오늘의 논문은 object detection에 사용되는 R-CNN 논문이다. object detection은 물체의 위치(localization)와 종류(classification)를 모두 찾아내는 것이다. object detection은 localization과 classification을 동시에 수행하는 1-stage detector과 2단계에 걸쳐 따로 수행하는 2-stage detector가 있으며 R-CNN은 2-stage detector에 속한다.
참고로 논문은 업데이트된 버전 Tech report(v5)이다. sliding-window CNN 방식을 이용하는 OverFeat detection system과 R-CNN을 비교하는 것이 추가된 듯하다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
Summary
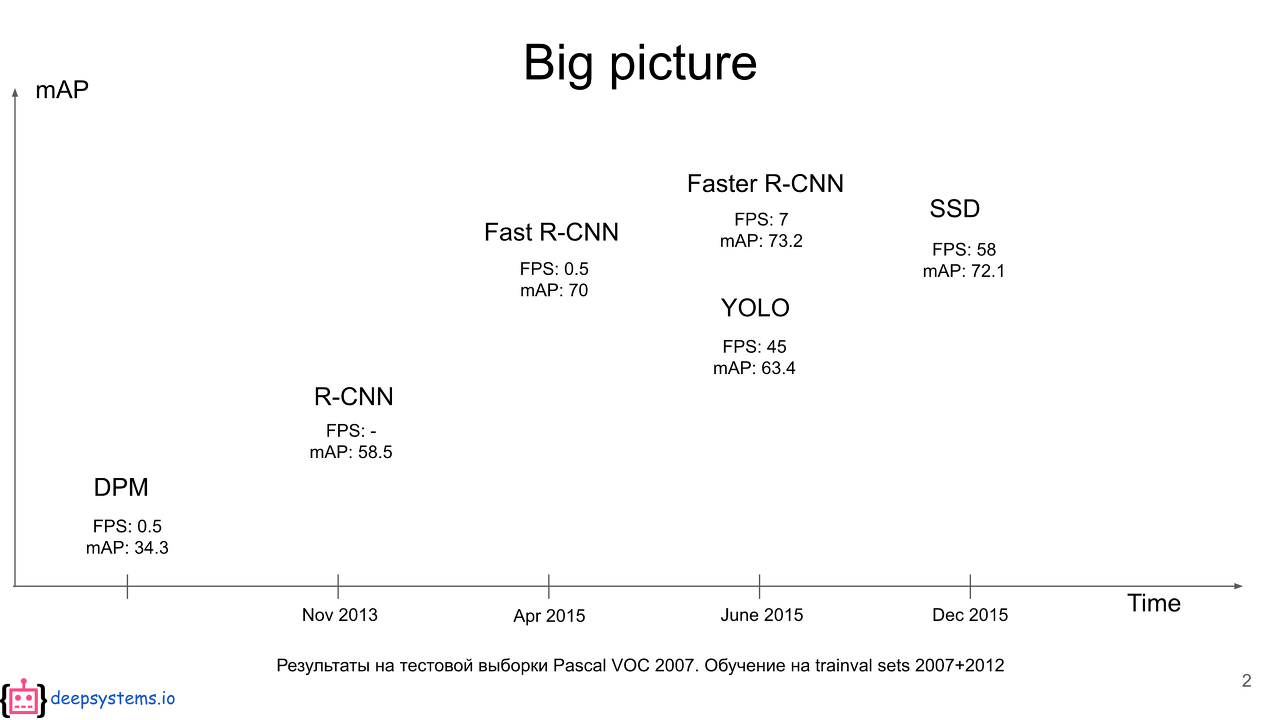
PASCAL VOC dataset을 이용한 최근(당시)까지의 object detection은 multiple low-level image features와 high-level context를 결합하는 복잡한 ensemble system이 가장 뛰어난 성과를 보였다. 하지만 이 방법은 최근(당시) 몇 년간 정체기에 접어들었다.
이 논문에서는 R-CNN을 통해 VOC 2012의 best result에 비해 mean average precision(mAP)를 30% 인상했다. 이는 2가지 핵심 통찰에 기반하며,
- object를 localize하고 segment하기 위해 high-capacity convolutional neural networks(CNNs)를 이용해 bottom-up region proposals를 했고
- label된 training data가 부족할 때 supervised pre-training에 이은 domain-specific fine-tuning 성능을 크게 향상시켰다.
이들은 기존의 HOG-like feature를 이용한 방식 대신 CNN을 이용하고자 문제를 2가지로 나누어 생각했다. deep network로 object들을 localizing하는 것, 그리고 적은 양의 annotated detection data만으로 high-capacity model을 training하는 것이다.
처음에는 localization을 위해 (기존에 많이 사용된) sliding-window detector 방식으로 CNN을 이용하려 했는데, 이 논문의 network는 5-layer라서 input image에 receptive fields(195 × 195 pixels)와 strides(32×32 pixels)가 매우 커서 precise한 localization이 힘들었다.
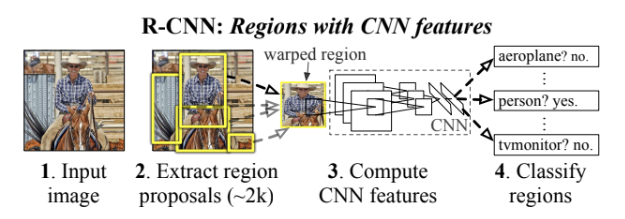
그래서 대신 CNN localization 문제를 object detection과 semantic segmentation에 모두 성공적인 “recognition using regions” paradigm으로 해결하고자 했다. test time에서 이 방법은 input image당 약 2000개의 category-independent region proposals를 생성하고 CNN으로 각 proposal로부터 fixed-length feature vector를 추출한다. 그리고 category-specific linear SVMs를 이용해 vector로 각 region을 classify한다. 각 region의 모양이 상관없도록 affine image warping를 사용해 fixed-size CNN input을 계산한다. 이 방법이 R-CNN이라 불리는 이유가 Region proposal과 CNN을 결합했기 때문이다.
두 번째 문제는 큰(large=high capacity) CNN을 학습하기엔 label된 학습 데이터가 부족하다는 것이다. conventional 해결책은 unsupervised pre-training에 이은 supervised fine-tuning을 하는 것이다.

R-CNN은 3개의 모듈로 이루어진다. 첫째는 category-independent region proposals를 생성한다. 둘째는 각 region으로부터 fixed-length feature vector를 추출하는 큰 CNN이다. 셋째 모듈은 set of class-specific linear SVMs이다. 각 모듈의 디자인을 알아보자.
-
Region proposals
region proposal에 관해선 이미 다양한 논문과 방법이 존재하고 R-CNN은 특정 region proposal 방법에 agnostic하지만, 기존의 detection work와 controlled comparison이 가능하도록 여기서는 selective search 방법을 사용한다. (정확히는 모든 실험에서 selective search "fast mode"를 사용) -
Feature extraction
Krizhevsky et al의 CNN의 Caffe implementation을 이용해 각 region에서 4096-dimensional feature vector를 추출한다. mean-subtracted 227×227 RGB image를 5개층의 convolutional layers과 2개층의 fully connected layers를 거치게 한다. 이때 CNN에 넣으려면 먼저 각 region을 227x227 크기로 맞춰야 한다. 여러 방법이 있겠지만 가장 간단하게 tight bounding box안에 모든 pixel을 요구된 크기로 warp한다. warping이전에 tight bounding box를 dilate해서 warp했을 때 원래 box 주변에 정확히 p pixels(여기서는 p=16)의 warped image context가 있게 한다.
그리고 각 class에 대해, 그 class에 맞춰 학습된 SVM을 사용해 추출된 feature vector들을 score한다. 모든 region이 scored됐을 때 (각 class에 따로) greedy non-maximum suppression를 적용해서 learned threshold보다 higher scoring selected region와의 intersection-over-union (IoU) overlap가 더 큰 영역을 reject한다.
이때 두 가지 특징이 R-CNN을 효율적으로 만든다. 첫째로 모든 category에 대해 CNN parameter가 공유된다는 것이고 둘째로 'spatial pyramids with bag-of-visual-word encodings' 같은 다른 common approaches에 비해 feature vector가 low-dimensional하다는 것이다. 유일하게 only class-specific한 연산들은 feature들과 SVM weights 간 dot products, 그리고 non-maximum suppression뿐이다.
training은 3단계를 거쳤는데 간단하게 설명하면
-
Supervised pre-training : open source Caffe CNN library를 사용해 large auxiliary dataset(ILSVRC2012 classification)를 pre-train했다.
-
Domain-specific fine-tuning : CNN을 새로운 task(detection)과 새로운 domain(warped proposal windows)에 적용하기 위해 warped region proposals만을 이용해 SGD를 한다. CNN의 ImageNet-
specific 1000-way classification layer를 랜덤하게 initialize한 (N + 1)-way classification layer (N은 object classes 수, 1은 background)으로 바꾸는 걸 빼면 CNN architecture은 똑같다. ground-truth box와 IoU overlap이 0.5 이상이면 그 box의 class에 positive으로(즉 정답이라고) 두었다. -
Object category classifiers : feature가 추출됐고 training label이 적용됐으니 class당 하나의 SVM을 optimize한다.
(리뷰에서는 생략한) error analysis에 기반하여 논문은 localization error를 줄이기 위해 DPM에서도 쓰인 bounding-box regression를 한다. selective search region proposal의 pool5 features가 주어졌을 때 새로운 detection window를 예측하는 linear regression model을 학습한 것이다.
Strengths
- 실험을 굉장히 많이, 철저히 진행했다. ablation study도 했고, fine-tuning의 효과나 dataset에 따른 차이 등 굉장히 다양한 경우의 수를 확인하며 R-CNN의 효과를 확인했다.
- dataset에 대한 고민을 많이 한 것 같다. label된 train data가 부족하기 때문에 먼저 ImageNet으로 fine-tuning을 한 것이라던가, validation/test set과 train set의 statistics(distribution)이 달라서 validation set을 val1, val2로 쪼개서 train+val1 set을 train에 쓰고 val2를 validation에 쓴 것이라던가.
- 특히 data가 scarce할 때, “supervised pre-training/domain-specific finetuning” paradigm이라는 효과적인 해결책을 제시했다.
- 기존의 computer vision 기술(selective search/region proposal)과 deep learning(CNN)을 결합해서 더 좋은 성능을 이끌어낸 점에서 비전 분야의 발전 가능성을 보여준 것 같다.
Weaknesses
- 이후 나온 Fast R-CNN이나 Faster R-CNN을 생각해 봤을 때 R-CNN의 문제점은 속도가 느리다는 것이다. 이미지당 region이 2000개인데, 이 각각을 cropping하고 CNN을 해야하니 2000번이나 CNN 연산이 필요한 것이다. 실제로 동시대에 나온, sliding-window 방식을 사용하는 OverFeat는 R-CNN보다 9배 빠르다고 한다.
이 논문을 보고 fine-tuning을 이렇게 하는거구나~하는 생각이 들었다. image classification(auxiliary task)은 data가 많고 object detection은 data가 적으니까 먼저 classification dataset으로 학습한 후 나중에 detection dataset으로 재조정하는 게 효과가 좋아서 신기했다.
