이번에 리뷰할 논문은 YOLO 논문이다. 기존의 2-stage object detection과 달리 YOLO는 1-stage object detection으로, 물체의 위치와 종류를 동시에 찾는다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
Summary
object detection에서 기존의 논문들은 classifier을 재조정하여 detection을 하도록 만들지만, 여기서는 detection을 spatially separated bounding boxes, associated class probabilities와 관련된 regression problem으로 본다. 그리고 하나의 end-to-end CNN이 full image로부터 한 번만에 bounding boxes' coordinates와 class probabilities를 예측하고, detection performance를 directly optimize한다.
이렇게 한 단계로 만들어진 모델은 여러 장점이 있다. 첫째로 속도가 매우 빠르다는 것이다. detection을 regression으로 여기기 때문에 복잡한 pipeline이 필요없다. 또 YOLO는 다른 real-time system에 비해 mAP도 2배 이상이다.
두 번째 장점으로, YOLO는 prediction을 할 때 사진을 globally 판단한다. sliding window나 region proposal-based 기술과 달리 전체 이미지를 한 눈에 보기 때문에 contextual information까지 표현한다.
셋째로 YOLO는 object의 generalizable representations를 학습한다. train은 natural images으로 하고 test는 art-work에 대해 했는데 DPM이나 R-CNN 같은 최고의 detection 방법들보다 성능이 크게 좋았다. highly generalizable하기 때문에 new domains나 unexpected inputs에 적용하기 좋다.
하지만 정확도에서는 SOTA(state of the art) 시스템들에 비해 뒤떨어지며, 빠르게 사물을 식별할 수는 있어도 (특히 작은 물체에 대해) localization 정확도가 떨어진다.
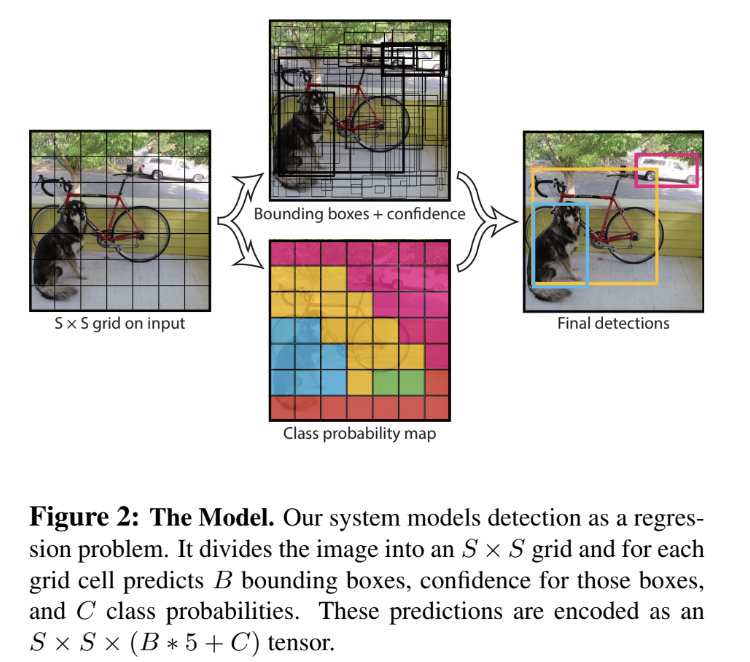
YOLO는 input image를 SxS 격자(grid)로 구분한다. 사물의 중심이 grid cell안에 들어가면 그 grid cell은 그 사물을 detect한 것이다. 각 grid cell은 B개의 bounding box를 예측하며, 그 box들에 대해 각각 confidence score을 매긴다. confident score은 '그 box가 object를 가지고 있다', '예측한 box가 얼마나 accurate한가'에 대해 얼마나 confident한지를 나타내는 지표다. confidence score은 다음 사진과 같이 정의한다.
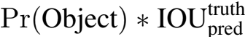
cell 안에 object가 없으면 점수는 0점이 되고, 그게 아니라면 점수는 predicted box와 ground truth 간의 intersection over union (IOU)이 된다.
각 bounding box는 5개의 예측을 한다(x, y, w, h, confidence). (x, y) 좌표는 grid cell bound에 상대적인 box의 center 좌표다. width, height는 전체 image 크기에 상대적인 값으로 예측된다.
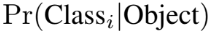
또한 각 grid cell은 위의 사진과 같은 C conditional class probabilities를 예측한다. 이는 object를 가진 grid cell에 대해 (box 개수 B에 무관하게) one set of class probabilities를 예측하는 것이다.

test시에는 위의 두 식, conditional class probabilities와 individual box confidence predictions를 곱해 각 box에 대해 class-specific confidence scores를 구한다. 이 점수는 box 안에 나타난 class의 probability와 예측된 box가 얼마나 object에 잘 맞는지를 모두 나타낸 것이다.
YOLO를 PASCAL VOC 데이터셋으로 평가할 때 S = 7, B = 2, C = 20(PASCAL VOC가 20 labelled class를 가져서)로 두었다.

YOLO는 CNN으로 이루어지며, 24개의 convolutional layer가 feature를 extract하고 마지막 2개의 fully-connected layer가 output probabilities와 coordinates를 예측한다. YOLO는 GoogLeNet에서 영감을 받았는데, GoogLeNet의 inception modules을 사용하는 대신 Lin et al의 NiN(Network in Network) 구조와 비슷하게 단순히 1x1 reduction layer에 3x3 layers를 이어 사용한다.
또 더 적은 conv layer(24층 대신 9층)으로 YOLO의 빠른 버전인 Fast YOLO도 만들었다.
training은 ImageNet으로 pretrain을 한다. YOLO의 첫 20개 conv layer에 average-pooling layer와 fully connected layer를 붙여 pretrain하는데, conv layer 24개를 전부 사용하지 않는 이유는 Ren et al에 따르면 pretrained network에 conv layer와 FC layer을 모두 추가하는 게 성능 향상에 좋기 때문이다. 그래서 20개 층만 pretrain한 후 randomly initialized weights를 가진 4개의 conv layer와 2개의 FC layer을 붙여 detection 용도로 변경한다. 이때 pretrain은 input 크기를 224x224로 하는데 detection은 종종 fine-grained visual information을 요구하기 때문에 448x448로 input 크기를 증가시켰다.
FC layer에서 예측하는 x, y, w, h는 모두 0~1사이의 값이며 w, h는 input image에 상대적으로 normalize했고 box 중심 좌표인 x, y는 특정 gride cell에서의 offset이다.
또 논문은 optimize가 쉬운 sum-squared error를 사용하는데 문제는 1. localization error와 classification error를 동등한 수준으로 취급해 mAP를 높이려는 목표와 완벽히 부합하지 않고 2. 아무 object도 포함하지 않는 수많은 grid cell에서 confidence score가 0으로 되기 때문에 실제로 object가 존재하는 cell도 마찬가지로 그렇게 될 수 있다는 것이다.
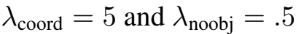
이를 해결하고자 bounding box coordinate predictions loss를 증가시키고 object가 존재하지 않는 box의 confidence predictions loss를 감소시킨다.
또 sum-squared error는 큰 bounding box와 작은 box에 대해서도 같은 가중치를 주는데, 이것도 문제가 될 수 있다. 큰 box와 달리 작은 box는 작은 deviation이 발생해도 결과에 영향이 크기 때문이다. 이를 해결하기 위해 box의 width와 height을 곧장 예측하지 않고 square root 값을 예측한다.
YOLO는 gride cell당 여러 box를 예측하는데 training time에는 각 object에 대해 하나의 bounding box predictor만을 가지길 원한다. 그래서 ground truth에 대해 가장 높은 IoU를 가지는 box를 선택하며(responsible) 이는 bounding box predictors 간의 specialization을 유발한다. 각 predictor가 특정 size, aspect ratio(종횡비), classes of object 등에 특화되어 overall recall을 향상시킨다.
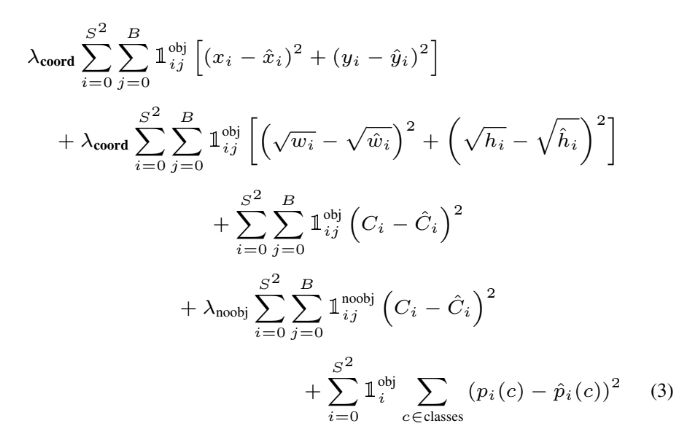
결과적으로 multi-part loss function은 위와 같다. 1^obj_i 기호는 i번째 cell에 object가 존재하는가를 나타내며 1^obj_ij 기호는 i번 cell의 j번 bounding box가 그 predict에 대해 responsible한가를 나타낸다.

위에서 본 조건부확률식을 고려하여 식 (3)의 마지막 항, 즉 classification error은 object이 해당 grid cell에 존재할 때만 계산된다. 또 첫 두 항을 보면 predictor(box)가 ground truth box에 대해 responsible할 때만, 즉 해당 grid cell에서 가장 높은 IoU를 가진 predictor에 대해서만 bounding box coordinate error를 계산한다.
PASCAL VOC 데이터셋에 대해 YOLO는 이미지 당 98개의 bounding box를 예측했다. classifier-based model들과 달리 single network evaluation만 필요로 하므로 test time이 굉장히 빨랐다. grid design은 bounding box prediction에서 spatial diversity를 enforce했다. 하지만 종종 크기가 크거나 여러 cell의 경계에 걸친 사물은 여러 cell에 의해 (즉, 중복되어) localize된다. 이런 multiple detections를 고치기 위해 (R-CNN이나 DPM처럼 필수는 아니지만) Non-maximal suppression를 사용할 수 있으며 mAP에서 2~3% 향상을 보인다.
반면 YOLO에는 몇 가지 한계도 존재한다. 첫째는 bounding box predictions에서의 strong spatial constraints이다. 이는 각 grid cell이 오직 2개의 bounding box와 하나의 class밖에 가지지 못하는 것에서 기인한다. 따라서 YOLO는 인식할 수 있는 서로 붙어있는 사물(nearby objects)의 수가 제한되어 있다. 특히 크기가 작은 사물이 그룹으로 나타날 때 어려움을 겪는다.
둘째로 모델이 data로부터 bounding box prediction을 학습하기 때문에 기존에 없던 종횡비(aspect ratio)나 환경(configuration)을 잘 일반화하지 못한다. 또 architecture가 input으로부터 multiple downsampling layers를 가지기 때문에 bounding box predictoin에서 상대적으로 coarse features를 사용한다.
셋째로 loss function이 small bounding boxes와 large bounding
boxes의 error를 똑같이 처리한다. large box에서 small error는 별 것 아니지만(benign) small box에서는 IoU에 큰 영향을 미친다. 그로 인해 incorrect localization이 발생한다.
이때 논문에서는 아래 사진과 같은 Hoiem et al의 방법을 사용하여 평가를 하며, 각 prediction은 correct하거나 error의 종류에 따라 구분된다. 앞서 설명한 localization error이 이걸 의미하는 듯하다.

또 다른 모델과 비교 연구를 하면서 흥미로운 점이 몇 가지 있었다. Fast R-CNN과 YOLO를 결합했을 때, 정확히는 Fast R-CNN에서 background detection을 제거하기 위해 YOLO를 사용했을 때 성능에 상당한 boost가 있었다. 이는 YOLO가 Fast R-CNN보다 훨 적은 background mistake를 만들며 YOLO가 Fast R-CNN과 다른 종류의 mistake를 만들기 때문에 이러한 결합이 효과적인 것이다. 물론 두 모델을 따로 돌린 후 결과를 결합하는 거라 속도의 이점은 없다.
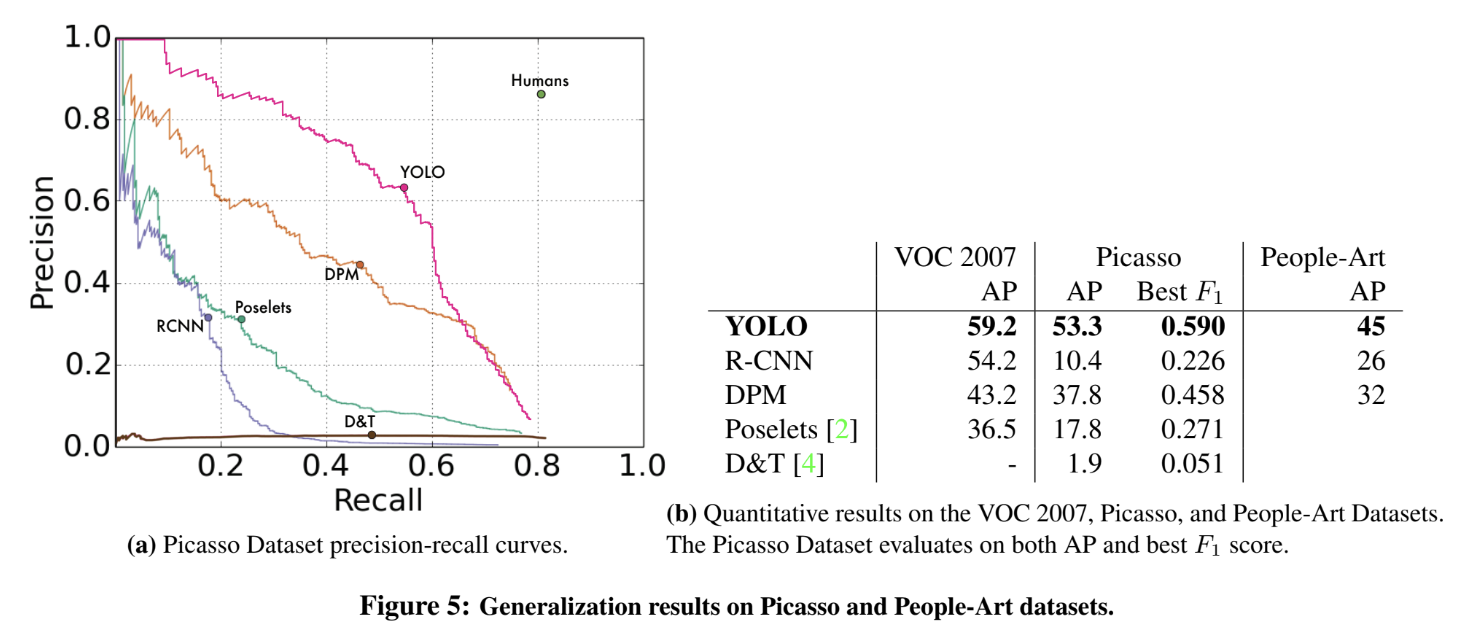
그리고 성능의 일반성을 평가하기 위해 예술 작품을 대상으로도 detection을 실험한다. Picasso Dataset과 People-Art Dataset을 사용해서 그림 속의 사람을 찾는다. R-CNN은 natural image에 tune되어있고 오직 작은 영역만을 보며 좋은 proposal이 필요하기 때문에 예술 작품을 대상으로는 성능(AP)이 떨어진다. DPM은 AP를 유지하는데, object shape과 layout에 강한 spatial 모델이기 때문이다. YOLO도 AP가 다른 모델보다 덜 감소하며, object size와 shape, object간 relationship, object가 흔히 나타나는 위치를 학습하기 때문이다. 이런 결과는 artwork가 natural image와 pixel단위에서 매우 다르지만, object의 size와 shape이란 방면에선 비슷하기 때문에 나타난다.

Strengths
- limitation을 뚜렷히 파악하고 명시해서 좋았다. YOLO의 장점과 한계를 명확히 구분하고, 다른 model과의 비교를 통해 YOLO의 경쟁력을 설명해서 좋았다.
- 경쟁력 있게 정확하면서, 동시에 real-time으로 사용할 수 있는 방법이며 1-stage object detection이 가능함을 보여 이후 연구 가능성을 넓혔다.
- 모델의 일반성을 입증하기 위해 artwork로 detection을 시험한 점이 독특하다.
Weaknesses
- loss functoin에서 lambda parameter를 각각 5, 0.5로 설정했는데 이 parameter들이 성능에 영향이 클 것 같다. 이에 관해서도 실험했다면 더 좋았을 것 같다.
모델 자체는 흔한 CNN이지만, 마지막 layer에서 (x, y, w, h, confidence)를 regression하는 아이디어가 좋았다. loss function을 잘 정의한 덕분에 좋은 결과를 얻었다고 본다.
