오늘 리뷰할 논문은 attention을 GAN에 적용한 SAGAN 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] Self-Attention Generative Adversarial Networks
- [paper-review] Self-Attention Generative Adversarial Networks
Summary
기존의 convolutional GANs는 서로 다른 image regions 사이 dependency를 model하기 위해 convolution에 크게 의존한다. convolution operator가 local receptive field를 가지기 때문에 long range dependency는 여러 층을 통과한 후에야 처리될 수 있다. 이는 long-term dependency의 학습을 여러 이유로 방해할 수 있는데, 예를 들어 작은 모델은 (층 수가 적으므로) dependency를 표현하지 못할 수도 있고, optimization algorithm이 여러 층이 함께 작동하는 parameter value를 못 찾을 수도 있고, parameterization이 기존에 없던 형태의 input에 취약할 수도 있다. 그렇다고 convolution kernel 크기를 키우면 representational capacity는 늘지만 연산량도 많아져서 비효율적이다.
반면 self-attention은 long-range dependency를 model하는 능력과 computational, statistical efficiency를 잘 balance한다. self-attention module은 모든 위치의 feature의 weighted sum으로 계산하고 이는 적은 연산 비용으로 가능하다.
논문은 Self-Attention Generative Adversarial Networks (SAGANs)을 제안하여 self-attention mechanism을 convolutional GAN에 도입한다. self-attention은 convolution과 상호 보완적이며 image region 간 long range, multi-level dependencies를 modeling하는 데 돕는다. 덕분에 generator은 모든 위치에서의 fine detail이 멀리 있는 detail과 조화되는 이미지를 그릴 수 있다. discriminator는 더 정확하게 전체 이미지 구조에서의 복잡한 기하학적인 constraints를 부과한다.
또 well-conditioned generator가 좋은 성능을 보이는 경향에 따라 기존에는 discriminator에만 적용되던 spectral normalization technique을 generator에 사용하여 conditioning한다.
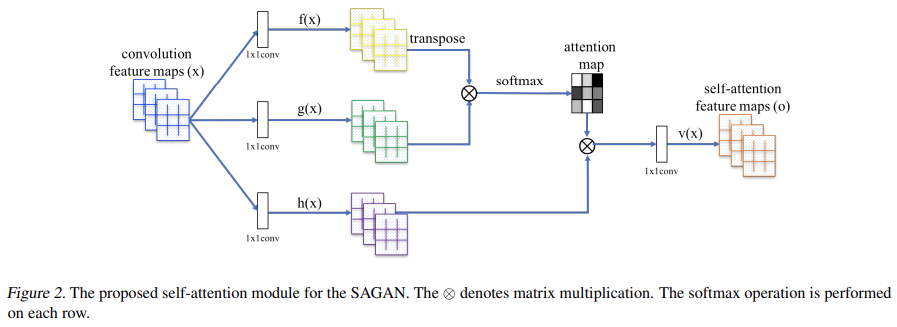
previous hidden layer에서 온 image feature x ∈ 은 먼저 attention을 계산하기 위해 두 feature space f, g로 transform된다. 이다. (f,g는 각각 query, key로 변환하는 계산과정으로 생각할 수 있겠다.)
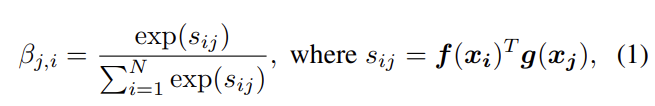
는 j번째 위치(=픽셀)를 합성할 때 i번째 위치(=픽셀)를 attend하는 정도다(즉 attention score이다). C는 channel의 수, N은 previous hidden layer에서 온 feature의 locations의 수(즉 HxW인듯), attention layer의 output은 이다.
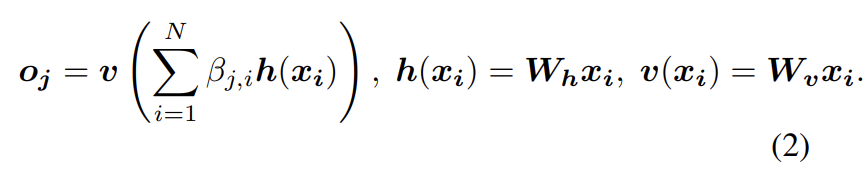
위의 는 1×1 convolutions로 구현된 learned weight matrices다.
로 조정하며 실험했는데, 채널 수를 줄여도 성능 하락이 나타나지 않았기 때문에 메모리 효율을 위해 가장 적은 채널 수 k=8를 선택했다.
그리고 attention layer의 output에 scale parameter을 곱하고 input feature map을 더해준다.

γ는 0으로 초기화된 learnable scalar이다. 이는 network가 처음에는 local neighborhood의 cues에 의존하고 점진적으로 non-local evidence에 더 많은 비중을 두도록 학습하는 것이다. 이렇게 하는 이유는 먼저 쉬운 과제를 배우고 나서 과제의 난이도를 점진적으로 올리는 직관에 바탕을 둔다. SAGAN에서 attention module은 generator와 discriminator 모두에 적용되며 hinge version of the adversarial loss를 최소화하는 방식으로 generator와 discriminator가 번갈아 학습된다.
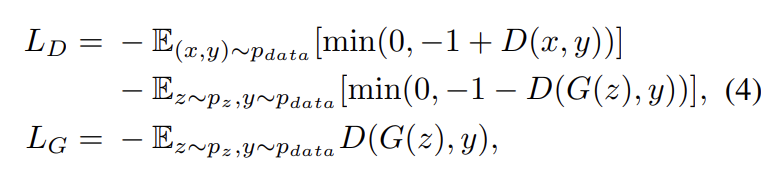
학습을 stabilize하기 위해 두 가지 기법을 사용한다. 첫째로 generator와 discriminator에 spectral normalization을 사용한다. 둘째로 two-timescale update rule (TTUR)이 효과적임을 확인했기 때문에 regularized discriminator에서 slow learning을 다루기 위해 사용한다(= Imbalanced learning rate for generator and
discriminator updates).
원래 spectral normalization은 학습을 안정화하기 위해 discriminator에 적용했다. 각 layer의 spectral norm을 제한하는 것으로 discriminator의 Lipschitz constant을 제약하는 것이다. 다른 normalization과 달리 extra hyper-parameter tuning가 필요하지 않고 연산량도 비교적 적다.
이 논문은 SN이 generator에도 효과적임을 주장한다. generator의 SN은 parameter 크기 증가를 막고 unusual gradients를 피한다. 논문은 경험적으로 SN을 G와 D 모두에 적용하는 것이 generator update 한 번 당 더 적은 횟수의 discriminator update를 가능하게 하여 학습의 연산량을 상당히 줄여줌을 발견했다. 또 더 stable한 학습도 가능했다.
기존 연구에서 discriminator의 regularization은 종종 GAN의 학습을 느리게 했다. 실제로 regularized discriminators를 쓰는 방법들은 generator update step 당 여러 번의 discriminator update steps를 요구했다. Heusel et al.는 G와 D에 separate learning rates (TTUR)를 사용했다. 논문은 TTUR이 regularized discriminator에서의 slow learning 문제를 완화하여 generator step 당 더 적은 discriminator steps을 가능하게 한다고 주장한다.
평가를 위해 실험은 LSVRC2012 (ImageNet) dataset를 사용했다. 첫째로 GAN의 학습을 안정화하는 두 기술의 효과를 평가했고 둘째로 self-attention mechanism를 확인했다. 마지막으로 SAGAN을 SOTA 방법들과 비교했다. 양적 평가의 evaluation metric으로는 Inception score
(IS)과 Frechet Inception distance (FID)를 사용했다.
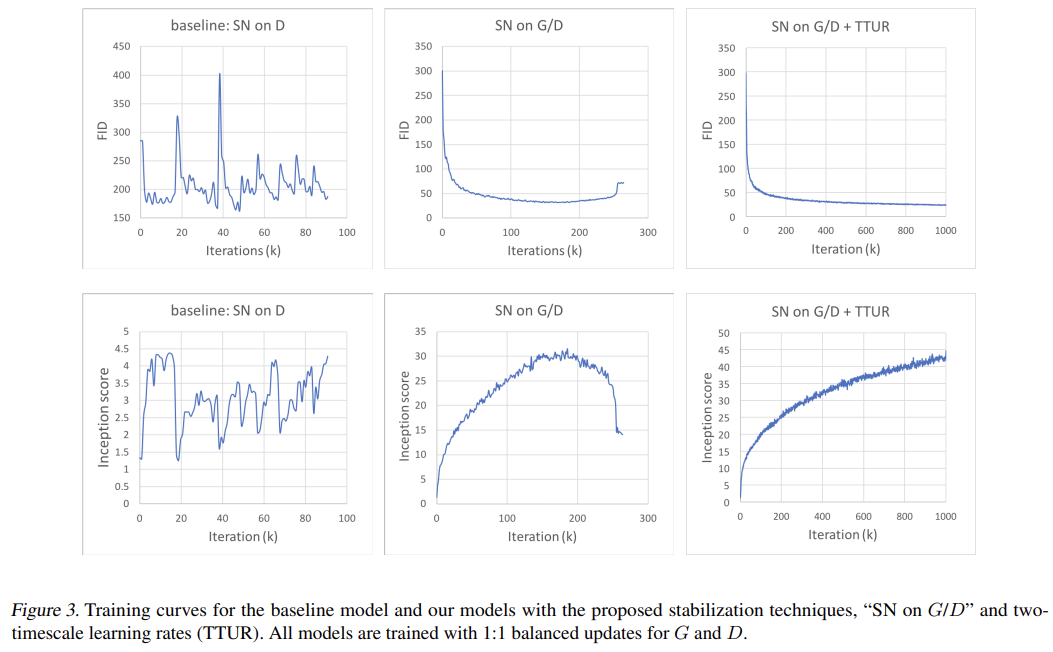
Fig 3은 stabilization techniques의 효과를 확인한 결과다. 논문의 모델인 “SN on G/D”과 “SN on G/D+TTUR”가 discriminator에만 SN을 적용한 baseline과 비교되고 있다. generator과 discriminator을 1:1로 update했을 때 두 안정화 기법을 적용한 논문의 모델이 더 안정적이다.

self-attention의 효과를 확인하기 위해 논문은 모델 여러 개를 만들어서 self-attention을 G와 D의 서로 다른 stages에 추가해 실험한다. Tab 1에서 볼 수 있듯 middle-to-high level feature maps (e.g., feat32 and feat64)에 더하는 것이 low level feature maps (e.g., feat8 and feat16)보다 더 좋은 성능을 보인다. 이는 self-attention이 larger feature maps을 가지고 더 많은 정보(evidence)를 받고 conditions을 선택할 자유도를 더 많이 누리기 때문이다(즉 large feature map에 대해 self-attention이 convolution에 상호보완적이다). 반면 small feature maps에 대한 dependency를 modeling할 때는 local convoltion과 비슷한 역할을 한다(즉 상호보완적이지 못하다). 이는 attention mechanism이 G와 D 모두에게 feature map 내 long-range dependencies를 model하는 능력을 강화함을 입증한다.
동일한 parameter 수의 residual block과 비교해도 self-attention block은 더 좋은 결과를 보인다. 예를 들어 8×8 feature maps에서 self-attention block을 residual block으로 대체하면 학습이 불안정해 성능이 떨어진다. feature map 32 × 32에서 학습이 불안정하지 않은 경우도 여전히 FID와 Inception score 결과가 낮아짐을 통해 SAGAN의 성능 향상이 단순히 모델 depth와 capacity로 인한 것이 아님을 보여준다.


Fig 1, 5는 generation process 도중 학습한 것을 더 잘 이해하기 위해 여러 이미지에서 generator의 attention weight을 시각화한 것이다.

마지막으로 SAGAN을 SOTA 방법들과 비교한다.
Strengths
- self-attention과 GAN을 결합해서 long-term dependency를 모델링하고 좋은 성능 향상을 보였다. 아이디어가 단순하고 강력하다.
- 작은 feature map이 아니라 큰 feature map에서 self-attention을 적용해 (local dependency는 잘 포착할 수 있는) convolution과 상호보완적인 효과를 보였다.
- 두 stabilization techniques의 효과가 훌륭해서 generator와 discriminator을 1:1로 업데이트할 수 있었다.
