오늘 리뷰할 논문은 MobileNetV3이다. network search에 대한 사전 지식이 없어서 이해도가 낮다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [논문 읽기] MobileNetV3(2019) 리뷰, Search for MobileNetV3
- MobileNetV3 논문 설명(Searching for MobileNetV3 리뷰)
Summary
논문은 complementary search techniques의 조합과 새로운 architecture로 MobileNetV3를 제시한다. MobileNetV3는 NetAdapt algorithm로 보완되는 hardwareaware network architecture search (NAS)의 조합을 통해 mobile phone CPUs에 tune되어있다. 논문은 어떻게 automated search algorithms과 network design이 상호보완적으로 작동할 수 있는지 탐구한다. 그리고 high/low resource case를 위해 두 모델 MobileNetV3-Large, MobileNetV3-Small를 만들어 object detection과 semantic segmentation에 적용한다.
논문의 목표는 mobile device에서 accuracy-latency trade off를 최적화하는 가능한 최고의 mobile computer vision architecture을 개발하는 것이다. 이를 위해 (1) complementary search techniques, (2) mobile setting에 실용적인 새로운 효율적인 nonlinearities, (3) 새로운 효율적인 network design, (4) 새로운 효율적인 segmentation decoder를 소개한다.
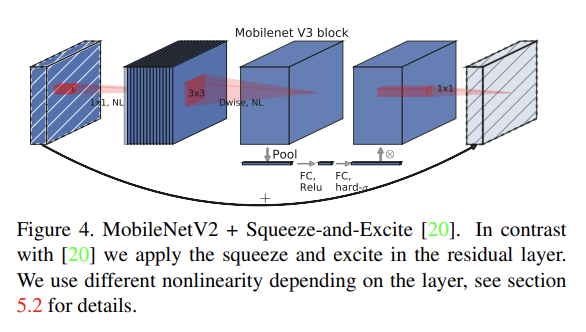
MnasNet [43]는 MobileNetV2를 바탕으로 squeeze and excitation에 기반한 lightweight attention modules을 bottleneck structure에 도입한다. squeeze and excitation module가 integrate되는 위치가 SENet [20]에 제안된 ResNet based module과 다르다는 것에 주의하라. Fig 4처럼 module은 expansion 내의 depthwise filters 이후에 위치하며, 이는 attention을 가장 큰 representation에 적용하기 위함이다.
MobileNetV3는 이 layers를 building block으로 삼는다. layers는 modified swish nonlinearities [36, 13, 16]로 upgrade된다. squeeze and excitatio와 swish nonlinearity는 모두 sigmoid를 쓰는데 이는 연산이 비효율적이고 fixed point arithmetic에서 정확도를 유지하기 어렵기 때문에 sigmoid를 hard sigmoid [2, 11]로 교체한다.
Network Search는 network architecture을 발견하고 최적화하는 데 강력한 도구다. MobileNetV3는 platform-aware NAS를 사용해서 각 network block을 최적화함으로써 global network structures를 search한다. 그 다음 NetAdapt algorithm를 사용해서 layer 당 다수의 filters를 찾는다. 이 기술들은 상호보완적이며 주어진 hardware platform에 대해 최적화된 model을 효과적으로 찾기 위해 조합될 수 있다.
Platform-Aware NAS for Block-wise Search
[43]과 비슷하게 platform-aware neural architecture approach를 사용해 global network structures를 찾는다. 동일한 RNN-based controller와 factorized hierarchical search space를 쓰기 때문에 Large mobile models는 [43]과 비슷한 결과를(target latency가 80ms 근처) 얻었다. 따라서 initial Large mobile models로 MnasNet-A1 [43]를 재사용하고 그 다음 NetAdapt [48]와 다른 optimization을 거기에 적용했다
NetAdapt for Layer-wise Search
network search에 사용한 두 번째 기술은 NetAdapt [48]이다. 이는 platform-aware NAS와 상호보완적인데, coarse but global architecture를 infer하는 대신 sequential manner로 layers를 각각 fine-tuning하기 때문이다. 원본 논문의 technique은 다음과 같은 순서로 진행된다.

[48]에서 metric은 accuracy change를 최소화하는 것이었다. 논문은 이 알고리즘을 수정해서 latency change와 accuracy change의 비율을 최소화한다. 즉 각 NetAdapt step마다 생성된 모든 proposals 중 (∆latency가 2(a)의 조건을 만족하는) 을 최대화하는 하나를 고르는 것이다. proposals이 descrete하기 때문에 trade-off curve의 slope를 최대화하는 proposal을 선호한다고 직관적으로 이해할 수 있다.
이 과정은 latency가 target에 도달할 때까지 반복하고 그 다음 맨처음(scratch)부터 새로운 architecture을 재학습한다. [48]과 같은 proposal generator을 사용하여 다음 두 종류의 proposal을 생성한다.

실험에는 T = 10000, δ = 0.01|L|을 썼고 L은 seed model의 latency다.
network search에 추가로 model에 여러 components를 도입한다. network 처음과 끝의 computionally-expensive layers를 다시 디자인하고 기존 swish nonlinearity를 수정하여 연산이 더 빠르고 더 quantization-friendly한 h-swish를 사용한다.
network 처음과 끝의 몇 layers는 expensive한데, 논문은 몇 개의 수정점을 제안해서 slow layers의 latency를 줄이면서 accuracy를 유지하고자 한다. 이 수정점들은 current search space의 scope 바깥에 있다.
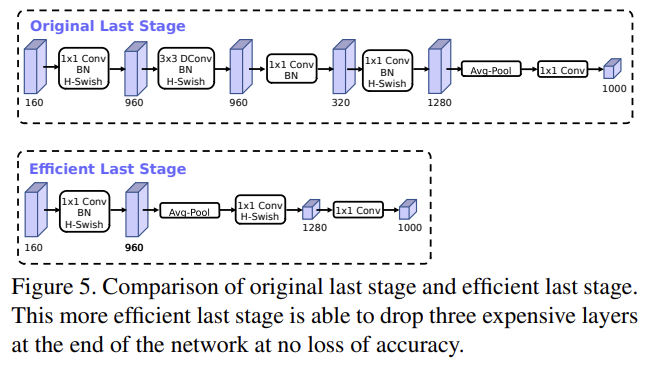
첫번째 수정점은 final features을 더 효율적으로 생성하기 위해 last few layers가 interact하는 것을 손본다. MobileNetV2’s inverted bottleneck structure에 기반한 현재 모델들은 higher-dimensional feature space로 확장하기 위해 1x1 convolution를 final layer로 사용한다. 이는 reach feature을 얻기 위해 매우 중요하지만, extra latency라는 비용이 든다.
latency를 줄이고 high-dimensional features는 보존하기 위해 이 layer을 final average pooling을 통과하도록 위치를 이동시킨다. final set of features는 이제 7x7 spatial resolution 대신 1x1 spatial resolution에서 계산된다. 이 디자인의 결과는 computation과 latency의 관점에서 features의 computation이 거의 공짜가 된다는 것이다.
feature generation layer의 비용이 완화된 이상 previous bottleneck projection layer는 더 computation을 줄일 필요가 없다. 이는 previous bottleneck layer에서 projection and filtering layers를 제거할 수 있게 하여 computational complexity를 더 줄여준다.
또 다른 expensive layer은 inital set of filters다. current mobile models는 edge detection을 위한 initial filter banks를 만들기 위해 full 3x3 convolution로 32 filters를 사용하는 추세다. 종종 이 filter들은 서로 대칭(mirror image)이다. 논문은 불필요한 중복(redundancy)을 줄이기 위해 filter 숫자를 줄이고 다른 non-linearity를 사용해 실험했다. 실험 결과 이 layer에 hard swish nonlinearity를 사용하기로 했고 accuracy를 유지하면서 (ReLU나 swish를 사용하여) filter 숫자도 16개로 줄였다. 이 방법으로도 latency를 줄일 수 있었다.
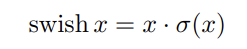
[36, 13, 16]에는 ReLU의 drop-in replacement로써 swish non-linearity를 소개하여 정확도를 높인다. 그러나 mobile device에서 sigmoid 연산은 더 부담스럽다는 단점이 있다. 논문은 이 문제를 두 가지 방법으로 다룬다.
- sigmoid를 piece-wise linear hard analog, 로 교체한다. hard version은 다음과 같다.
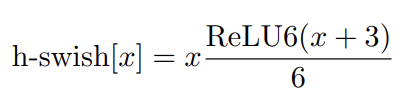
soft와 hard 버전의 차이는 아래와 같다.
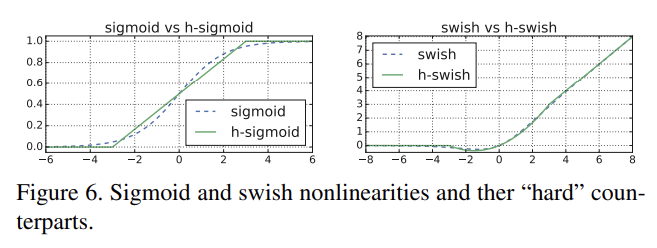
실험 결과 이 함수들의 hard 버전은 accuracy에 차이가 없었는데, deployment 관점에서 장점이 있었다. 첫째로 ReLU6의 최적화된 구현이 거의 모든 software와 hardware에서 사용가능하다는 것이다. 둘째로 quantized mode에서 approximate sigmoid의 서로 다른 구현으로 인한 potential numerical precision loss를 제거한다는 것이다. 마지막으로 h-swish는 memory access 횟수를 줄이기 위해 piece-wise function으로 구현될 수 있어 latency cost를 상당히 줄여준다.
- 각 layer에서 resolution이 떨어질 때마다 activation memory가 보통 절반으로 줄기 때문에 nonlinearity를 적용하는 cost는 network 깊이 들어갈수록 작아진다. 그런데 swish의 대부분 이익은 swish를 deeper layers에서만 사용하는 것으로 얻을 수 있다. 따라서 논문의 architecture에선 h-swish를 모델의 후반부 절반에서만 사용한다.
[43]에서 squeeze-and-excite bottleneck의 크기는 convolutional bottleneck의 크기에 비례했다. 그러나 여기서는 expansion layer의 channel 수의 1/4이 되게 고정했다. 이는 latency cost 증가 없이, 약간의 parameter 수만 늘리면서 accuracy를 늘릴 수 있다.
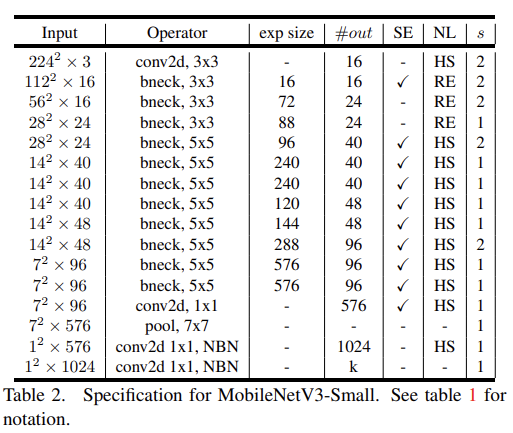
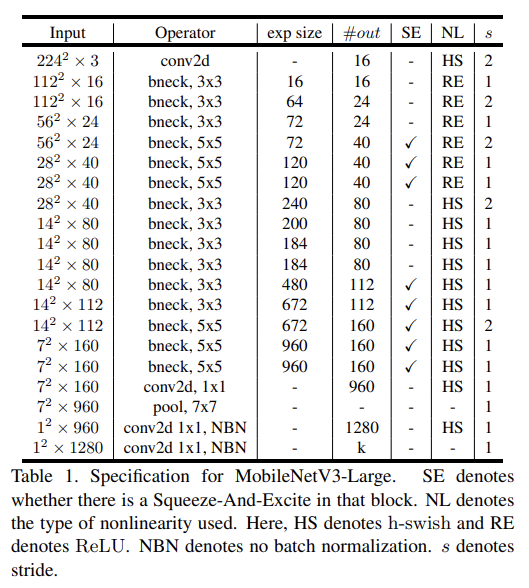
각각 high, low resource use cases에 대해 MobileNetV3-Large와 MobileNetV3-Small을 정의했다. 실험은 classification, detection, segmentation를 평가하고 ablation study도 한다.
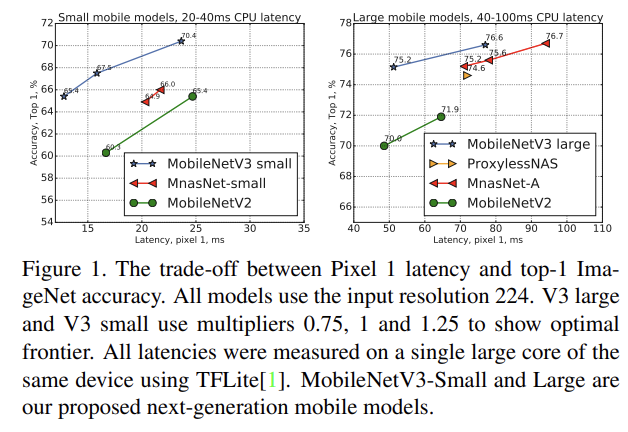
classification은 ImageNet 데이터셋에 수행하고 accuracy와 latency나 multiply adds (MAdds) 같은 resource usage measures를 측정한다. Fig 1에서 SOTA보다 성능이 좋음을 볼 수 있다.
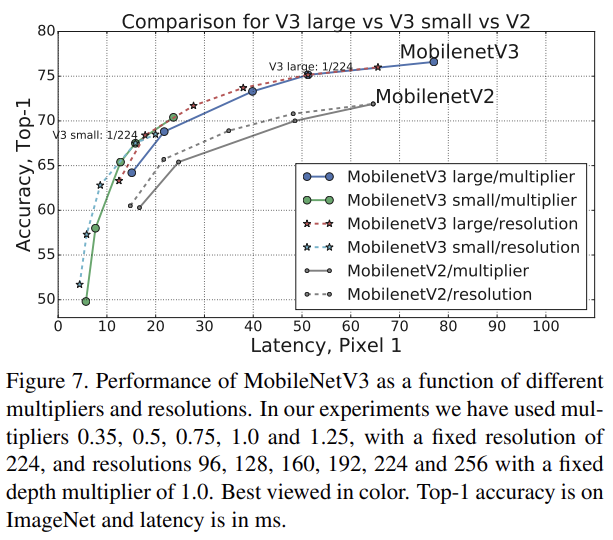
Fig 7은 multiplier와 resolution의 함수로써 MobileNetV3 performance trade-offs를 보여준다. MobileNetV3-Small는 mutliplier가 scale된 상태에서 MobileNetV3-Large보다 성능이 좋다. 한편 resolution은 multiplier보다 더 좋은 tradeoff를 제공한다.
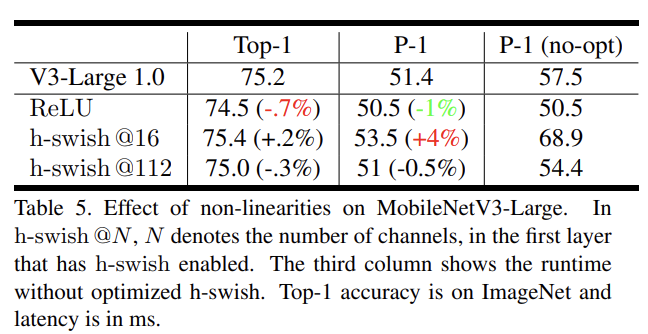
Table 5는 naive implementation과 optimized implementation를 비교하고 h-swish nonlinearities를 어디에 삽입할지 ablation study한다. h-swish의 optimized implementation이 6ms(runtime의 10% 이상)을 줄여줌을 확인가능하다. traditional ReLU에 비하면 Optimized h-swish는 추가로 1ms만 더한다.
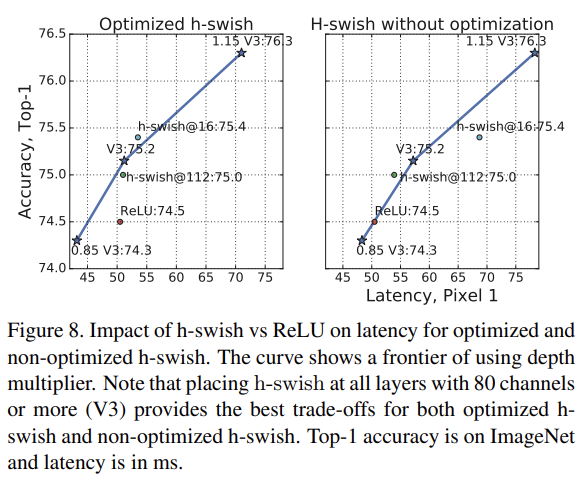
Fig 8은 nonlinearity choices와 network width에 기반한 효율적인 frontier를 보여준다. 네트워크 중간에 넣은 h-swish는 확실히 ReLU를 능가한다. h-swish를 네트워크 전체에 적용하면 interpolated frontier of widening the network보다 약간만 좋은 점이 흥미롭다.
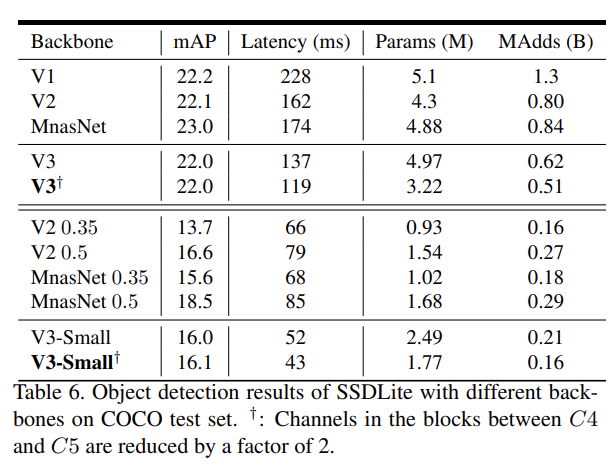
MobileNetV3를 SSDLite 내의 backbone feature extractor로 대체해 COCO dataset에서 다른 backbone networks와 detection 성능을 비교한다. 자세한 설명은 생략한다.
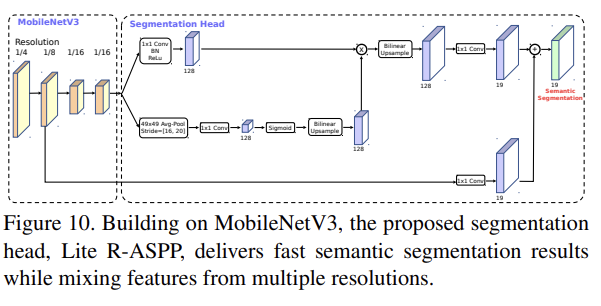
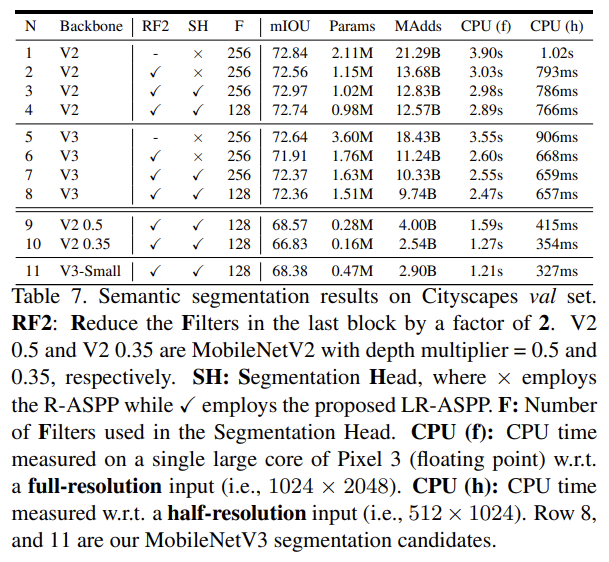
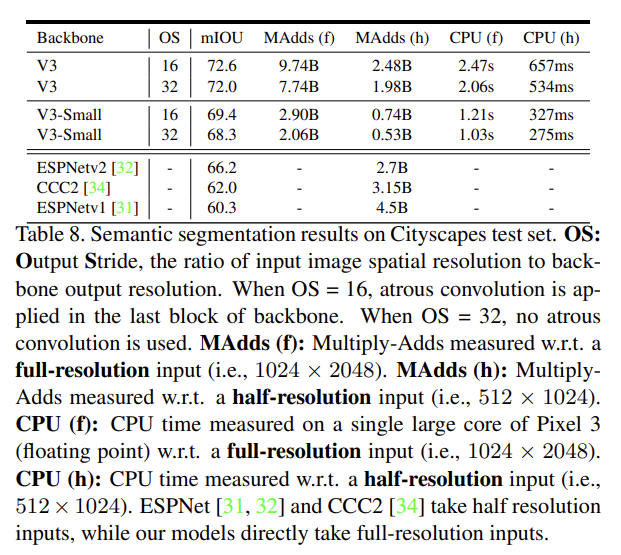
마지막으로 mobile semantic segmentation task에 MobileNetV2와 MobileNetV3를 network backbone으로 사용해 Cityscapes dataset에 평가한다. 자세한 설명은 생략한다.
Strengths
- SENet 구조를 적용한 점이 특이했다.
- 논문이 목표한대로 trade off를 잘 조율하며 MobileNetV2보다 효율적이다.
