이번에 리뷰할 논문은 seq2seq 논문이다. 최초로 seq2seq를 제안한 논문은 아닌데(최초의 논문은 직전 리뷰에서 다뤘다) 성능/결과물이 뛰어나서 유명한 논문이라고 한다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
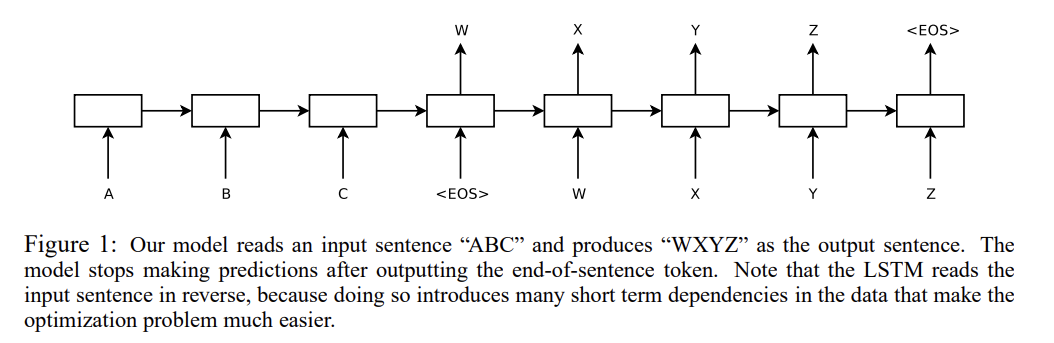
논문은 LSTM 2개를 encoder, decoder 역할로 연결해서 sequence 정보를 처리하고자 한다. WMT'14 데이터셋을 이용해 영어를 프랑스어로 번역하도록 학습하는데, 이때 input의 순서를 거꾸로 넣어준 것이 short term dependencies를 형성해 optimization 문제를 쉽게 만들어 LSTM이 긴 문장도 문제없이 처리할 수 있게 만든다.
논문은 RNN 대신 LSTM을 사용하는데, RNN의 사용은 input, output sequence의 길이가 다르고 non-monotonic relationships을 가질 때 부적절하기 때문이다.
모든 문장은 위의 사진처럼 특별한 end-of-sentence symbol "<EOS>"으로 끝나도록 했다. 또 deep LSTM이 shallow LSTM보다 높은 성능을 보였기 때문에 4층짜리 LSTM을 사용했다.
실험은 두 종류로 했는데 1. reference SMT system 없이 직접 input sentence를 번역했고 2. SMT baseline의 n-best lists를 rescore하기도 했다.
neural language model은 각 단어의 vector representation에 의존하기 때문에 영어, 프랑스어 모두에 고정된 크기의 vocabulary를 사용했다. source language에선 가장 자주 쓰이는 단어 16만개를, target language에선 가장 자주 쓰이는 단어 8만개를 사용했고 그 외의 단어는 모두 special “UNK” token으로 교체했다.
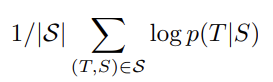
실험의 핵심은 large deep LSTM을 많은 sentence pair로 학습시키는 것이다. training set S 내에서 source sentence S가 주어졌을 때 correct translation T의 log probability를 최대화하도록 위와 같은 objective를 학습한다.

번역은 위의 식과 간단한 left-to-right beam search decoder를 사용하여 translation을 생성한다. decoder는 작은 숫자 B개의 partial hypothesis(=prefix of some translation)를 유지하는데, timestep마다 각 partial hypotheses를 vocabulary 내의 모든 단어로 확장한다. 이게 hypotheses 개수를 크게 증가시키기 때문에 log probability가 가장 큰 B개만 남기는 것이다. <EOS>가 나타나면 hypothesis를 beam에서 지우고 complete hypotheses 집합에 넣게 된다.
또 앞서 언급했듯 baseline SMT system의 1000-best lists를 rescore하는 데도 LSTM을(사실 LSTM 2개인 모델인데 논문에선 편의상 그냥 LSTM이라고 칭한다) 사용하는데, 모든 hypothesis의 log probability를 LSTM으로 계산해 baseline의 score과 LSTM의 score을 평균낸다.
논문은 (target sentence은 reverse하지 않고) source sentence를 거꾸로 넣는 것이 성능 향상을 보이는 현상의 원인을 추측한다. 일반적으로 정방향으로 source sentence와 target sentence를 concatenate하면 source sentence의 각 단어는 target sentence의 상응하는 단어와 거리가 멀다. 즉 "minimal time lag"를 가지는 문제가 생긴다. source를 reverse하면 상응하는 단어 간 평균 거리는 변하지 않지만, source의 첫 몇 개 단어들은 target의 첫 몇 개 단어와 아주 가까워지면서 minimal time lag 문제가 크게 감소한다. 따라서 backpropagation 시 source와 target sentence 간 "establishing communication"을 하기 쉬워진다.
처음에 저자들은 input을 reverse하는 것이 target sentence의 초반부에만 향상된 번역을 보이고 후반부는 덜 confident할 것이라고 생각했다. 하지만 reverse된 input으로 학습된 LSTM이 그렇지 않은 LSTM보다 긴 문장에서 번역을 더 잘하는 것을 보고 논문은 input을 reverse하는 것이 향상된 memory utilization를 야기한다고 추측했다.
구체적인 training detail을 설명하자면 다음과 같다. 층마다 1000개의 cell과 1000 dimensional word embeddings을 가진 4 layer의 deep LSTM을 사용했고 input vocabulary는 16만개, output은 8만개다. 각 output의 단어 8만개에 대해 naive softmax를 적용했다. 더 자세한 training detail은 다음과 같다.

실험 결과는 다음과 같다.
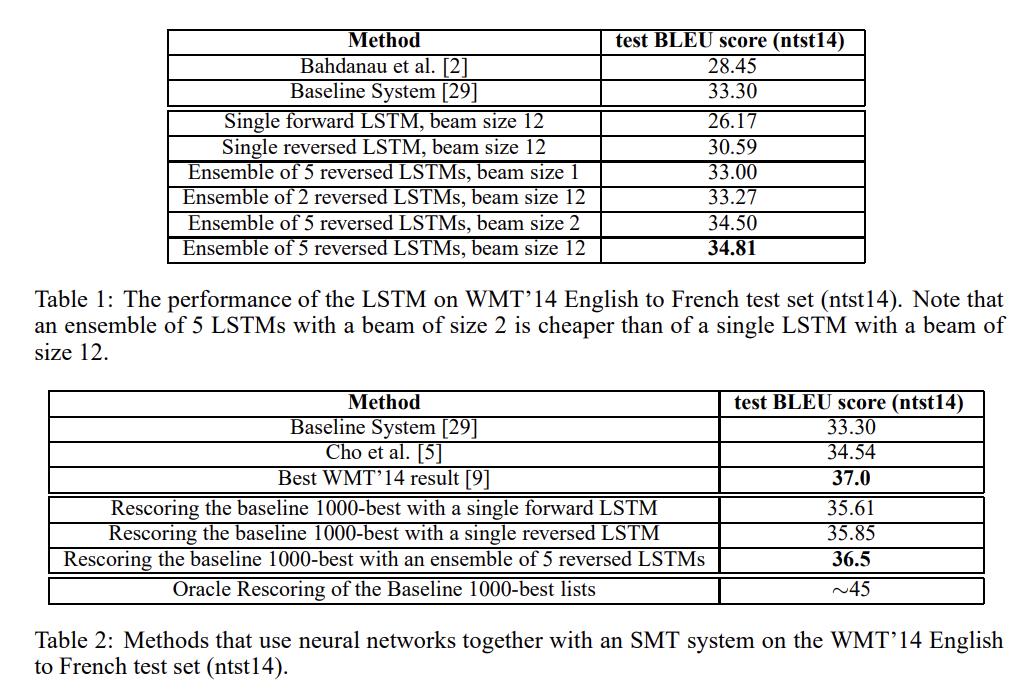
논문의 LSTM이 best WMT’14 system(37.0점)을 뛰어넘진 못하지만 pure neural translation system이 (out-of-vocabulary word을 처리할 능력 없이) phrase-based SMT baseline을 뛰어넘는 건 처음이다. 또 baseline의 1000-best lists를 rescore한 결과는 best WMT’14 result와 0.5점밖에 차이가 안 난다.
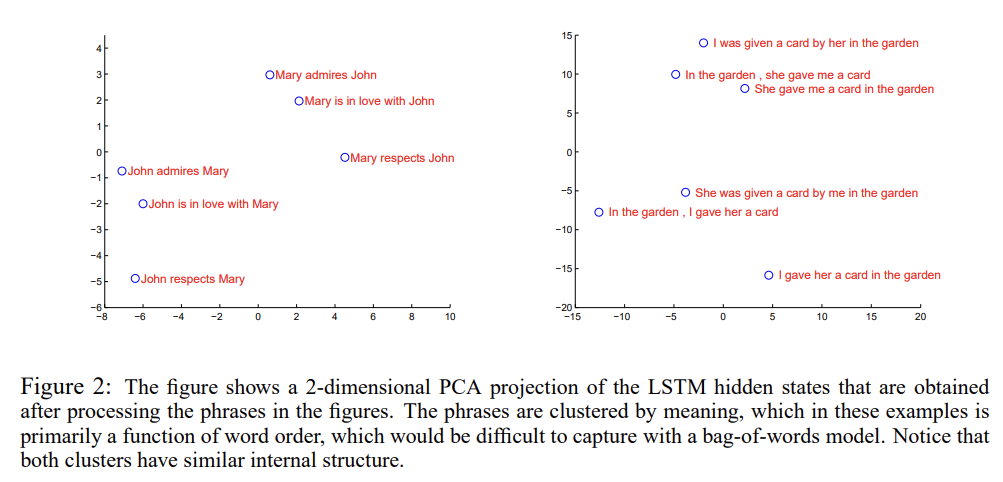
Fig 2는 learned representations를 PCA로 시각화한 예시다. representations들은 단어의 순서에 sensitive한데 active voice와 passive voice, 즉 능수동에 대해서는 insensitive했다. 따라서 왼쪽 사진에서 단어 순서에 따라 cluster이 된 것을 볼 수 있고 오른쪽 사진에서 능수동의 형태에 상관없이 의미적으로 비슷한 것끼리 cluster된 것을 볼 수 있다.
Strengths
- input 순서를 reverse한다는 간단한 발상 하나만으로 높은 성능 향상을 보였다. 이후 다른 연구에도 손쉽게 적용될 수 있는 방법이라 범용성이 높다.
- 논문의 모델은 8만개의 어휘에 대해서 학습을 하고 그 외의 어휘에 대해서는 점수에 불이익을 받는데도 SMT system에 비견할 만한 성능을 낸다. 즉 simple, straightforward, relatively unoptimized approach도 SMT system를 능가할 수 있음을 보여 seq2seq의 잠재력을 보여준다.
Weaknesses
- long sentence에 대한 번역이 향상되었다고 하는데, 예시뿐 아니라 구체적인 수치나 분석도 있으면 좋겠다. 증거가 좀 빈약해보인다.
사실 직전에 리뷰한 Cho et al의 seq2seq 논문과 encoder, decoder 2개를 연결한 것이나 WMT'14 데이터셋을 이용해 영어를 프랑스어로 번역하는 것이나 내용이 거의 똑같아서 처음엔 같은 저자가 쓴 논문인 줄 알았다. 둘의 차이점은 전자는 LSTM 대신 자기들이 고안한 GRU를 사용한 것이고 여기선 그냥 기존의 LSTM을 사용한 것, 그리고 전자는 기존의 SMT system에 편입하는 것에 더 집중했지만 여기선 이 모델을 독립적으로 사용하는 데 더 집중한 것이다.
복잡한, 이론적인 내용도 없고 본문도 거의 실험을 설명하는 내용 뿐이라 아주 빠르게 읽을 수 있었다. 사실 architecture에서 그닥 참신한 건 없는데 input을 reverse하게 넣는 것 하나만으로 좋은 성능 향상을 보인 것 같다.
