오늘 리뷰할 논문은 LXMERT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- LXMERT Review
- ViLBERT & LXMERT
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Summary
vision과 language의 alignment를 학습하기 위해 LXMERT
(Learning Cross-Modality Encoder Representations from Transformers) framework을 제안한다. LXMERT에서는 3가지 encoder, 즉 encoders: object relationship encoder, language encoder, cross-modality encoder로 구성된 large-scale Transformer model을 만든다. 그리고 대량의 image-and-sentence pairs를 가지고 5가지 representative pre-training tasks, 즉 masked language modeling, masked object prediction (RoI-feature regression and label classification), cross-modality matching, image question answering을 통해 학습한다. BERT의 MLM처럼 single-modality pre-training과 달리 같은 modality에서 visible elements나 다른 modality에서 aligned components을 볼 수 있으므로 이 task들은 intra-modality와 cross-modality relationships 둘 다를 학습하는 데 도움을 준다. fine-tuning 후 LXMERT는 2개의 visual question answering datasets, 즉 VQA와 GQA에 SOTA를 달성한다. 또 challenging visual-reasoning task인 NLVR2에 모델을 적용해서 기존 정확도를 22%p 향상시킨다.
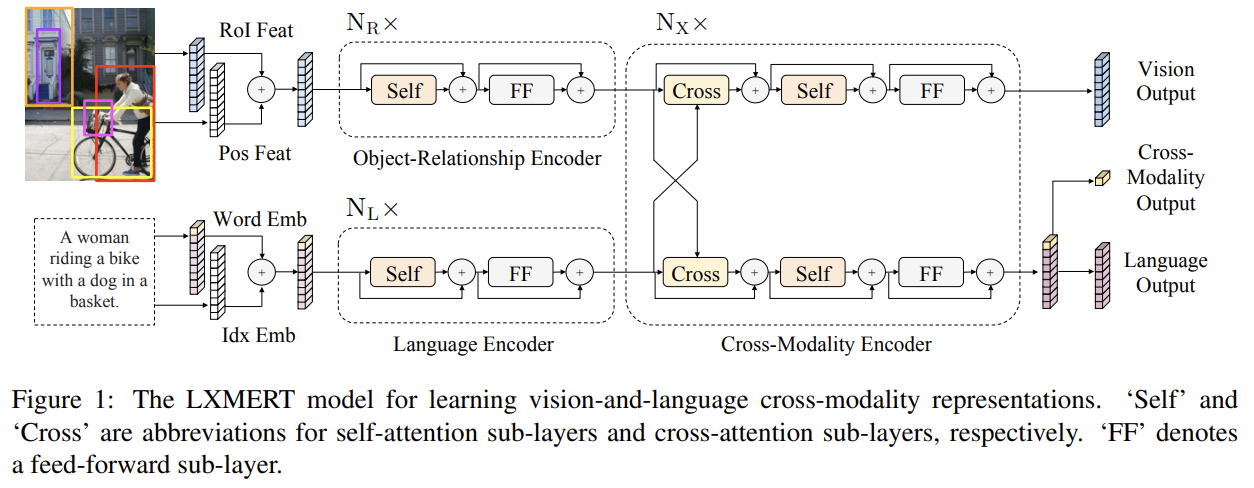
모델은 image와 realted sentence를 input으로 받는다. 각 image는 sequence of objects로 표현되고 각 sentence는 sequence of words로 표현된다. self-attention과 cross-attention layers의 조합을 통해 모델은 language representations, image representations, cross-modality representations을 생성할 수 있다.
LXMERT 내 input embedding layers는 input을(image와 sentence) 2 sequnce of features, 즉 word-level sentence embeddings와 object-level image embeddings로 전환한다. 이 embedding features는 이후 latter encoding layers에 의해 처리된다.
- Word-Level Sentence Embeddings
먼저 WordPiece tokenizer를 사용해 문장이 길이 n의 words {w1, . . . , wn}로 분할된다. 그 다음 word w_i와 그것의 index i (sentence 내에서 w_i의 absolute position)가 embedding sub-layers로 인해 vectors에 project되고 index-aware word embeddings에 더해진다.

- Object-Level Image Embeddings
CNN의 feature map output을 사용하는 대신 Anderson et al. (2018)을 따라 features of detected objects를 image의 embeddings로 사용한다. 구체적으로 object detector가 image에서 m objects {o1, . . . , om}를 감지하면(image에서 bounding boxes로 표기됨) 각 object o_j는 position feature (즉 bounding box coordinates) p_j와 그것의 2048-dimensional region-of-interest (RoI) feature f_j로 표현된다. Anderson et al.에서 position pj을 고려하지 않고 직접 RoI feature f_j을 사용하는 것과 달리 2 fully-connected layers의 output을 합하는 것으로 position-aware embedding v_j을 학습한다.
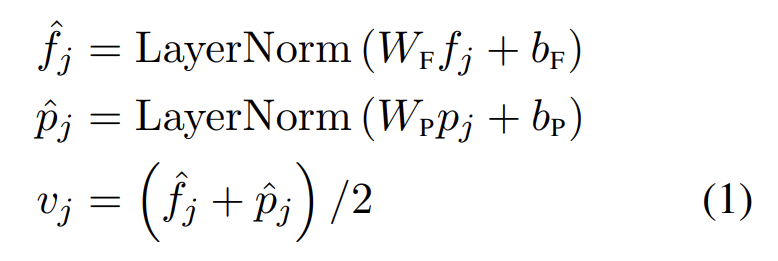
visual reasoning에 spatial information뿐 아니라 positional information을 포함하는 것은 masked object prediction pre-training task에 필수적이다. image embedding layer와 뒤따르는 attention layers가 inputs의 absolute indices에 무관하기(agnostic) 때문에 object의 순서는 특정되지 않는다. 마지막으로 식 (1)에서 layer normalization은 서로 다른 두 종류 features의 energy를 balance하기 위해 summation 전에 projected features에 적용된다.
- Single-Modality Encoders
embedding layers 이후에 먼저 2가지 transformer encoders, 즉 language encoder와 object-relationship encoder를 적용하고 각각은 single modality(language나 vision)에 집중한다. single-modality encoder 내의 각 layer은 self-attention (‘Self’)
sub-layer와 feed-forward (‘FF’) sub-layer을 포함하며 feed-forward sub-layer은 2 fully-connected sub-layers로 구성된다. language encoder와 object-relationship encoder는 각각 과 개의 layers를 가진다. (Attention is all you need 논문처럼) 각 sub-layer 이후 residual connection과 layer normalization을 추가한다.
- Cross-Modality Encoder
cross-modality encoder 내의 각 cross-modality layer는 2 self-attention sub-layers, 1 bi-directional cross-attention sublayer와 2 feed-forward sub-layers로 구성된다. 이 cross-modality layers를 개 stack한다(즉, k층의 output을 k+1층의 input으로 사용). k-th layer에서 bi-directional cross-attention sub-layer (‘Cross’)가 먼저 적용된다. 이는 2 uni-directional cross-attention sub-layers로 구성되는데 하나는 language에서 vision으로 가는 것이고 다른 하나는 vision에서 language로 가는 것이다. query와 context vectors는 (k-1)-th layer의 output이다(즉 language features 와 vision features ).
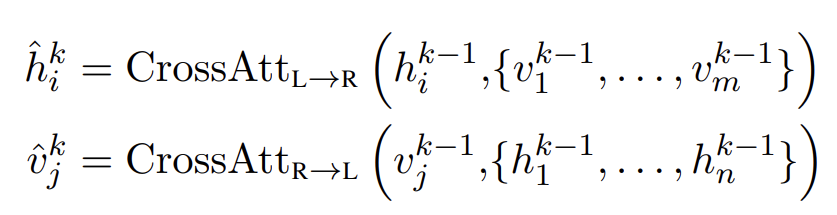
마지막으로 k-th layer output 와 는 and 꼭대기의 feed-forward sub-layers (‘FF’)에 의해 생성된다. 또 single-modality encoders와 유사하게 각 sub-layer 이후 residual connection과 layer normalization을 추가한다.
Fig 1 우측 끝처럼 LXMERT cross-modality model은 3가지 output, 즉 language, vision, cross-modality를 가진다. language와 vision outputs은 cross-modality encoder로 생성된 feature sequences다. cross-modality output의 경우 BERT 논문처럼 sentence words 전에 special token [CLS]을 추가해서(Fig 1의 bottom branch에서 꼭대기 노란색 블럭으로 표기됨) language feature sequences 내에서 이 special token에 상응하는 feature vector가 cross-modality output으로 사용된다.
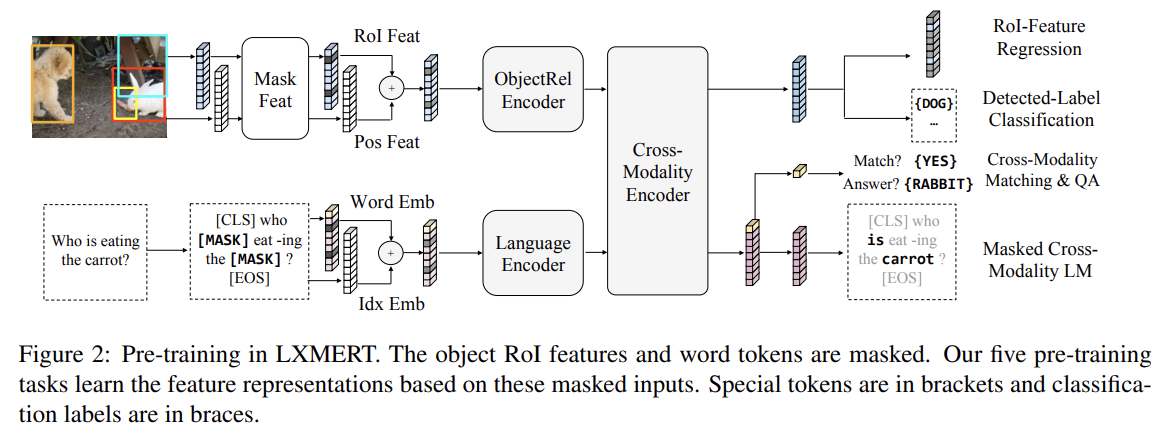
- Language Task: Masked Cross-Modality LM
Fig 2의 bottom branch에서 볼 수 있듯 BERT와 비슷하다. words는 15% 확률로 랜덤하게 mask되고 모델은 masked words를 예측해야 한다. language modality의 non-masked words에 추가로 vision modality에서도 masked words를 예측할 수 있다. 이런 BERT와의 차이를 강조하기 위해 이 task를 masked cross-modality LM라고 부른다.
- Vision Task: Masked Object Prediction
Fig 2의 top branch에서 볼 수 있듯 15% 확률로 랜덤하게 objects를 mask하고(즉 RoI features를 0으로 mask함) 모델이 masked objects의 properties를 예측하게 함으로써 vision을 pretrain한다. language task과 비슷하게 모델은 visible objects나 language modality에서 masked objects를 추론할 수 있다. vision side에서 object를 추론하는 것은 object relationships을 학습하게 돕고 language side에서 추론하는 것은 cross-modality alignments를 학습하게 돕는다. 따라서 2가지 sub-tasks를 수행한다. RoI-Feature Regression은 L2 loss를 가지고 object RoI feature fj를 regress하고 Detected-Label Classification은 cross-entropy loss를 가지고 masked objects의 labels을 예측한다. Detected-Label Classification sub-task에선 (대부분의 pre-training images가 object-level annotations을 가지지만) annotated objects의 ground truth labels는 서로 다른 datasets에서 일관적이지 않다(예를 들어 label classes의 숫자가 다르다던지). 이런 이유로 Faster R-CNN을 사용해 detected labels output을 얻는다. 비록 detected labels이 noisy하지만, 실험 결과 이 labels이 pre-training에 기여함이 드러난다.
- Cross-Modality Tasks
Fig 2의 중앙-오른쪽 끝에서 볼 수 있듯 strong cross-modality representation을 학습하기 위해 language와 vision modalities 둘 다를 명시적으로 필요로 하는 2 tasks를 가지고 모델을 pre-train한다.
- Cross-Modality Matching
각 sentence를 50% 확률로 mismatched sentence로 대체한다. 그 다음 classifier가 image와 sentence가 서로 match하는지 예측하도록 훈련시킨다. 이는 BERT의 NSP와 비슷하다.
- Image Question Answering (QA)
pre-training dataset을 확대하기(enlarge) 위해 pre-training data에 1/3 sentences는 images에 대한 questions이다. image와 question이 match할 때(즉, cross-modality matching task로 랜덤하게 대체되지 않았을 때) 이 image-related questions에 대한 정답을 예측하도록 모델을 학습시킨다.
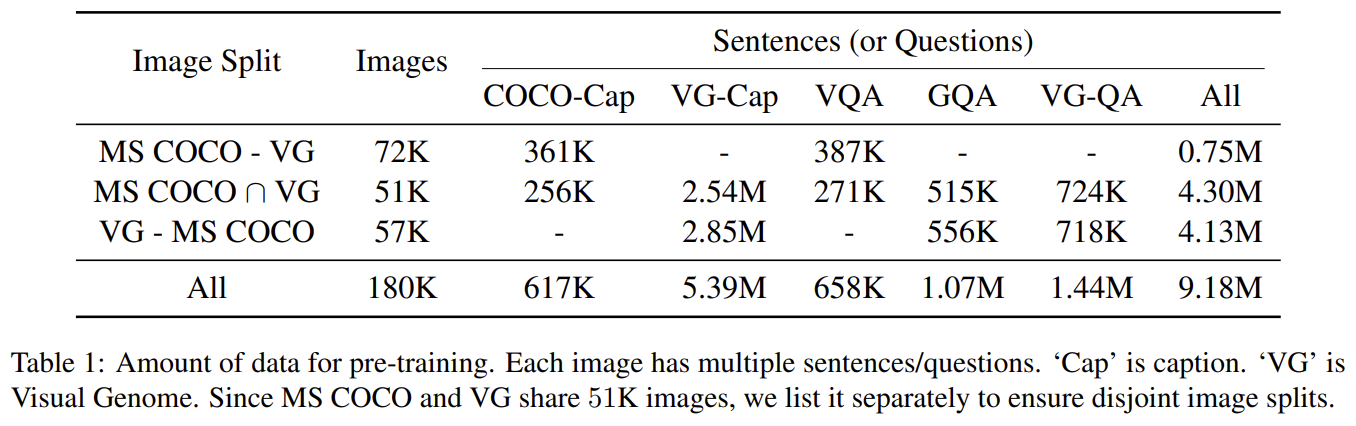
Tab 1에서 볼 수 있듯 5가지 vision-and-language datasets을 종합한다. 이들의 image는 MS COCO (Lin et al., 2014)와 Visual Genome (Krishna et al., 2017)에서 온다. 2 original captioning datasets에 추가로 3가지 large image question answering (image QA) datasets인 VQA v2.0 (Antol et al., 2015), GQA balanced version (Hudson and Manning, 2019), VG-QA (Zhu et al., 2016)를 종합한다. pre-training 시 test data를 보는 것을 피하기 위해 train과 dev splits만 수집한다. aligned image-and-sentence pairs을 생성하기 위해 5 datasets에 최소한의 pre-processing만 수행한다. 각 image question answering dataset에 대해 image-and-sentence data pairs에서의 sentence를 questions로 받고 image QA pre-training task에서 labels를 answers로 받는다.
Faster R-CNN detector는 Anderson et al. (2018)의 Visual Genome 데이터셋으로 pre-train됐고 fine-tune하지 않으며 feature extractor로서 freeze한다. variable numbers of objects를 감지하는 Anderson et al. (2018)와 달리 pre-training compute utilization을 최대화하기 위해 padding을 피함으로써 각 image에 대해 36 objects를 일관적으로 유지한다. model architecture로 NL, NX,
NR은 각각 9, 5, 5로 설정했다. 101-layer Faster R-CNN에서 추출한 visual features와 balance하기 위해 language encoder에 더 많은 layers가 사용됐다. hidden size 768은 와 동일하다. encoders와 embedding layers 내의 모든 parameters를 밑바닥부터 pre-train한다(model parameters가 랜덤하게 초기화되거나 0으로 설정된다). LXMERT는 여러 pre-training tasks로 pre-train되며 이 loss들을 동일한 weight으로 더한다. image QA pre-training tasks의 경우 모든 세 image QA datasets 내 questions의 90%를 아우르는 9500 answer candidates를 가진 joint answer table을 생성한다.
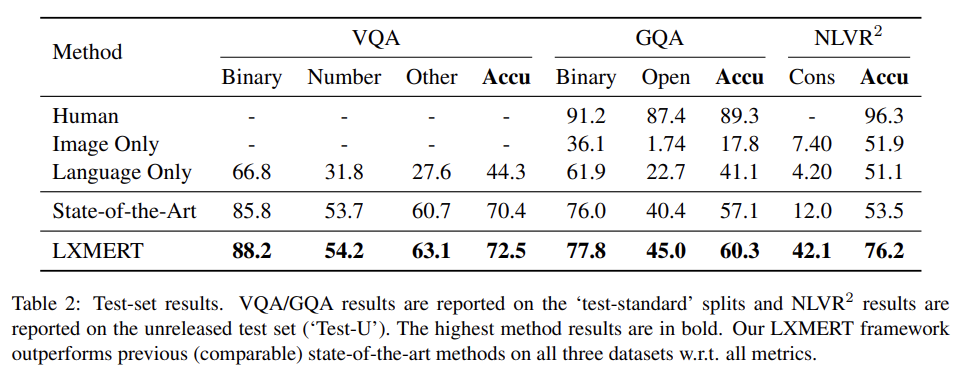
3가지 데이터셋 VQA v2.0 dataset (Goyal et al., 2017), GQA (Hudson and Manning, 2019), NLVR2으로 모델을 평가한다. 설명은 생략한다.
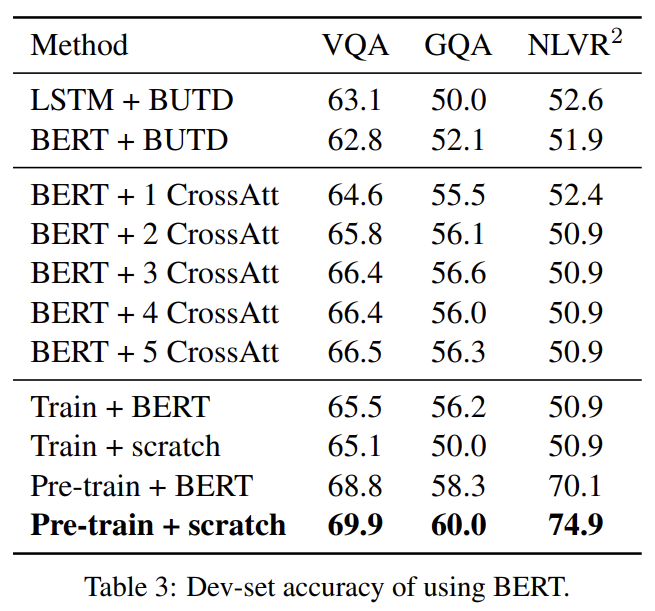
BERT_BASE pre-trained model을 통합하는 여러 방법을 실험해 LXMERT와 비교한다. 설명은 생략한다.
흥미로운 점은 LXMERT를 BERT의 parameter로 초기화한 후 pre-training했을 때 맨땅에서 한 것보다 pre-training loss가 더 컸다. 이는 BERT가 이미 single-modality masked language model로 pre-train되서 vision modality와의 연결 없이 language modality에만 기반할 때 잘 작동하기 때문으로 추측된다.
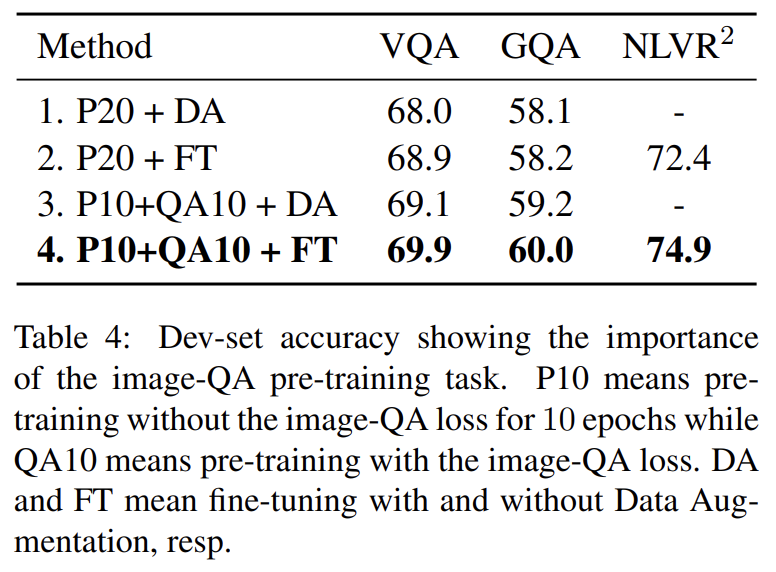
image QA pre-training task의 중요성을 알기 위한 실험도 한다. 설명은 생략한다.
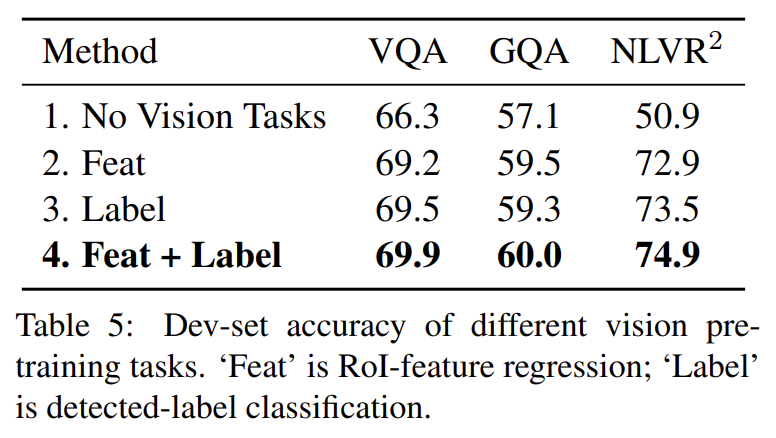
여러 vision pre-training tasks의 효과도 분석한다. 설명은 생략한다.
Strenghts
- 3가지 encoder를 사용해 language와 vision을 각각 encode하고 cross-modality enocder로 종합했다.
Weaknesses
- UNITER처럼 Masked Object Prediction을 위해 Faster R-CNN을 사용해 label을 정해서 불가피하게 noisy하다.
- UNITER 논문에서 지적했듯 QA로 pre-train해서 downstream VQA, GQA에 적합한 것일 수 있다.
BERT parameter로 초기화했을 때 오히려 결과가 안 좋은 게 신기했다.
사실 pre-training이나 기법이 다른 논문들과 비슷비슷하다 보니 특별한 strengths는 못 찾겠다.
