
오늘 리뷰할 논문은 StarGAN이다. 참고로 한국에서 나온 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] StarGAN
- [논문 리뷰] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Summary
image-to-image translation task는 특정 domain의 image를 다른 domain의 image로 변환하는 과제다. 논문은 'attribute'를 hair color, gender, age처럼 이미지에 내재한 의미있는 feature로 정의하고 'attribute value'를 attribute의 특정 값, 'domain'을 같은 attribute value를 공유하는 이미지의 집합으로 정의한다.
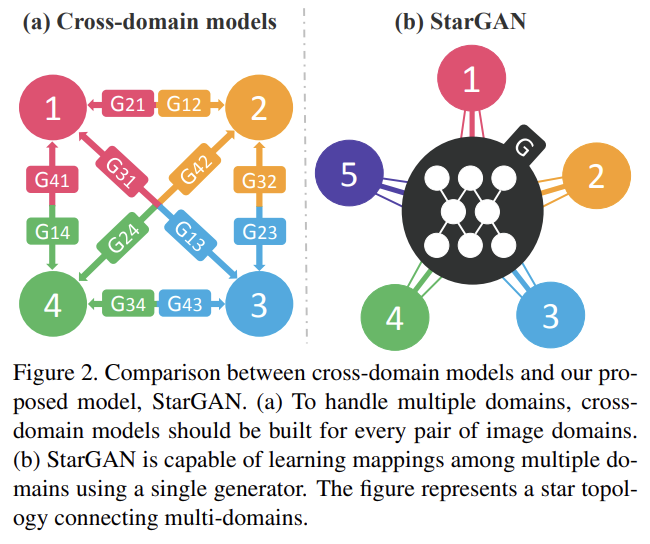
기존의 방법들은 모든 image domain 쌍마다 모델을 따로 학습시켜야했기 때문에 scalability와 robustness에 한계가 있었다. 그래서 논문은 single model에 여러 dataset을 학습시켜 multiple domain에서 image-to-image translations이 가능한 StarGAN을 제안한다.
Fig 2처럼 StarGAN은 하나의 generator을 사용한다. fixed translation (e.g., black-to-blond hair)를 배우는 대신, generator은 image와 domain information을 모두 input으로 받아서 image를 상응하는 domain으로 유연하게 변환하도록 학습한다. domain information은 label (e.g., binary or one-hot vector)으로 표현된다. training 중엔 target domain label을 랜덤하게 생성해 모델이 input을 target domain으로 변환하도록 학습시킨다. test에는 domain label을 조작해서 원하는 domain으로 변환하게 할 수 있다.
또 논문은 domain label에 mask vector을 첨부해 서로 다른 domain dataset의 joint training를 가능하게 하는 간단하지만 효과적인 방법을 제안한다. 이 방법은 모델이 unknown label은 무시하고 특정 dataset에 의해 제공된 label에는 집중하게 한다. 이런 방식으로 StarGAN은 Fig 1의 가장 오른쪽 열처럼 'synthesizing facial expressions of CelebA images using features learned from RaFD' 과제에서 좋은 성능을 보인다. 저자들이 아는 한 이 논문은 여러 dataset 사이에서 multi-domain image translation를 성공한 최초의 사례다.
논문의 기여는 다음과 같다.
- single generator, discriminator을 사용하는 StarGAN을 제안해 multiple domain 사이 mapping을 찾았다.
- available domain label 통제를 가능하게 하는 mask vector method를 활용해 어떻게 multiple dataset 간 multi-domain image translation을 학습했는지 입증한다.
- facial attribute transfer과 facial expression synthesis tasks에 StarGAN이 baseline보다 우수함을 양적, 질적 평가로 보인다.
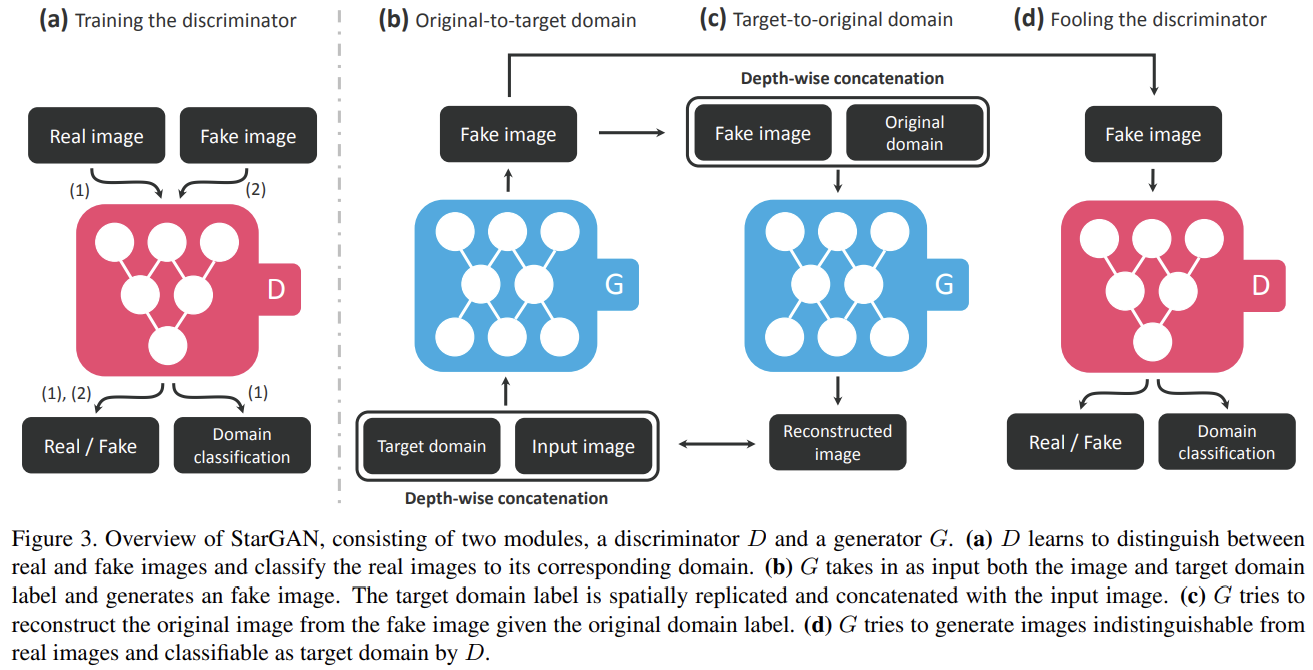
논문은 우선 single dataset에서 StarGAN을 보이고 나서 서로 다른 label sets을 가진 multiple datasets를 어떻게 포함시키는지 보인다.
논문의 목표는 input image x를 넣어 target domain label c에 condition된 output image y를 만드는 mapping을 가지도록 G(x, c) → y를 학습하는 것이다. target domain label c는 랜덤하게 생성시켜 G가 input image를 유연하게 변환할 수 있도록 한다. 그리고 single discriminator가 multiple domains를 조절할 수 있도록 auxiliary classifier를 도입한다. 이는 discriminator가 sources와 domain labels 모두에 대한 probability distributions 를 생성한다는 의미다.
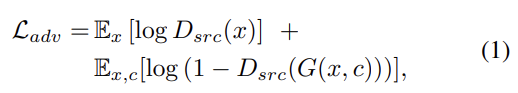
adversarial loss는 식 (1)과 같다. 는 D에 의해 주어진 source의 probability distribution이다. G는 objective을 최소화하려하고 D는 최대화하려한다.
목표는 x, c를 넣어서 domain c로 분류되는 y를 생성하는 것이다. 이를 위해 D의 꼭대기에 auxiliary classifier을 추가해 D와 G를 최적화할 때 domain classification loss를 부과한다. 다시 말해 objective을 두 개 항 D를 최적화하기 위한 domain classification loss of real images와 G를 최적화하기 위한 domain classification loss of fake images로 분해한다.
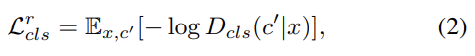
전자는 식 (2)와 같다. 는 D가 계산한 probability distribution over domain labels이다. 이 objective을 최소화함으로써 D는 real image x를 상응하는 original domain c'로 분류하도록 학습한다. input image와 domain label (x, c') 쌍은 training data로 주어진다고 가정한다.
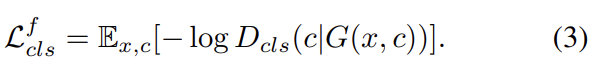
후자는 식 (3)과 같다. G는 생성한 이미지가 target domain c로 분류되도록 objective을 최소화한다.
adversarial loss와 classification loss를 최소화하는 것으로 G는 realistic하고 올바른 target domain으로 분류되는 이미지를 생성하도록 학습한다. 그러나 translated images가 오직 사진의 domain-related 부분만 바꾸면서 content를 보존할 것이란 보장은 못한다. 이 문제를 완화하기 위해 generator에 cycle consistency loss를 추가한다.
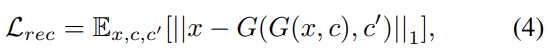
G가 translated image G(x,c)와 original domain label c'를 받아 original image x를 reconstruct하도록 하는 것이다. norm은 L1 norm을 사용했다.
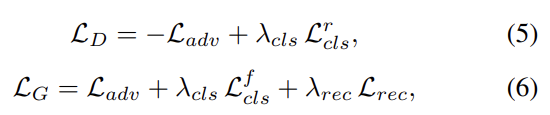
G와 D의 전체 objective는 위와 같다. λ는 각 loss의 상대적 중요도를 조절하기 위한 hyper-parameter다. 실험에는 모두 를 사용했다.
StarGAN의 중요한 장점은 서로 다른 종류의 label을 지닌 여러 dataset을 통합할 수 있다는 것이다. 문제는 label information이 각 dataset에 일부만 알려져 있다는 것이다. 이는 식 (4)에서 reconstruct를 할 때 label vector c'에 대한 완전한 정보가 필요하기 때문에 문제가 된다.
문제를 완화하기 위해 StarGAN이 unspecified label은 무시하고 특정 dataset에 의해 제공된 explicitly known label에만 집중하도록 mask vector m을 도입한다. m을 표현하기 위해 n-dimensional one-hot vector를 사용하고 n은 dataset의 개수다. 그리고 i번째 dataset의 label 들과 m을 concatenate한 label의 unified version을 정의한다.
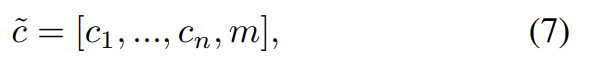
label 의 vector는 binary attributes에는 binary vector로, categorical attributes에는 one-hot vector로 표현될 수 있다. 나머지 n−1 unknown labels에는 단순히 0을 할당한다. 실험에는 CelebA와 RaFD datasets을 사용해 n=2를 사용한다.
StarGAN을 여러 dataset에 학습시킬 때는 generator의 input으로 domain label 를 사용한다. 그럼으로써 generator은 zero value인 unspecified labels을 무시하고 explicitly given label에 집중한다. generator 구조는 input label 의 dimension만 제외하면 single dataset으로 학습할 때와 동일하다. 그리고 discriminator은 모든 dataset의 label에 대해 probability distribution을 생성하도록 auxiliary classifier를 확장한다. 그리고 모델을 multi-task learning setting으로 훈련시켜 discriminator가 known label에 대한 classification error만 최소화하도록 한다. 즉 CelebA 내의 image를 학습할 때는 discriminator가 CelebA attributes와 관련된 label에 대한 classification error만 최소화하고 RaFD와 관련된 facial expression은 하지 않는다는 것이다. CelebA와 RaFD를 번갈아 학습하며 discriminator은 모든 dataset의 discriminative features를 학습하고 generator은 모든 dataset의 label을 조절하도록 학습한다.
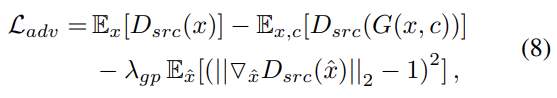
구현에서는 training을 안정화하고 higher quality image를 생성하기 위해 식 (1)을 식 (8)처럼 gradient penalty를 지닌 Wasserstein GAN objective로 대체한다. 는 real, generated images 쌍 사이 straight line에서 uniformly sample된 것이고 을 사용했다.
CycleGAN에서 adapt하여 StarGAN은 downsampling을 위한 2 convolutional layers (stride 2), 6 residual blocks, upsampling을 위한 2 transposed convolutional layers (stride 2)으로 구성된 generator network를 가진다. generator에는 instance normalization을 사용하고 discriminator은 normalization을 사용하지 않는다. discrminator network로는 PatchGANs를 leverage한다.
다음은 논문의 실험들이다. 논문은 최신 facial attribute transfer 모델들과 StarGAN의 성능을 비교한다. 그리고 facial expression synthesis에 classification experiment를 수행한다. 마지막으로 StarGAN이 multiple datasets에서 image-to-image translation을 배울 수 있다는 것을 경험적 결과로 보인다.
baseline으로는 DIAT, CycleGAN, IcGAN을 사용했다. 데이터셋은 CelebFaces Attributes (CelebA) dataset, Radboud Faces Database (RaFD)를 사용했다. 각 모델과 데이터셋에 대한 설명은 생략한다.

첫째로 CelebA에서 single/multi-attribute transfer tasks에 StarGAN과 baseline을 비교한다. DIAT, CycleGAN의 경우 모든 가능한 attribute value pair을 고려해 여러번 학습시켰고 multiple attributes를 합성하기 위해선 multi-step translations를 수행했다.
Fig 4에서 StarGAN이 cross-domain models보다 higher visual quality를 보임을 알 수 있다. 그 원인은 multi-task learning framework을 통한 regularization effect으로 생각할 수 있는데, 즉 overfitting에 취약한 fixed translation를 학습하는 것보다 target domain label에 따라 유연하게 변환하도록 학습하는 게 여러 domain에 보편적으로 적용 가능한 reliable features를 배우게 한다는 것이다.
또 IcGAN에 비해서는 input의 facial identity feature를 보존하는 장점이 있다. 이는 IcGAN처럼 low-dimensional latent vector가 아니라 convolutional layer에서 온 activation maps를 latent representation으로 사용하여 spatial information을 유지하기 때문으로 추측한다.
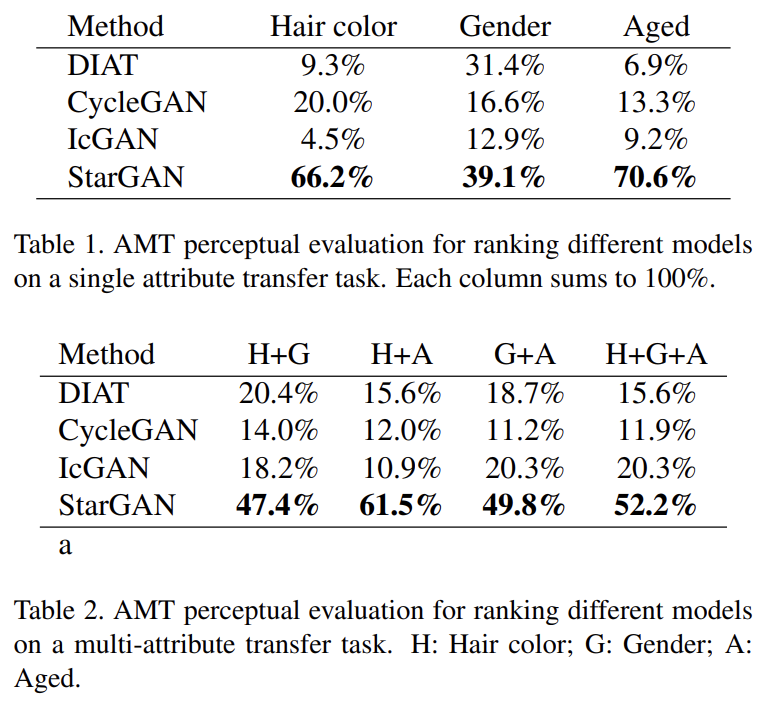
quantitive evaluation을 위해서는 Amazon Mechanical Turk (AMT)를 이용해 두 user studies를 수행했다.

RaFD로 facial expression synthesize를 학습하는 과제의 경우 StarGAN은 input의 personal identity와 facial features를 유지하면서 natural-looking expressions를 생성할 수 있었다. 반면 DIAT와 CycleGAN의 경우 identity는 유지했으나 결과가 blurry했고 input의 degree of sharpness를 유지하지 못했다. IcGAN은 남성 이미지를 생성함으로써 personal identity조차 유지하지 못했다.
논문은 StarGAN의 image quality 우수성이 multi-task learning setting에서 온 implicit data augmentation effect 때문으로 추측한다. RaFD는 상대적으로 적은 양의 sample을 가지는데(domain 당 500 image) DIAT와 CycleGAN가 한번에 1000개를 사용하는 반면 StarGAN은 4000장을 사용한다.
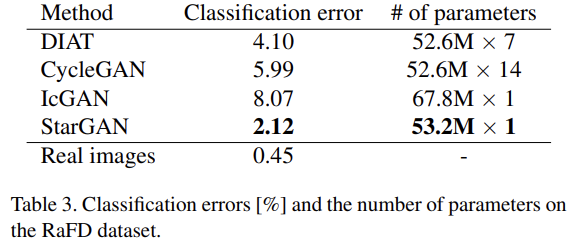
quantitive evaluation을 위해서 합성된 이미지에 classification error를 계산했다. ResNet-18 architecture를 RaFD에 학습해 99.55% 정확도를 얻었다. 그리고 동일한 training set에 학습하고 same, unseen test set에 image translation을 수행해서 Table 3의 결과를 얻었다. 또한 StarGAN은 single generator, discriminator만 필요로 하기 때문에 parameter가 적어 scalability의 이점도 있음을 볼 수 있다.

마지막으로 multiple dataset에 학습할 수 있는 능력을 확인하기 위해 RaFD에만 학습한 모델 StarGAN-SNG와 CelebA와 RaFD 모두 학습한 모델 StarGAN-JNT를 비교한다. Fig 6에서 StarGAN-JNT는 high visual quality와 함께 emotional expressions를 선보이지만 StarGAN-SNG는 합리적이지만 gray background와 blurry한 image를 만든다. 이는 StarGAN-JNT가 facial keypoint detection과 segmentation 같은 shared low-level tasks를 improve하도록 두 dataset을 leverage할 수 있음을 나타낸다.

또 StarGAN-JNT에 (두번째 데이터셋 RaFD에서 얻을 수 있는) 특정 facial expression에 dimension을 setting한 one-hot vector c를 주어 mask vector의 역할을 확인했다. 이 경우 두번째 dataset에서 얻은 label이므로 proper mask vector은 [0, 1]이 된다. Fig 7은 올바른 mask vector [0, 1]과 잘못된 mask vector [1, 0]이 주어졌을 때의 결과를 보여준다. 이는 잘못된 mask vector을 받은 모델이 facial expression label을 unknown으로 취급해 무시하고 facial attribute label를(여기서는 age) valid로 간주하기 때문이다.
Strengths
- mask vector와 label concatenate를 통해 여러 데이터셋을 모델 하나에 동시에 사용할 수 있는 게 큰 장점이다.
- CycleGAN처럼 reconstruct를 통한 일종의 auto-encoder 구조를 사용해서 visual quality를 높이고 원본 input image와의 동일성을 높였다.
Weaknesses
- StarGAN이라고 이름까지 붙이며 star topology를 차용했다고는 하는데 논문의 실험은 겨우 데이터셋 n=2로 실험한 거라 성능을 일반화하기엔 무리가 있는 것 같다. 더 많은 데이터셋에도 잘 작동할지는 의문이 든다.
- 서로 다른 데이터셋의 label을 사용하고 싶으면 mask vector은 one-hot encoding이기 때문에 모델을 여러 번 통과해야하는 것 아닌가? 네트워크를 한 번 통과해서 동시에 여러 개의 attribute를 수정하지 못하는 게 단점인 것 같다.
