오늘의 논문 리뷰는 PixelCNN의 발전형인 PixelCNN++ 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] Autogressive Generative Model _ Pixel CNN++ & GLOW (Out Of Distribution(OOD) Detection With Computer Vision_Ver.3)
- Anomaly Detection 개요: [2] Out-of-distribution(OOD) Detection 문제 소개 및 핵심 논문 리뷰
Summary
PixelCNN은 tractable likelihood을 가진 강력한 generative model이다. 논문은 원본 PixelCNN에 몇 가지 수정을 가해 구조를 간단화하고 성능을 향상시킨다.
- 256-way softmax 대신 discretized logistic mixture likelihood을 사용해서 학습 속도를 높인다.
- R/G/B sub-pixels 대신 전체 pixel에 condition해서 모델 구조를 간단화한다.
- multiple resolutions에서 구조를 효과적으로 포착하기 위해 downsampling을 사용한다.
- 최적화 속도를 더 높이기 위해 추가적인 short-cut connection을 도입한다.
- dropout을 이용해서 모델을 regularize한다.
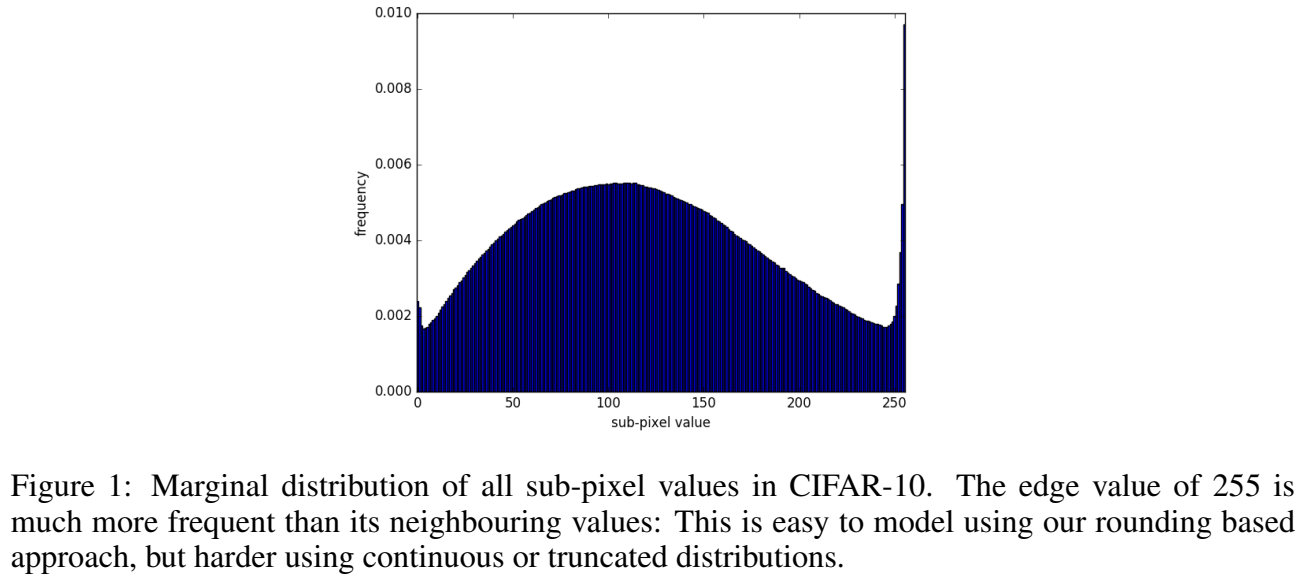
CIFAR-10에서 SOTA log likelihood 결과를 보여 효과를 입증한다.
이제 각 수정에 대해 알아보자.
- DISCRETIZED LOGISTIC MIXTURE LIKELIHOOD
일반적인 PixelCNN은 sub-pixel/color channel의 conditional distribution을 full 256-way softmax로 명시한다. 이는 모델에 큰 유연성을 주지만 memory 부담이 크다. 또 이는 (특히 학습 초기에) network parameters에 관해 gradients를 아주 sparse하게 만들 수 있다. standard parameterization를 가지고는 모델은 128이란 값이 127나 129와 가깝다는 걸 모르며, higher level structures로 가기 전에 이 관계가 먼저 학습되어야 한다. 극단적인 예시로 특정 sub-pixel value가 한 번도 관측되지 않았다면 모델은 zero probability를 할당하도록 학습될 것이다. (예측을 연속적인 게 아니라 softmax로 해서 문제가 생기는 것) high precision values가 관찰되는 극단적인 경우엔 현재 구조로는 PixelCNN은 엄두도 못 낼 정도의 메모리와 연산을 필요로 한다.
따라서 논문은 observed discretized pixel values의 conditional probability를 계산하는 다른 메커니즘을 제안한다. VAE처럼 continuous distribution를 가진 latent color intensity ν가 있다고 가정한다. 다음 이는 observed sub-pixel value x를 주기 위해 nearest 8-bit representation로 round된다. ν를 modeling하는 simple continuous distribution을 고름으로써(예컨대 VAE처럼 logistic distribution) x를 위한 smooth, memory efficient predictive distribution을 얻는다. 여기서 논문은 continuous univariate distribution을 logistic distributions의 mixture로 골라 observed discretized value x에 probability를 쉽게 계산한다. edge cases 0과 255를 제외하고 모든 sub-pixel values x에 대해 다음과 같다.
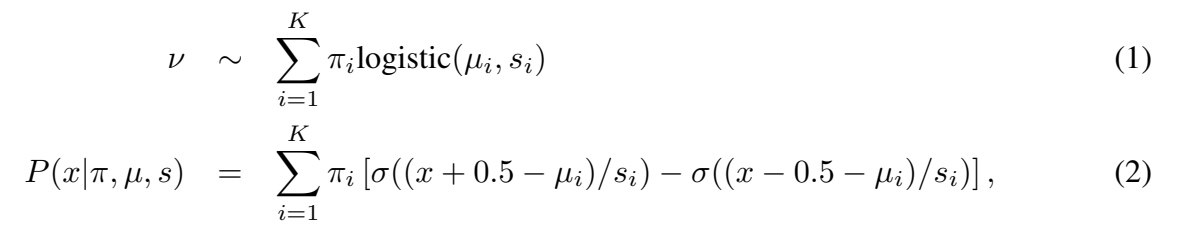
σ()는 logistic sigmoid function이다. edge case 0의 경우 x-0.5를 으로 대체하고 255의 경우 x+0.5를 으로 교체한다.
논문의 방식은 continuous mixture models을 사용하는 기존 연구들을 따르지만 rounding of ν to x을 명시적으로 모델링하여 probability mass를 [0,255]라는 유효한 범위 밖의 값에 할당하는 것을 피한다. 추가로 edge value인 0/255에 neighboring values보다 더 높은 probability를 자연스럽게 부가하는데 이는 Fig 1처럼 observed data distribution와 잘 일치한다. 실험을 통해 픽셀의 conditional distributions을 정확히 modeling하기 위해 상대적으로 적은 숫자의 mixture components가 필요하다는 것을 알아냈다. 따라서 network의 output은 더 작은 dimension이고 denser gradients를 만든다. 실험에서 이는 optimization 중에 (특히 학습 초기에) 수렴 속도를 크게 올렸다.
- CONDITIONING ON WHOLE PIXELS
원본 PixelCNN은 RGB 3 sub-pixels에 generative model를 factorize한다. 이는 general dependency structure을 허용하지만 모델을 복잡하게 한다. 따라서 논문은 이미지 내 위쪽과 왼쪽 전체 pixel에 condition해서 predicted pixel의 모든 3 color channels에 걸쳐(over) joint predictive distributions을 output한다. pixel 자신에 대한 predictive distribution은 simple factorized model로 해석될 수 있다. 먼저 (앞서 설명한) discretized mixture of logistics을 사용해 red channel을 예측한다. 다음으로 같은 형태의 predictive distribution를 사용해 green channel을 예측한다. 여기서 우리는 red sub-pixel의 값에 linearly depend하기 위해 mixture components의 means를 허용한다. 마지막으로 같은 방식으로 blue channel을 model하고, red와 green channels에만 linear dependency를 허용한다. 따라서 이미지 내 location (i, j)의 pixel 에 대해 context 에 mixture indicator와 previous pixels로 구성된 distribution conditional은 다음과 같다.
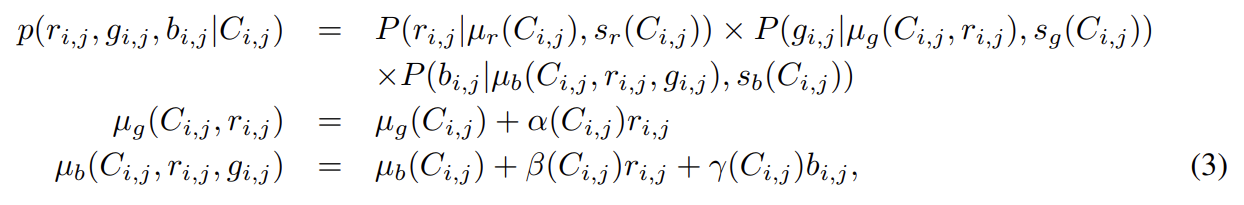
α, β, γ scalar coefficients은 mixture component와 previous pixels에 기반한다.
mixture indicator은 모든 3 channels에 걸쳐 공유된다. 먼저 pixel에 대한 mixture indicator을 sample하고 그 다음 상응하는 mixture component에서 color channel을 차례대로 sample한다.
- DOWNSAMPLING VERSUS DILATED CONVOLUTION
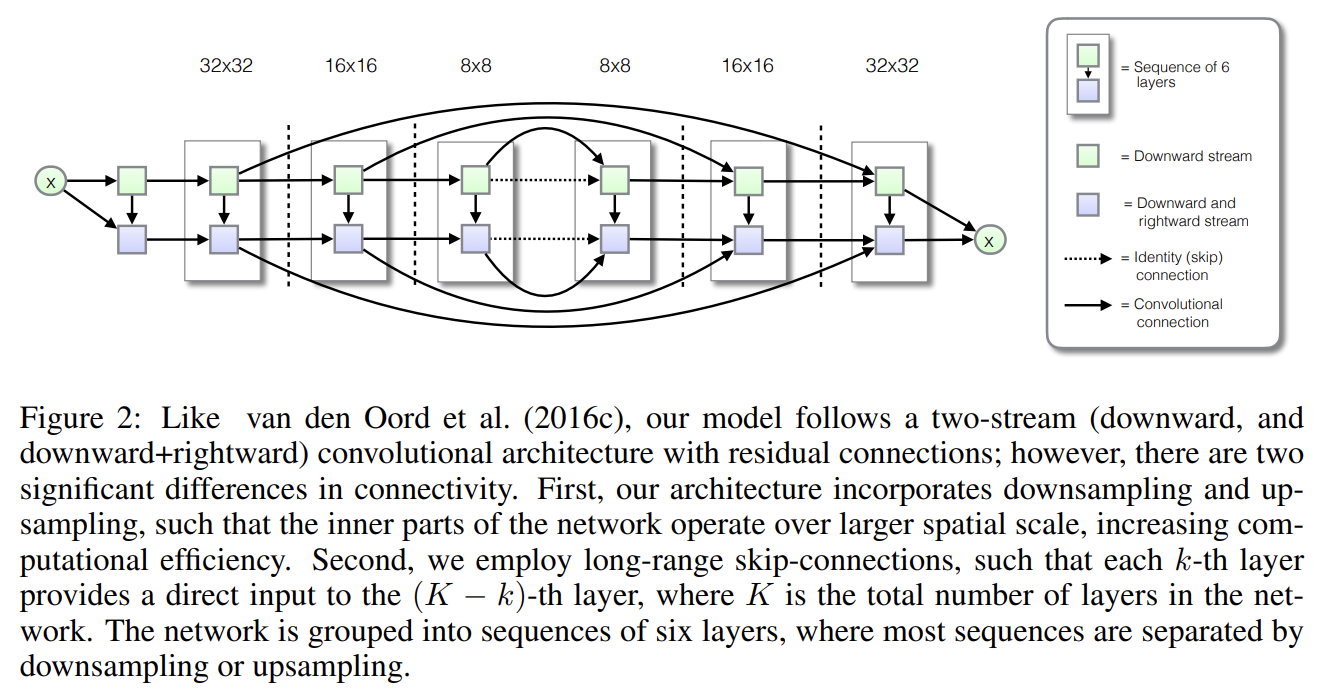
PixelCNN은 small receptive field을 가진 convolution만 사용한다. 이런 convolution은 local dependencies을 포착하는 데는 좋지만, long range structure를 modeling할 때는 그렇지 않다. Tab 2를 보면 short range dependencies만 포착해도 자주 좋은 log-likelihood scores를 획득하지만 모델이 long range dependencies를 포착하도록 명시적으로 격려하면 생성된 이미지의 perceptual quality을 향상시킬 수 있다(Fig 3과 Fig 5를 비교). multiple resolutions에의 구조를 model하도록 허용하는 한 가지 방법은 모델에 dilated convolutions를 도입하는 것이다. 논문은 대신 stride 2 convolution을 사용함으로써 downsampling을 사용할 것을 제안한다. downsampling은 dilated convolutions가 감당하는 것과 동일한 multi-resolution processing을 감소된 연산량으로 달성한다. dilated convolutions은 (zero padding으로 인해) input 크기가 증가하지만 donwsampling은 (2차원에 stride 2라서) input size를 4배로 감소시키기 때문이다. downsampling의 단점은 정보 손실이지만 곧 설명할 additional short-cut connections를 도입하여 이를 보상할 수 있다. additional short-cut connections를 통해 downsampling의 성능이 dilated convolution와 동일함을 발견했다.
- ADDING SHORT-CUT CONNECTIONS
size 32 × 32 input에 대해 PixelCNN++은 5 ResNet layers의 6 blocks으로 구성된다. first, second block 사이와 second, third block 사이에 strided convolution으로 subsampling을 수행한다. fourth, fifth block 사이와 fifth, sixth block 사이에 transposed strided convolution으로 upsampling을 수행한다. 이 subsampling과 upsampling process은 정보를 잃으므로 정보를 복원하기 위해 lower layers에서 additional short-cut connections을 도입한다. short-cut connection은 first block의 ResNet layers에서 sixth block의 상응하는 layers로 연결되고 비슷한 방식으로 2, 5 block 사이와 3, 4 block 사이에 연결된다. 이는 VAE, U-net 모델과 비슷하다.
- REGULARIZATION USING DROPOUT
PixelCNN은 overfit될 정도로 충분히 강력하다. 또 training images을 재생산할뿐 아니라 overfitted model은 Fig 8처럼 low perceptual quality의 이미지를 생성한다. 네트워크를 regularize하는 한 가지 효과적인 방법은 dropout이다. PixelCNN++의 first convolution 이후 residual path에 standard binary dropout을 적용한다. dropout의 사용은 high capacity models을 성공적으로 학습시키면서 overfitting을 피하고 high quality 이미지를 생성하게 해준다(Fig 8과 Fig 3 비교)
실험은 CIFAR-10 data set에 진행하고 log-likelihood에서 SOTA를 달성한다.

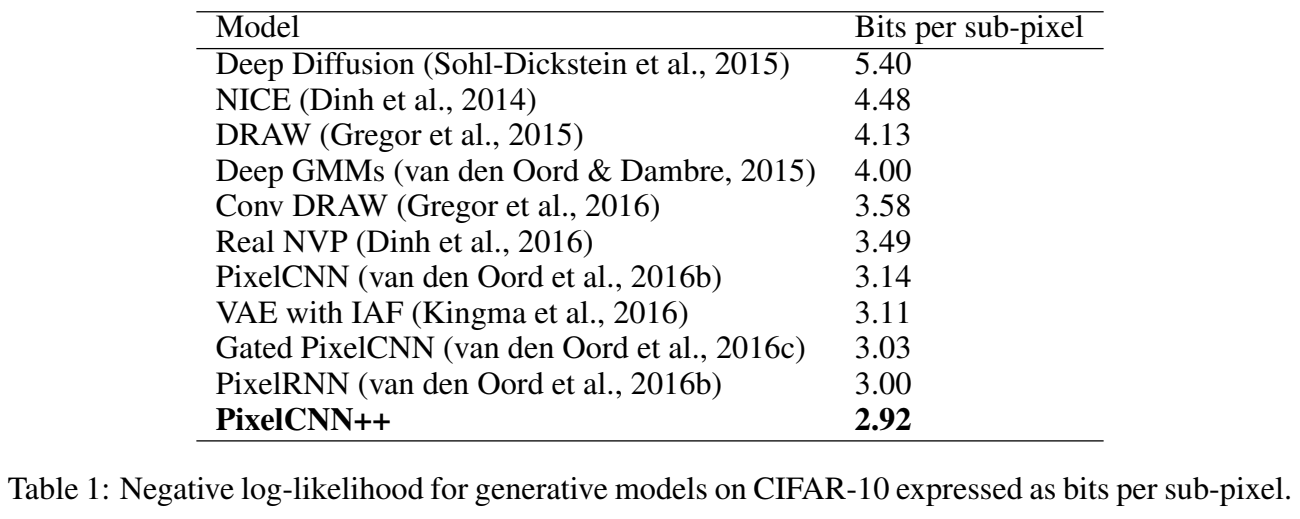
PixelCNN++을 generative modeling에 적용한다. encoding part에 대해서는 5 residual layers 사이 2 × 2 downsampling를 가진 3 Resnet blocks을 사용한다. decoding part에도 동일한 architecture을 사용하되 block 사이 downsampling 대신 upsampling을 한다. 모든 residual layers은 192 feature maps와 0.5 dropout을 사용한다. Tab 1은 SOTA test log-likelihood을 보여준다.

다음으로 van den Oord et al. (2016c) (gated/conditional PixelCNN 논문)을 따라 CIFAR-10의 class label에 conditional하게 generative model을 만든다. 이는 class label의 one-hot encoding을 network 내 각 convolutional unit에 대해 separate class-dependent bias vector로 linearly project함으로써 이루어진다. 모델을 class-conditional하게 만드는 것이 overfitting을 피하기 더 어려웠다.
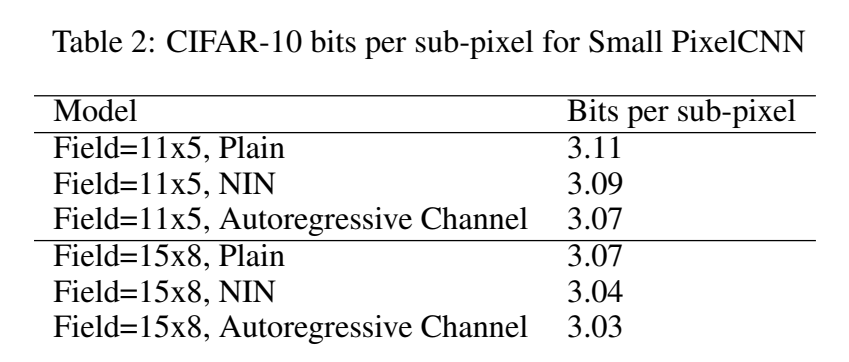

앞선 gated PixelCNN 논문에서 receptive field 크기와 receptive field 사각지대의 제거가 PixelCNN 성능에 중요하다고 증명되었다. 여기서 논문은 충분한 capacity만 있다면 작은 receptive field를 가진 PixelCNN도 경쟁적인 generative modeling 성능을 가질 수 있음을 보인다. receptive field 크기를 제한하기 위해 downsampling blocks을 없애고 layer 수를 줄여서 PixelCNN++ 모델을 실험한다. 두 receptive field size 11x5와 15x8를 실험한다.
receptive field의 크기를 제한함으로써 네트워크의 capacity도 상당히 떨어지는데 일반적인 PixelCNN보다 많이 적은 layers를 가지기 때문이다. 단순히 depth를 제한한 PixelCNN을 “Plain” Small PixelCNN이라고 부르겠다. 흥미롭게도 이는 blind spot을 가진 원래 PixelCNN보다 성능이 좋았다. capacity를 늘리기 위해 receptive field를 늘리지 않고 Small PixelCNN를 더 expressive하게 만드는 두 간단한 변형을 소개한다.

Tab 2가 보여주듯 두 방법 모두 capacity를 늘려 log-likelihood를 향상시킨다. 작은 receptive field를 가진 모델이 인상적인 likelihood score을 달성하지만 Fig 5에서 볼 수 있듯 global structure은 부족하다.
PixelCNN에 적용한 수정사항의 효과를 알기 위해 ablation study도 한다.
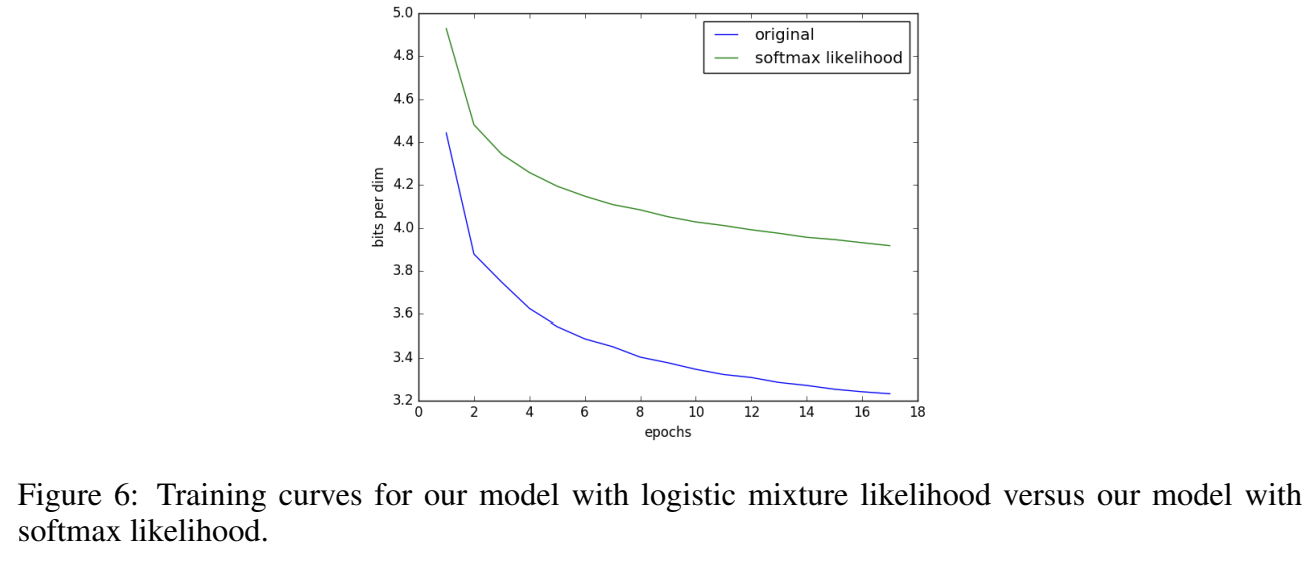
logistic mixture likelihood의 기여를 확인하기 위해 256-way softmax를 output distribution으로 설정해 CIFAR-10에 실험한다.
(중략)
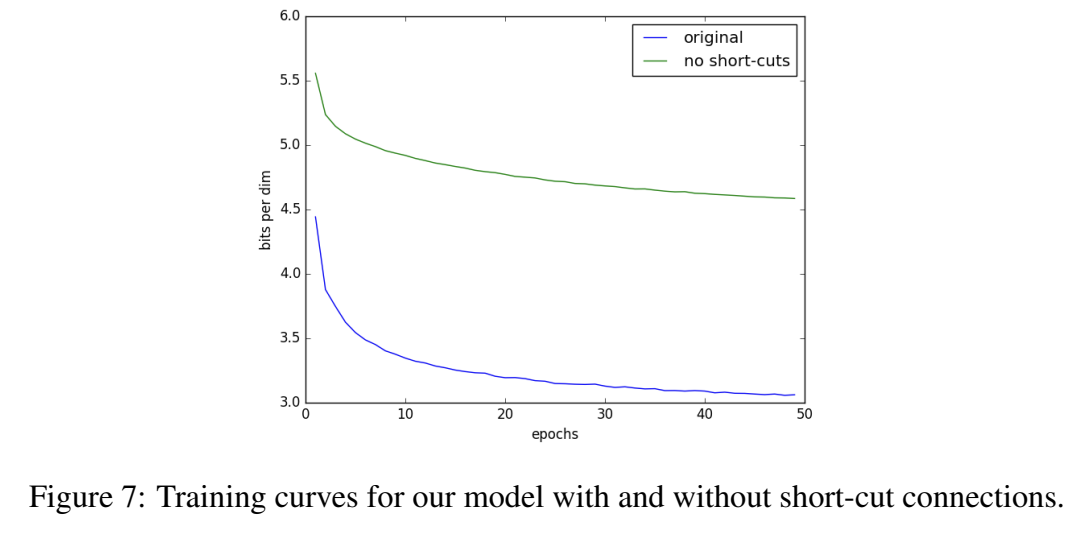
short-cut connections 없이도 실험한다.

dropout regularization 없이 실험한다.
Strengths
- downsampling으로 다양한 크기의 구조를 포착하면서 연산 부담을 줄였고 short-cut connection으로 정보 손실을 보상했다.
- 전체 pixel에 condition해서 PixelCNN의 복잡한 architecture을 완화했다.
Weaknesses
- 256-way softmax 대신 discretized logistic mixture likelihood를 써서 denser gradient를 만들고 수렴 속도를 높였는데, 이는 PixelCNN++ 모델에 특수한 것일 수도 있다고 저자는 지적한다. (뉘앙스로 보아 아마 원본 PixelCNN에 이걸 적용해봤는데 성능이 떨어진 것 같다)
