헷갈리는 용어/개념 정리용
-
mAP
mAP(mean Average Precision)
혹은 인공지능 강의 22강 -
feature map, activation map
https://jisuhan.tistory.com/34 -
weight decay = L2 regularization (Frobenius norm)
https://sanghyu.tistory.com/88 -
feature extraction/feature selection/latent space
https://dev-hani.tistory.com/entry/Latent-space-%EA%B0%84%EB%8B%A8-%EC%A0%95%EB%A6%AC
Variance vs Bias
high variance = overfitting = validation error가 train error보다 많이 큼
high bias = underfitting = 높은 train error
low bias = 낮은 train error
low variance = validation error가 train error와 비슷
bayes optimal error : 이론적인, 이상적인 최저의 불가피한 에러
avoidable bias : bayes optimal error와 train error의 차이. 즉, 이 값이 클 수록 아직 모델이 충분히 훈련이 안된 것
variance : train error과 validation error의 차이

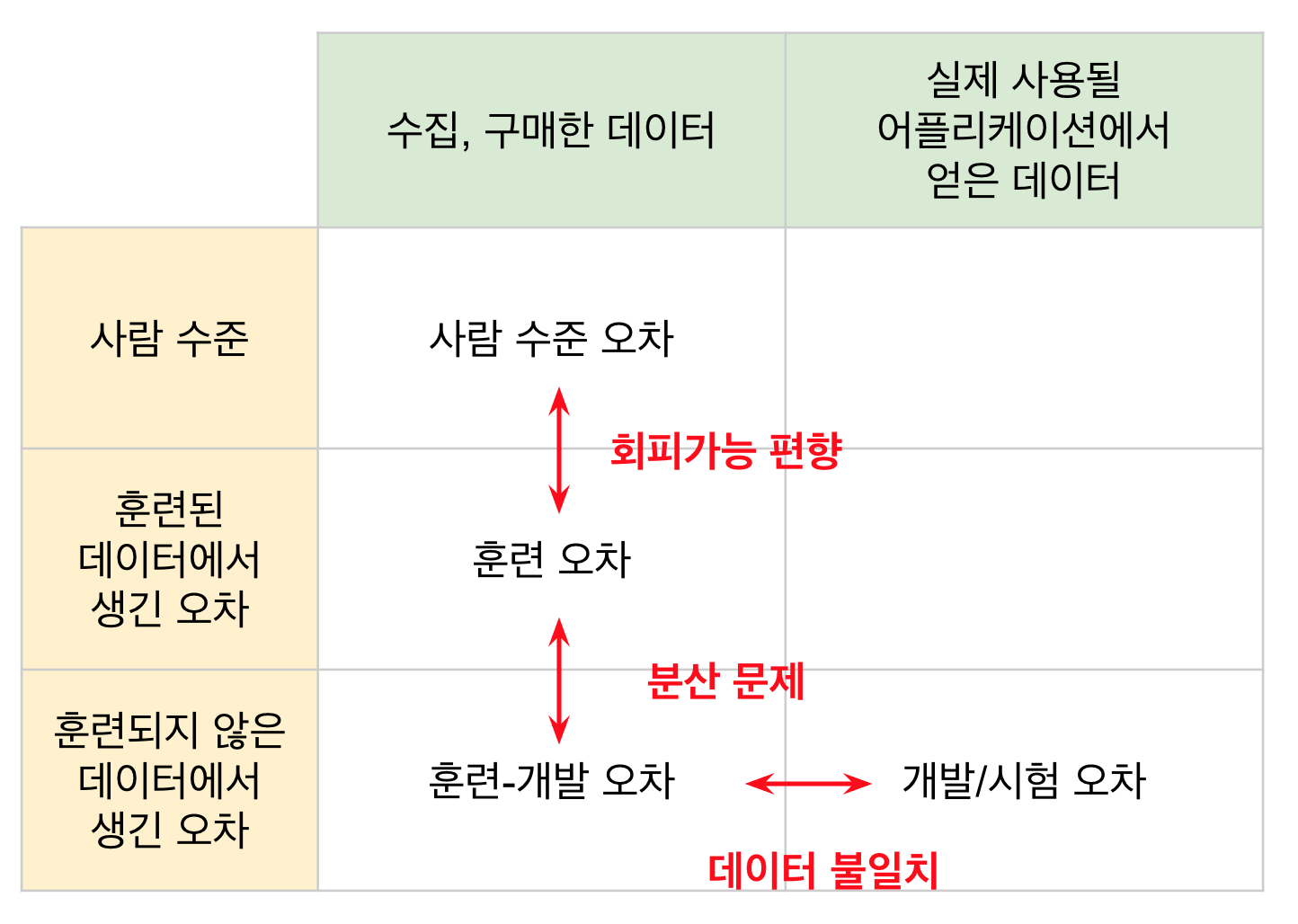
training-dev set까지 도입하면
(1) human level(=bayes optimal error)
(2) training set error
(3) training-dev set error
(4) dev error
(5) test error
avoidable bias : (1), (2) 차이
variance : (2), (3) 차이
data mismatch : (3), (4) 차이
degree of overfitting to dev set : (4), (5) 차이
Trnasfer learning에서
pre-training : 기존/다른 데이터셋으로 사전학습하는 것
fine-tuning : pre-trained 모델에서 마지막층을 원하는 목적에 맞게 바꿔서 목적 데이터셋으로 마지막층 세부 조율하는 것
1x1 convolution의 역할
- w, h를 유지하고 채널 수를 바꾸는 역할

- fully connected layer를 대체하는 역할
VAE, AE 차이
https://gaussian37.github.io/dl-concept-vae/
Stable diffusion model, latent diffusion 설명
https://pitas.tistory.com/9
https://process-mining.tistory.com/182
bias = False하는 이유
batch normalization을 사용하는 경우 beta가 bias의 역할을 대신하기 때문에 convolution layer에 bias를 설정하지 않아도 된다.
https://discuss.pytorch.org/t/any-purpose-to-set-bias-false-in-densenet-torchvision/22067
conv-batch norm-activation-dropout 순서
배치 정규화의 목적이 네트워크 연산 결과가 원하는 방향의 분포대로 나오는 것이기 때문에 핵심 연산인 Convolution 연산 뒤에 바로 적용하여 정규화 하는 것이 핵심. 즉, Activation function이 적용되어 분포가 달라지기 전에 적용하는 것이 올바르다.
반면 dropout의 경우 저자에 따르면, activation function을 적용한 뒤에 적용하는 것으로 제안되었다. 그런데 어차피 batch norm이 dropout과 비슷한 regularization을 제공하기 때문에 batch norm을 사용할 때는 dropout을 안 사용해도 된다.
pooling의 경우 완전히 새로운 layer이기 때문에 dropout까지 다 끝나고나서 사용하는 듯.
slef-supervised learning이란
transformer 설명
zero-shot 뜻
zero-shot 은 쉽게 말하면 “모델이 학습 과정에서 배우지 않은 작업을 수행하는 것”을 의미한다.
Transformer을 이용한 Autoregressive Model vs Autoencoding Model vs Sequence-to-sequence Model
(ChatGPT발) Transformer에서 Query, Key, Value의 의미
Transformer 모델에서 "query", "key", "value"는 어텐션 메커니즘에서 사용되는 세 가지 요소입니다. 이러한 요소는 입력 시퀀스를 다른 시퀀스로 매핑하고, 각 시퀀스의 관계를 찾는 데 사용됩니다.
-
Query: 어텐션을 수행할 때 찾고자 하는 정보를 나타내는 벡터입니다. Query는 주어진 입력에 대한 정보를 요청하는 역할을 합니다.
-
Key: 입력 시퀀스의 각 위치에 대한 정보를 나타내는 벡터입니다. Key는 입력 시퀀스의 각 요소와의 관계를 나타냅니다.
-
Value: 입력 시퀀스의 각 위치에 대한 값을 나타내는 벡터입니다. Value는 입력 시퀀스의 각 요소에 대한 정보를 담고 있습니다.
Transformer 모델에서 어텐션은 Query와 Key의 관계를 사용하여 Value를 가중합하여 출력을 생성합니다. 이를 통해 모델은 입력 시퀀스의 각 위치에 대한 중요도를 결정하고, 이를 기반으로 출력을 생성합니다.
