
오늘 리뷰할 논문은 위의 Fig 1으로 유명한 pix2pix 논문이다. 앞서 리뷰한 U-Net과 conditional GAN을 이용했다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- Pix2Pix
- [논문리뷰/정리] Image-to-Image Translation with Conditional Adversarial Nets(pix2pix)
- [논문 리뷰] Pix2Pix: Image-to-Image Translation with CGAN
Summary
논문은 image-to-image translation 문제에 대한 범용적인 해결책으로 conditional adversarial networks를 제시한다. 전통적으론 각각의 문제에 대해 다른, 특별한/특정한 목적으로 설계된 loss function을 설계해야 했는데 이 논문은 그럴 필요가 없는 common framework를 만들고자 한다.
기존에는 이러한 목적에서 CNN을 통한 접근이 있었다. 이때 predicted pixel과 ground truth pixels 사이에 Euclidean distance(L2)를 최소화하려고 하면 blurry한 결과를 얻는다. 왜냐하면 Euclidean distance는 모든 plausible outputs을 평균내어 최소화되기 때문이다. 이는 우리의 목적인 sharp, realistic images output을 만드는 데 부적절하다.
그래서 논문은 대신 “make the output indistinguishable from reality”라는 high-level goal만 제시하면 알아서 적절한 loss function을 학습하는 GAN에 주목했다. GAN을 사용하면 blurry image는 명백히 fake로 보일 것이므로 blurry image가 생성되지 않을 것이다.
논문은 conditional GANs(cGANs)를 사용해 input image를 주고 상응하는 output image를 산출하고자 한다. 기존의 cGAN이나 GAN들과 달리 논문은 generator로는 "U-Net"-based architecture를, discriminator로는 (image patches 크기에서만 structure를 penalize하는) convolutional “PatchGAN” classifier를 사용한다.
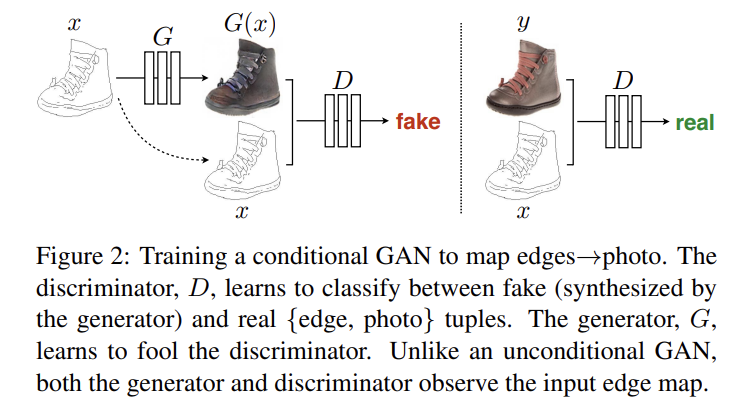
평범한 GANs이 noise z에서 output y를 만들어낸다면 cGANs는 observed image x와 noise z로 y를 만든다. cGANs의 objective는 다음과 같으며 G는 식 (1)을 최소화하려하고 D는 최대화하려한다.
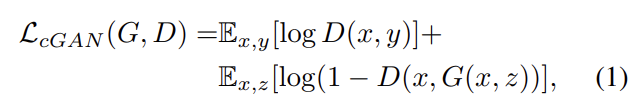
기존의 논문들은 GAN의 objective에 L2 같은 전통적인 loss를 섞는 게 더 좋다고 밝혔다. discriminator의 역할은 변함이 없지만 generator은 discriminator을 속일 뿐 아니라 ground truth output에서 (L2 거리의 관점에서) 가까워야 한다. 논문에선 L2보다 L1 거리를 사용하는 편이 덜 blurry한 결과를 내서 L1을 사용했다. 이를 고려한 최종적인 objective는 아래와 같다.
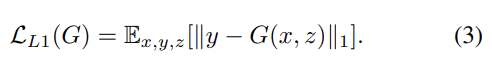
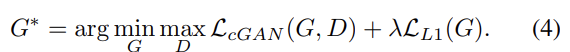
noise z를 사용하지 않고도 x에서 y로의 mapping을 학습할 수는 있겠지만 (기존의 논문들이 밝힌 바) 대신 deterministic outputs를 생성하게 되고 따라서 delta function을 제외하면 어떤 분포도 학습할 수 없을 것이다. 사실 이 논문의 초기 모델은 이 방식의 효과를 보지 못했는데, generator가 단순히 z를 무시하도록 학습됐기 때문이다. 그래서 최종 모델에선 training, testing 모두에서 몇 개 층에 noise를 dropout의 형태로 제공했다. dropout에도 불구하고 output은 minor stochasticity를 보인다(즉 다양한 결과가 나오는 게 아니라 약간 deterministic하다). 논문은 highly stochastic output을 생성하는 걸 future work로 남긴다.
논문은 generator architecture을 설계할 때 image-to-image problem이 high resolution input grid에서 high resolution output grid으로 mapping한다는 점, input과 output이 surface appearance는 다르지만 같은 underlying structure을 rendering한다는 점, 따라서 input의 structure가 output의 structure과 roughly align된다는 점에 주목했다.
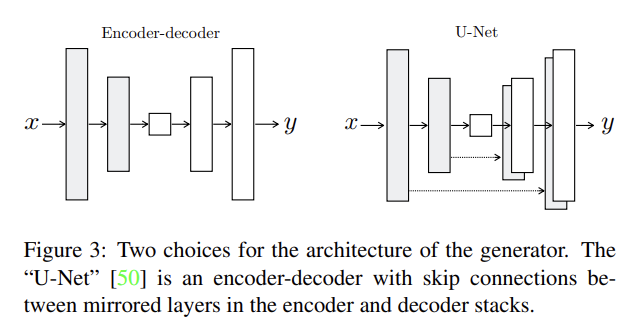
기존의 encoder-decoder 방식은 input이 점진적으로 downsample되다가 bottleneck layer를 지나고 다시 upsample이 된다. 이런 구조는 모든 정보가 bottleneck을 포함한 모든 층을 지나도록 요구한다. 하지만 많은 image translation 과제는 input과 output 사이 많은 low-level information을 공유하고 이런 정보가 직접적으로 전달되면 좋을 것이다. 예를 들어 image colorization 과제에선 input과 output이 prominent edges의 위치를 공유한다.
논문은 U-Net에서 착안해 정보가 bottleneck 구조를 피해갈 수 있는 skip connection을 추가한다. 총 layer 수가 n일 때 i번째 층과 n-i번째 층을 연결해주며 skip connection은 단순히 i번째 층의 모든 channel을 n-i번째 층의 channel과 concatenate한다.

Fig 4에서 볼 수 있듯이 L1이나 L2 loss는 blurry한 결과를 낸다. 이는 low frequencies는 잘 포착해도 high-frequency crispness를 잘 포착하지 못한다는 것이다. 그러니 low frequencies의 정확도를 잡기 위해 완전히 새로운 framework를 제시할 필요는 없고 식 (4)처럼 L1을 사용하면 된다. 따라서 discriminator는 high-frequency structure만 집중하면 되고, local image patches 내의 structure에만 attention을 제한하는 것으로 충분하다.
따라서 논문은 PatchGAN이라고 이름붙인 discriminator architecture를 고안한다. PatchGAN은 오직 patch의 scale에서만 structure을 penalize한다. image를 convolutionally하게 순회하면서 image 내의 각 N ×N patch가 real인지 fake인지 classify하고 모든 response를 평균 내서 D의 최종 output을 산출한다.
실험에서 논문은 N이 image의 전체 크기보다 훨씬 작아도 여전히 high quality 결과를 낸다는 것을 보인다. 작은 PatchGAN일수록 parameter가 적고 더 빠르고 arbitrarily large image에 적용될 수 있으므로 유리하다.
PatchGAN은 image를 Markov random field로써 model하며 patch diameter보다 더 떨어진 pixel은 서로 독립적이라고 추정한다. 또 PatchGAN은 일종의 texture/style loss의 형태로 생각할 수 있다.
optimize할 때 D, G를 하나의 gradient descent step씩 번갈아가며 업데이트한다. 그리고 original GAN 논문이 제안한 것처럼 G가 log(1 − D(x, G(x, z)) 항을 최소화하는 대신 log D(x, G(x, z)) 항을 최대화하도록 학습했다. 또 D를 optimize할 때는 objective를 2로 나눠서 (G에 상대적으로) D가 학습하는 속도를 늦췄다.
inference time에는 generator을 training phase와 동일하게 실행한다. test time에도 dropout을 사용한다는 점, training batch의 aggregated statistics가 아니라 test batch의 statistics를 batch normalization에 사용한다는 점에서 일반적인 protocol과 다르다.

cGANs의 범용성을 확인하고자 위와 같은 다양한 graphics task, vision task에 실험했다. 논문은 output을 평가하고자 2가지 방법을 사용한다. 첫째는 Amazon Mechanical Turk (AMT)을 실행해 (map generation, aerial photo generation, image colorization의) output의 real/fake 여부를 판단하는 것이다. 둘째로 off-the-shelf recognition system이 합성된 cityscapes 내의 object를 인식할 수 있는지 보는 것이다.
두번째 방식에 대해 좀 더 설명해보자면 pre-trained semantic classifier인, semantic segmentation로 유명한 FCN-8s architecture을 이용한다. 모델에게 cityscapes dataset을 학습시키고 생성된 사진이 원본 사진의 label과 같은지 classification accuracy를 측정해 그걸 FCN-score로 삼는다.
논문 식 (4)의 어떤 항이 중요한지 확인하고자 ablation study를 한다. Fig 4를 보면 L1만 사용하면 결과가 reasonable하지만 blurry하고 cGANs만 사용하면 sharp하지만 visual artifacts가 생기기도 한다. 두 항을 모두 사용하니 visual artifact가 줄어든다. cGANs 대신 (loss가 output이 realistic한지만 신경쓰고 input과 output의 mismatch를 penalize하지 않는) 일반적인 GANs를 사용해보기도 했는데 이 경우 input과 상관없이 항상 거의 똑같은 output을 생성하는, 좋지 않은 결과를 보였다.
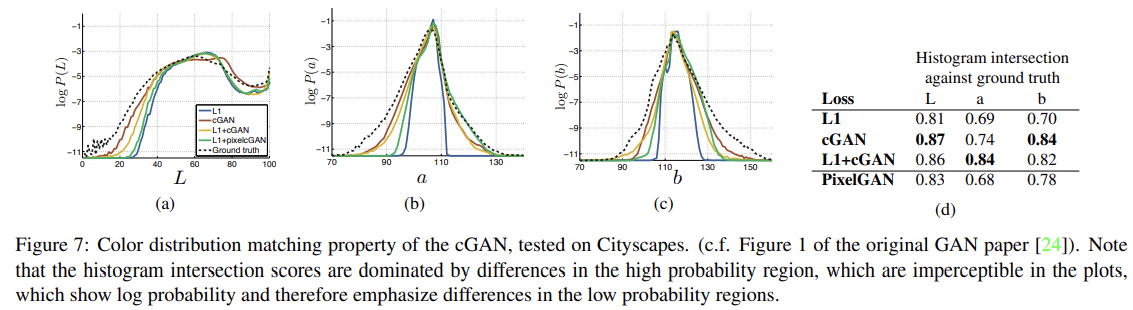
또 하나 특이한 점은 색의 분포에 관한 것이다. L1은 pixel이 취할 수 있는 여러 색이 있을 때 평균을 내서 grayish color를 선호한다. 가능한 color의 conditional probability density function에서 median을 고르는 것으로 L1이 최소화되기 때문이다. 한편 adversarial loss는 grayish color가 비현실적이라고 생각하기 때문에 true color distribution을 따르려고 한다. Fig 7을 보면 L1은 ground truth보다 더 narrower distribution을 가지고 cGAN은 ground truth에 가까운 걸 볼 수 있다.

U-Net의 효과를 보기 위해 skip connection만 제거한 encoder-decoder와 성능을 비교했더니 위와 같이 encoder-decoder가 덜 realistic한 차이가 났다. 이는 cGANs에 specific한 게 아닌데, cGANs 항을 제외하고 L1으로만 실험해도 U-Net이 encoder-decoder보다 더 좋았다.

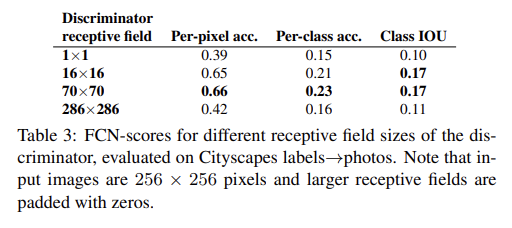
앞서 설명한 patchGAN의 N 크기에 따른 성능도 분석한다. N=1인 경우 PixelGANs, N=286인 경우(full image size) ImageGAN이라고 특별히 이름붙인다. PixelGAN은 spatial sharpness에는 효과가 없지만 colorfulness는 향상시킨다(Fig 7에서 L1에 비해 버스가 붉어진 걸 볼 수 있다). 16x16 PatchGAN은 FCN-score가 더 좋지만 tiling artifacts가 보이고, 70x70 PatchGAN은 tiling artifacts가 완화되고 score도 약간 더 높다. ImageGAN은 visual quality가 더 향상되지도 않고 score도 더 낮다.


이 외에도 colorization, semantic segmantation 등에 모델이 사용될 수 있다. 자세한 내용은 생략하겠다.
Strengths
- image-to-image problem에 범용적으로 사용될 수 있는 모델을 만들었다.
- FCN-score를 이용해 정량적으로 평가하려는 시도가 참신했다.
- 다양한 dataset과 task에 cGANs의 성능을 확인해 본 것이 좋았다.
- ablation study를 통해 architecture의 각 부분의 유용성을 입증했다.
내용이 신기하고 시도도 참신해서 재미있게 읽었다. 특히 U-Net의 skip network를 사용한 게 꽤 좋은 시도였던 것 같다.
