오늘 리뷰할 논문은 StructBERT 논문이다. StructBERT는 BERT가 문장과 단어의 순서를 이해하도록 확장한 모델이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- StructBert Review
- StructBERT: Incorporating Language Structures into Pretraining for Deep Language Understandin 논문 정리
Summary
논문은 Elman [8]의 linearization exploration work에서 영감을 받아 language structures를 pre-training에 통합함으로써 BERT를 StructBERT라고 이름붙인 새로운 모델로 확장한다. 구체적으로는 StructBERT를 두 개의 auxiliary tasks로 pre-train해서 (word/sentence level에서 language structure을 leverage하는) words/sentences의 sequential order를 최대한 활용한다.

원본 BERT는 두 개의 task, MLM과 NSP로 pre-train을 한다. 반면 StructBERT는 MLM task의 능력을 증폭하고자 word masking 이후 몇 개의 token을 순서를 섞어서 올바른 순서를 맞추게 한다. 또 문장 간 관계를 더 잘 이해하도록 문장 순서도 섞어서 next sentence와 previous sentence를 예측하게 한다. 이 방식으로 StructBERT는 문장 내의 fine-grained word structure와 inter-sentence structure 둘 다를 bidirectional manner로 포착할 수 있다.
input x는 sequence of word tokens이며, single sentence일 수도 pair of sentences packed together일 수도 있다. input representation은 원본 BERT 논문을 따른다. 각 input token t_i에 대해 input representation x_i는 상응하는 token embedding, positional embedding, segment embedding을 합쳐 계산된다. 모든 sequence의 첫 token에 항상 special classification embedding ([CLS])를 더하고 각 segment의 마지막에 special end-of-sequence ([SEP]) token을 더한다. texts는 WordPiece [30]를 가지고 subword units로 tokenize되며 (최대 512 tokens의 supported sequence lengths를 가지고) absolute positional embeddings가 학습된다. 추가로 segment embeddings는 BERT에서처럼 pair of sentences를 구분하기 위해 사용된다.
input representation을 위한 contextual information을 encode하기 위해 multi-layer bidirectional Transformer encoder [26]를 사용한다.

앞서 설명했듯 MLM과 두 가지 auxiliary objective를 함께 pre-train한다.
1. word structural objective (single-sentence task를 위해)
2. sentence structural objective (sentence-pair task를 위해)
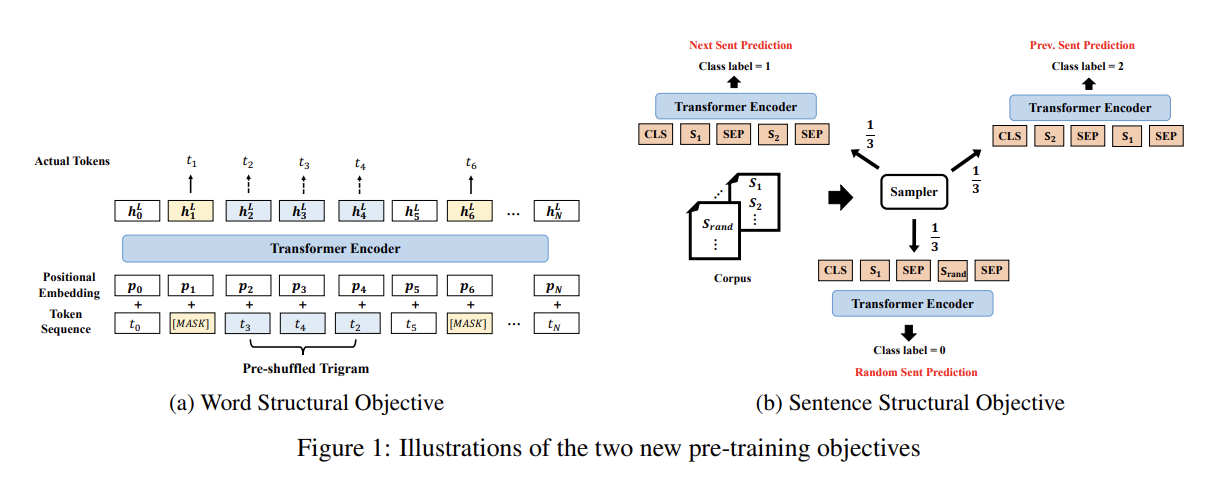
- Word Structural Objective
원본 BERT처럼 모든 input sentence에서 랜덤하게 15%의 token을 mask하고 bidirectional Transformer encoder가 계산한, masked tokens에 상응하는 output vectors 는 softmax classifier에 먹여져 original token을 예측한다.
word objective는 모든 shuffled token을 올바른 위치로 정렬하는 likelihood를 최대화하는 것이다.
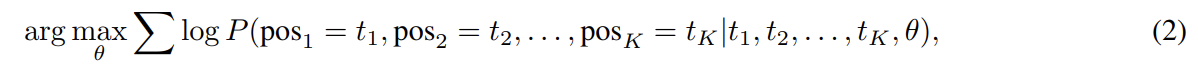
θ는 StructBERT의 set of trainable parameters, K는 모든 shuffled subsequence의 길이다. K가 클수록 더 긴 sequence를 복원할 수 있을 것이고 K가 작을수록 더 못할 것이다. 논문은 language reconstructability와 모델의 robustness를 balance하기 위해 subsequence shuffling에 대해 trigrams (K = 3)를 사용했다.
구체적으로는, unmasked tokens에서 일정 비율의 trigrams을 랜덤하게 선택한 후 각 trigram 내의 세 단어를 shuffle해서 shuffled tokens의 output vector가 softmax classifier에 넣어져 (올바른 순서대로) original token을 예측하게 한다. MLM과 Word Ordering Objective는 공동으로 학습되며 동일한 weight으로 학습된다(최종 loss에 반영비율이 같다).
- Sentence Structural Objective
next sentence prediction task는 원본 BERT에게 정확도가 97~98%일 정도로 쉽다. 따라서 모델이 문장들의 sequential order를 bidirectional manner로 인지하도록 sentence prediction task를 next sentence와 previous sentence 둘 다를 예측하도록 확장한다.
pair of sentences (S1, S2)가 input으로 주어졌을 때 S2가 S1의 next sentence인지, previous sentence인지, 다른 document에서 온 random sentence인지 예측한다. 구체적으로는 각각 1/3 확률로 sample한다. 원본 BERT에서처럼 두 문장은 사이에 separator token [SEP]를 두고 하나의 input sequence로 concatenate된다. first token [CLS]의 encoding vector를 softmax classifier에 넣어 three-class prediction을 수행한다.
- Pre-training Setup
training objective function은 word structural objective와 sentence structural objective의 linear combination이다. MLM은 원본 BERT와 동일한 masking rate와 setting을 사용했다. random shuffling은 5%의 trigrams가 선택됐다.
pre-training data는 English Wikipedia (2,500M words)와 BookCorpus [35]를 사용했고 원본 BERT를 따라 preprocessing과 WordPiece tokenization를 했다. input sequence의 최대 길이는 512로 설정했다. Adam, 0.1 dropout, gelu activation을 사용했다.
Transformer block layers의 수를 L, hidden vector size를 H, self-attention heads의 수를 A라고 하고 두 가지 크기 모델에 실험을 했다.
downstream tasks 실험은 General Language Understanding Evaluation (GLUE benchmark), Standford Natural Language inference (SNLI corpus)와 extractive question answering (SQuAD v1.1)에 수행했다.
원본 BERT 논문을 따라 downstream tasks에 fine-tuning할 때 (data size에 따라) grid search나 exhaustive search를 해서 dev set에 가장 잘 작동하는 sets of parameters를 찾았다. 나머지 parameters는 pre-training과 동일하다.
Batch size: 16, 24, 32; Learning rate: 2e-5, 3e-5, 5e-5; Number of epochs: 2, 3; Dropout rate: 0.05, 0.1
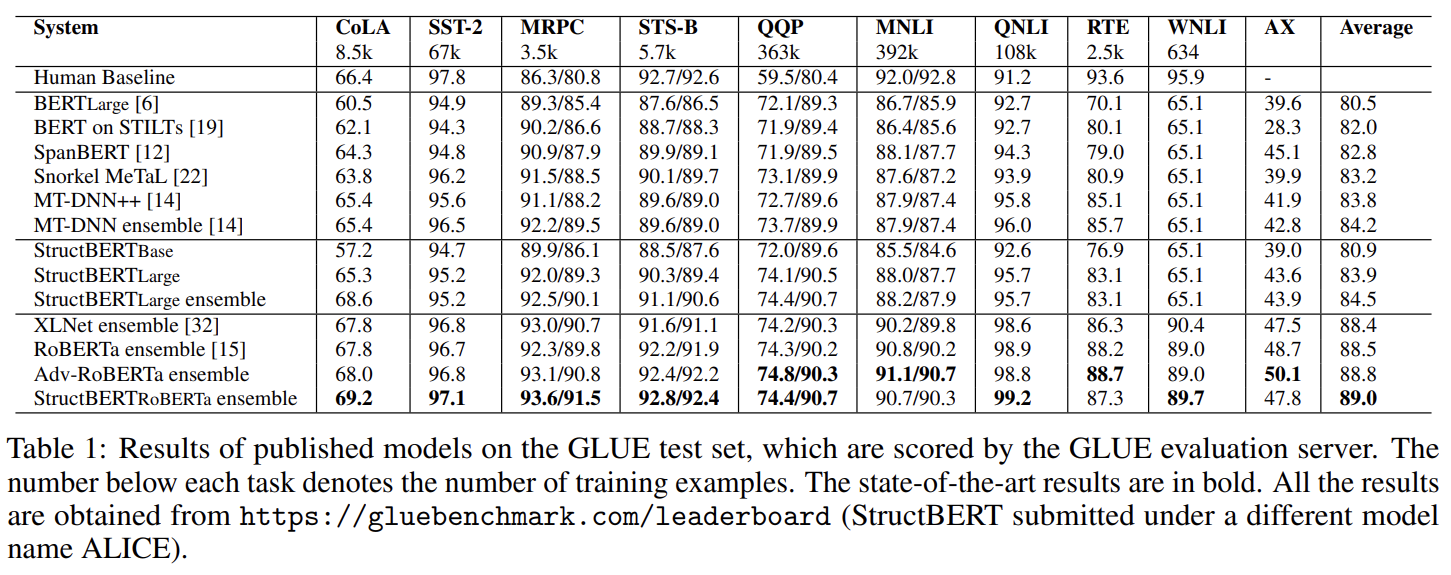
GELU benchmark는 9개의 NLU(natural language understanding) tasks, textual entailment (RTE [1] and MNLI [29]), question-answer entailment (QNLI [27]), paraphrase (MRPC [7]), question paraphrase (QQP), textual similarity (STS-B [4]), sentiment (SST-2 [25]), linguistic acceptability (CoLA [28]), Winograd Schema (WNLI [13])의 집합이다.

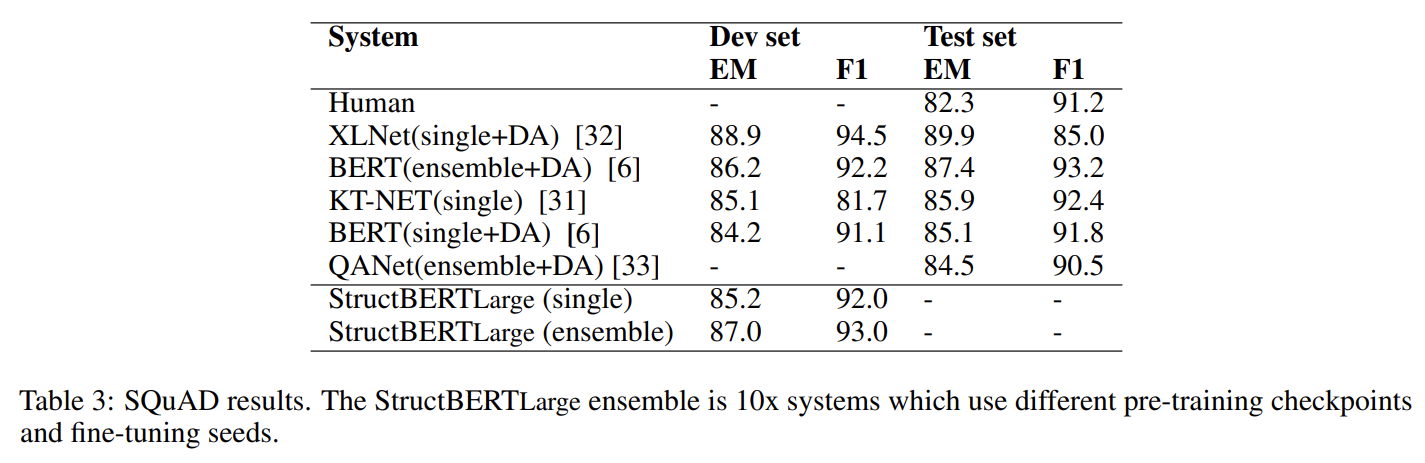
실험 설명은 생략한다.
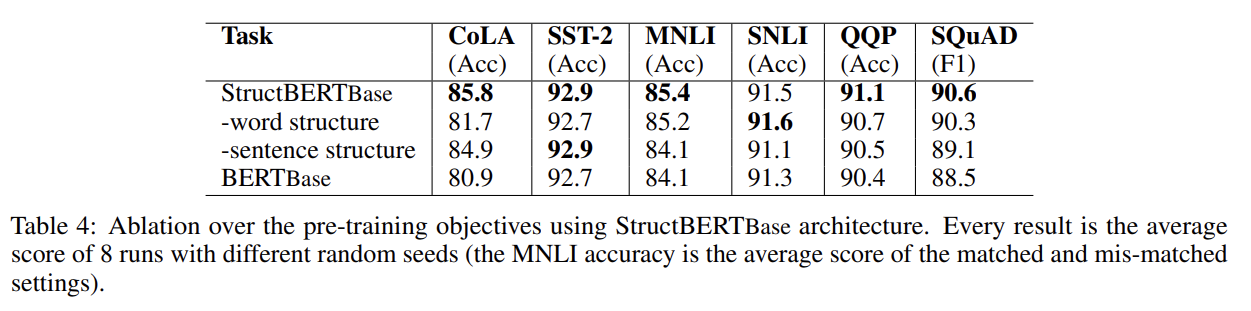
두 objective의 영향력을 알아보기 위한 ablation study도 했다. 두 objective 모두 대부분의 downstream tasks에 중요했으며 MNLI, SNLI, QQP와 SQuAD 같은 sentence-pair tasks에는 sentence structural objectiv가 성능을 상당히 향상시켰다. CoLA와 SST-2 같은 single-sentence tasks에는 word structural objective가 가장 중요한 역할을 했다.
Strengths
- word structural objective로 MLM을 확장하고 sentence structural objective로 NSP를 대체해 BERT가 단어와 문장 순서에 유의하도록 BERT를 확장했다.
