오늘 리뷰할 논문은 WGAN을 보완한 WGAN-GP 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
GANs는 강력한 generative model이지만 training instability에 시달린다. WGAN은 stable training에 성취를 이루었지만 여전히 poor samples만을 생성하거나 수렴에 실패한다. 논문은 WGAN에서 critic에 Lipschitz constraint를 강제하는 weight clipping의 사용이 이런 문제의 원인이라고 본다. 그래서 논문은 weight clipping의 대안으로 input에 관해서 critic의 norm of gradient을 penalize하는 방법을 제안한다. 이 방식은 WGAN보다 성능도 좋고 hyperparameter tuning 없이 많은 GAN architecture의 stable training을 가능하게 한다.
WGAN은 weight clipping을 통해 discriminator(=critic)이 1-Lipschitz functions 공간 내에 있을 것을 강제한다.
논문의 기여는 다음과 같다.
1. toy datasets을 사용해 critic weight clipping이 (GAN에) 원하지 않는 행동을 야기한다는 것을 입증한다.
2. 위의 문제를 발생하지 않는 gradient penalty (WGAN-GP)를 제안한다.
3. 다양한 GAN architectures의 stable training을 입증하고, weight clipping보다 향상된 성능,high-quality image generation, discrete sampling 없이 character-level GAN language model를 보여준다.

GAN의 value function은 위와 같다. generator parameter update 전에 discriminator을 optimality까지 학습했다면 위의 value function을 최소화하는 것은 과 사이 Jensen-Shannon divergence를 최소화하는 것과 같다. 하지만 이는 discriminator가 포화함(saturate)에 따라 종종 vanishing gradients 문제를 일으킨다.

WGAN 논문은 GAN이 최소화하는 divergence가 generator의 parameter에 관해 연속적이지 않아 training difficulty를 유발한다고 주장한다. 그래서 그들은 대신 distribution q에서 distribution p로 transform하기 위해 mass를 transport하는 데 드는 최소 비용으로 정의한 Earth-Mover distance (=Wasserstein-1) W(q, p)를 제안한다. 가벼운 가정 하에 W는 모든 위치에서 연속이고 거의 모든 위치에서 미분 가능하다.
WGAN value function은 Kantorovich-Rubinstein duality를 사용해 구축되었다. WGAN value function은 GAN보다 gradient가 더 잘 작동하는 critic function을 만들어 generator optimization이 더 쉽다.
WGAN은 critic에 Lipschitz constraint를 부여하기 위해 critic의 weights가 compact space [−c, c] 내에 있도록 weight clipping을 사용한다. 이 constraint를 만족하는 set of functions는 c와 critic architecture에 의존하는, 어떤 k에 대한 k-Lipschitz functions의 부분집합이다.
이 논문은 WGAN의 weight clipping이 optimization difficulties를 유발할 수 있으며 optimization이 성공하더라도 그 결과 critic이 pathological value surface를 가질 수 있음을 발견했다.
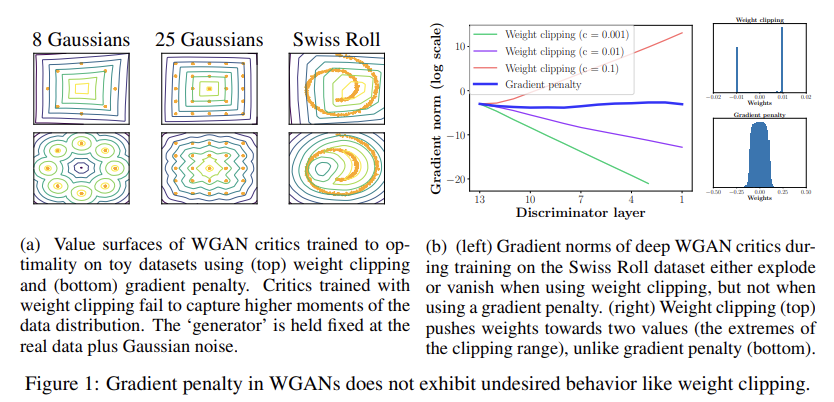
weight clipping을 통한 k-Lipshitz constraint의 구현은 critic을 매우 simpler functions로 편향시킨다. 이를 입증하기 위해 여러 toy distributions에 WGAN critics를 weight clipping으로 optimality까지 학습시킨다. Fig 1a는 value surfaces를 그려주며 각 경우에서 weight clipping으로 학습한 critic은 data distribution의 higher moments를 무시하고 대신 optimal functions의 아주 간단한 근사밖에 model하지 못함을 보여준다. 반면 논문의 방식(gradient penalty)는 그런 문제가 없다.
clipping threshold c의 조심스러운 tuning이 없으면 vanishing or exploding gradients를 야기해버리는 weight constraint과 cost function 사이 interaction 때문에 WGAN optimization process이 어렵다. Fig 1b의 실험을 통해 이 논문의 방식은 gradient가 stable함을 보여준다.

그래서 논문이 제안하는 Gradient penalty 방식이 대체 뭔지 알아보자. 논문은 Lipschitz constraint를 부여하는 대안을 제시한다. 도함수가 모든 위치에서 gradients with norm at most 1을 가질 때 1-Lipschtiz라고 한다. 그래서 논문은 (input에 대한) critic output의 gradient norm을 직접 제약한다. tractability issues를 우회하기 위해 에 대해 gradient norm에 penalty를 주어 constraint의 soft version을 부여한다. objective은 다음과 같다.
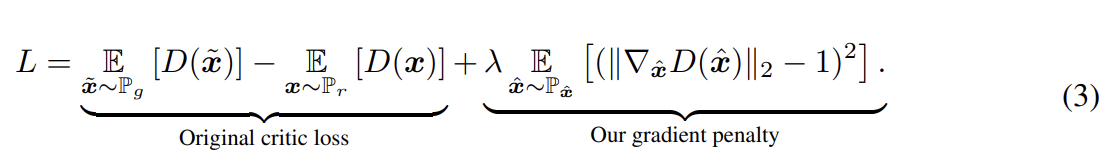
4가지 측면에서 자세히 알아보자.
- Sampling distribution
논문은 data distribution 과 generator distribution 에서 sample한 pairs of points 사이 직선을 따라 uniformly sampling하여 를 정의한다. 이는 (Proposition 1에서) optimal critic이 과 에서 온 coupled points를 연결하는, gradient norm 1을 가진 직선을 함유한다는 사실에서 영감을 받았다. 모든 위치에서 unit gradient norm constraint을 강제하는 것은 힘들기 때문에 대신 이 직선들 위에서만 강제하는 방식은 경험적으로 좋은 성능을 얻을 수 있었다.

- Penalty coefficient
논문의 모든 실험에서 λ = 10를 썼고 다양한 architecture과 dataset에서 잘 작동했다.
- No critic batch normalization
기존의 많은 GAN들은 stable training을 위해 generator과 discriminator 모두에 batch normalization을 적용했지만 BN은 discriminator의 문제 형태를 single input > single output mapping에서 entire batch of inputs > batch of output mapping으로 변질시킨다. 이 논문의 penalized training objective은 input 각각에 독립적으로 norm of the critic’s gradient을 penalize하기 때문에 batch 세팅이 유효하지 않다. 그래서 논문은 critic에서 BN을 제외하고, 그럼에도 모델이 잘 돌아감을 확인했다. WGAN-GP는 example 간 상관관계가 없는 normalization scheme(예컨대 layer normalization)과는 호환된다.
- Two-sided penalty
논문은 norm of the gradient이 1 미만이 되도록 하는 게 아니라(one-sided penalty) 1을 향해 가도록(two-sided penalty) 격려한다.

LSUN bedrooms dataset에 대해 다양한 GAN architecture을 실험했다. Fig 2는 WGAN-GP만이 세팅에서 unstable하거나 mode collapse을 겪지 않음을 보여준다. (물론 WGAN-GP로 그런 문제가 100프로 안 일어난다는 장담은 못하지만) 이는 very deep residual networks가 GAN setting으로 성공적으로 학습된 최초의 사례다.
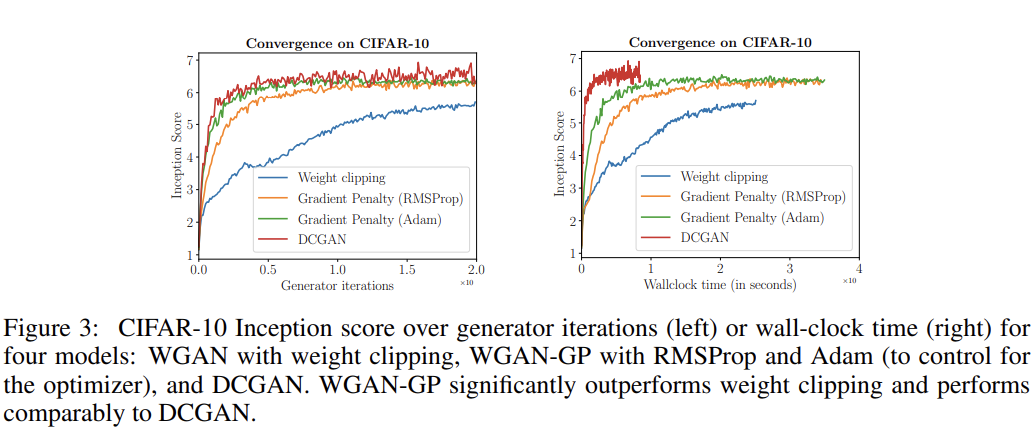
weight clipping에 비해 gradient penalty 방법의 장점은 향상된 training speed와 sample quality다. 이를 입증하고자 CIFAR-10 dataset에 WGAN을 weight clipping과 gradient penalty를 사용해 Inception scores를 각각 plot했다. Fig 3을 보면 gradient penalty가 weight clipping보다 더 빠르게 더 정확한 score로 수렴함을 볼 수 있다. DCGAN보다는 수렴이 느렸지만 대신 convergence에서 score이 더 stable하다.

논문의 방법이 degenerate distributions을 model하는 능력이 있음을 입증하고자 continuous space에 정의된 generator을 가진 GAN으로 complex discrete distribution을 modeling하는 문제를 고려한다. Google Billion Word dataset에 character-level GAN language model을 학습했고 결과 샘플들은 Table 4와 같다. spelling errors를 만들긴 하지만 그럼에도 언어의 statistics를 제법 학습한 모습을 보여준다.
(자세한 내용 생략)
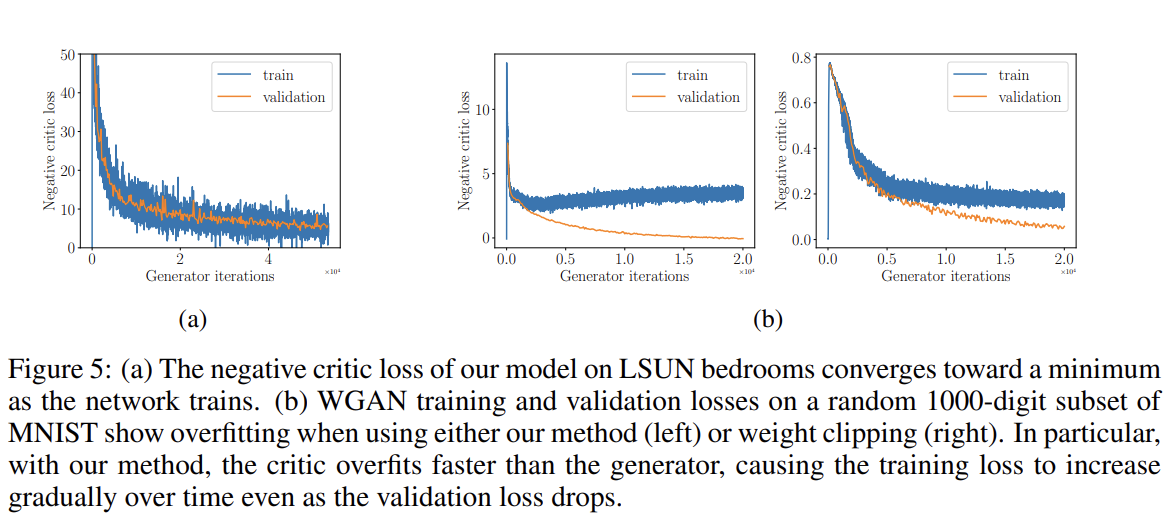
weight-clipped WGANs의 중요한 장점은 loss가 sample quality와 상관된다는 것과 loss가 minimum을 향해 converge한다는 것이다. Fig 5a는 WGAN-GP를 LSUN bedrooms dataset에 학습시켜 negative of the critic’s loss를 plot하여 그 성질이 유지됨을 보여준다.
또 (capacity는 충분히 큰데 training data가 부족하여) overfitting되는 경우에 loss curve의 행동을 탐구하고자 random 1000-image subset of MNIST에 large unregularized WGANs를 학습시켜 negative critic loss를 plot한다. Fig 5b는 WGAN과 WGAN-GP 모두 loss가 diverge하며 ciric이 overfitting되어 을 부정확하게 추정함을 알려준다. 하지만 WGAN과 달리 WGAN-GP는 validation loss가 감소함에도 training loss는 점진적으로 증가한다.
Strengths
- WGAN의 주요 장점인 loss curve의 특징을 보존하면서도 속도와 안정성이 더 좋다.
- (논문에 따르면) very deep residual networks가 GAN setting으로 성공적으로 학습된 최초의 사례다.
