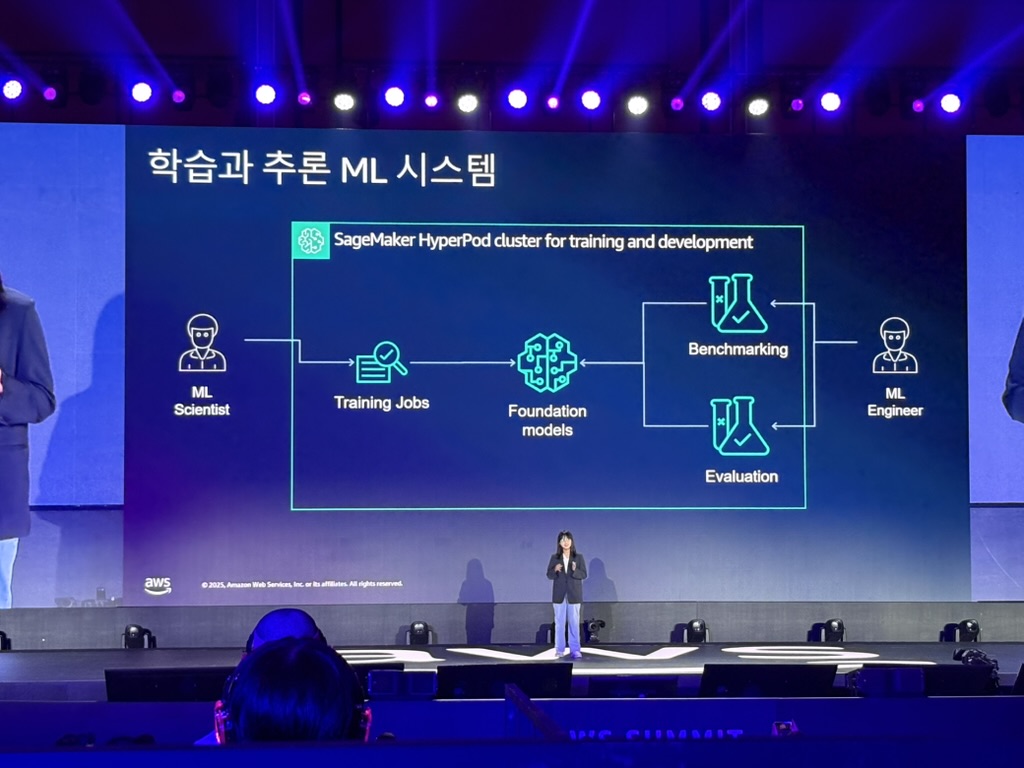
Amazon SageMaker HyperPod 도입
기존 시스템의 한계: 복잡한 2개의 시스템을 별도로 운영하던 상황에서 관리 부담이 컸다.
Amazon SageMaker HyperPod 특징:
- 학습용 워크로드를 위해 최적화된 고성능 클러스터
- 최신 GPU 지원: H100, H200 등
- 2가지 오케스트레이션: Slurm, Kubernetes 선택 가능
- FSx Lustre: 고속 스토리지 제공
- 400GB/s 네트워크 속도: 초고속 데이터 전송
학습뿐만 아니라 벤치마킹에도 많은 GPU가 필요하다는 점이 현실적이었다. 연구 개발 과정에서 다양한 실험을 해야 하기 때문이다.
운영 및 추론 환경 요구사항
모델 학습용 인프라:
- 고성능 스토리지: 대용량 영상 데이터 처리
- 고속 네트워크: 분산 학습 환경에서 빠른 데이터 동기화
- 강력한 GPU: 초거대 모델 학습 지원
운영적 요구사항:
1. 시스템 안정성: 장시간 학습 작업 지원
2. 사용자 친화적 인터페이스: 연구진이 쉽게 사용할 수 있는 환경
3. 데이터 보안: 민감한 모델과 데이터 보호
추론용 인프라:
1. 배포 시스템: 학습된 모델의 효율적 배포
2. 안정성: 서비스 중단 없는 추론 환경
3. 서빙용 GPU: 실시간 추론 성능 보장
도입 효과와 개선 사항
HyperPod 도입 효과:
- 시스템 통합: 복잡한 2개 시스템을 단일 시스템으로 통합
- 관리 비용 최소화: 인프라 관리 부담 대폭 감소
- 유연한 GPU 운용: 학습/추론 필요에 따라 가변적 GPU 활용
- 기존 인프라 연동: EKS와 연동하여 효율적인 모델 서빙
- 기술 스택 갭 최소화: 연구와 개발 간 기술 스택 일관성 확보
대규모 벡터 데이터 처리 최적화
챌린지: 오디오, 비디오, 이미지, 텍스트 등 다양한 형태의 데이터를 벡터 데이터로 변환하고 처리해야 함.
해결책:
- S3 for Vector Storage: 벡터 데이터를 S3에 저장
- S3 CRT Transfer: 레이턴시 최적화를 위한 전송 기능 활용
이 부분에서 S3를 단순 파일 스토리지가 아닌 벡터 데이터베이스의 백엔드로 활용하는 접근이 흥미로웠다.
비용 효율적인 운영 전략
오토스케일링: Karpenter를 활용한 간단하고 효율적인 오토스케일링 구현. Kubernetes 생태계의 장점을 활용해서 비용 최적화와 성능 확보를 동시에 달성했다.
Karpenter는 단순하게 설정을 변경할 수 있어서 다양한 워크로드 패턴에 유연하게 대응할 수 있다는 점을 강조했다.
전체적인 소감과 인사이트
공통적으로 발견한 패턴들
1. 완벽한 솔루션은 없다: 모든 발표자들이 자신들의 솔루션의 한계를 솔직하게 인정했다. 이는 기술 선택에 있어서 트레이드오프를 명확히 이해하고 있다는 것을 보여준다.
2. 메타데이터와 데이터 품질의 중요성: 특히 당근페이 사례에서 명확히 드러났듯이, 기술적 구현보다 데이터 자체의 품질과 메타데이터 관리가 더 중요한 경우가 많다.
3. 중앙화 vs 자율성의 균형: 넥슨의 경우 완전한 중앙화보다는 적절한 자율성을 보장하면서도 통제 가능한 구조를 만드는 것이 중요했다.
4. 비용 최적화의 현실성: 모든 회사가 비용 효율성을 고려하면서도 성능을 확보하는 방법을 고민하고 있었다.
아쉬웠던 점들
구체적인 구현 디테일 부족: 시간 제약으로 인해 실제 코드나 설정 예시를 더 자세히 볼 수 없었던 것이 아쉬웠다. 특히 당근페이의 LangGraph 구현 부분이나 트웰브랩스의 Karpenter 설정 등은 더 구체적인 내용을 알고 싶었다.
성능 수치와 비용 정보: 도입 전후의 구체적인 성능 개선 수치나 비용 절감 효과를 더 자세히 들을 수 있었다면 좋았을 것이다.
개발자로서 얻은 교훈
1. 문제 정의의 중요성: 기술을 도입하기 전에 해결하고자 하는 문제를 명확히 정의하는 것이 가장 중요하다.
2. 점진적 개선의 가치: 모든 사례에서 한 번에 완벽한 시스템을 구축하기보다는 점진적으로 개선해나가는 접근을 택했다.
3. 운영 경험의 소중함: 실제로 운영해보면서 겪는 예상치 못한 문제들과 그 해결 과정에서 나오는 인사이트들이 가장 가치 있었다.
4. 기술 선택의 맥락: 동일한 기술이라도 회사의 상황, 팀의 역량, 비즈니스 요구사항에 따라 적용 방식이 완전히 달라질 수 있다는 점을 확인했다.
이번 AWS Summit에서 들은 세션들은 단순한 기술 소개를 넘어서 실제 비즈니스 문제를 해결하는 과정에서의 생생한 경험담들이었다. 이런 실무 중심의 내용들은 책이나 문서로는 얻기 어려운 소중한 인사이트들을 제공해준다. 앞으로도 이런 실무 경험 공유의 장이 더 많아지길 기대한다.
그 외
간단한 코테 챌린지 실시간 9등 기록 ㅎ,.ㅎ

세션을 동시에 3개를 진행하고, 무선 헤드폰으로 듣는 모습이었다. 멋있었다.
