오늘 리뷰할 논문은 FCN 논문이다.
근데 논문이 옛날(2015) 논문이기도 하고 좀 중구난방인 느낌이라 다른 사람들이 정리한 포스트를 보는 게 더 도움이 됐다. 이번 논문 리뷰는 대충 썼다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] FCN: Fully Convolutional Networks for Semantic Segmentation
- FCN 논문 리뷰 — Fully Convolutional Networks for Semantic Segmentation
- [Segmentation] FCN 논문 리뷰
- [논문 리뷰] Fully Convolutional Networks for Semantic Segmentation (FCN)
Summary
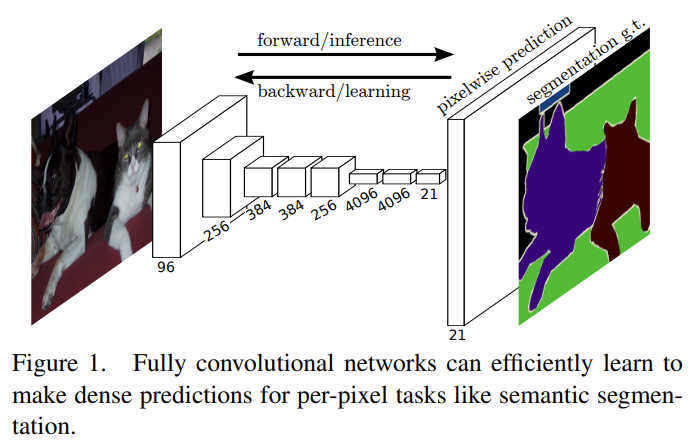
논문은 semantic segmentation에 end-to-end, pixels-to-pixels로 학습된 fully convolutional network (FCN)가 SOTA를 능가할 수 있음을 보인다.
기존 classification network인 AlexNet, VGGnet, GoogLeNet을 fully convolutional으로 바꾸고 그들의 learned representation으로부터 fine tuning한다.
deep, coarse, semantic information과 shallow, fine, appearance information을 결합하기 위해 새로운 “skip” architecture을 정의한다.
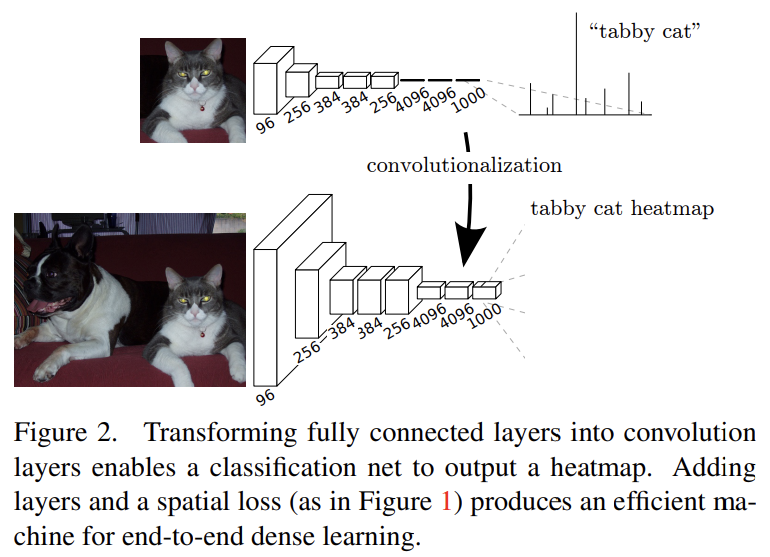
LeNet, AlexNet 같은 일반적인 recognition nets의 fully connected layers는 fixed dimensions를 가진다. 그러나 이 fully connected layers도 전체 input regions를 cover하는 kernels를 가진 convolution으로 볼 수 있다. Fig 2처럼 convolutionalization을 하면 임의의 크기의 input을 받을 수 있다. resulting maps은 (특정 input patches에서) original net과 동일한데 계산이 더 효율적이다.
input은 임의의 크기를 받을 수 있지만 subsampling으로 인해 output dimension은 감소된다. 이는 output을 coarse하게 만든다.
OverFeat에 의해 소개된 Input shifting과 output interlacing은 interpolation 없이 coarse outputs로부터 dense predictions을 만드는 Shift-and-stitch 트릭이다. 단순히 subsampling을 줄이는 것은 tradeoff인데 filters가 finer information을 보지만 receptive field가 더 작고 연산이 더 오래 걸린다. shift-and-stitch trick도 다른 종류의 tradeoff인데, filters의 receptive field sizes 감소 없이 output이 denser해지지만 filters는 finer scale에의 정보에 접근하지 못한다. 논문은 shift-and-stitch로 예비 실험은 해봤지만 model에 적용하지는 않는다. 이후 소개할 skip layer fusion과 결합했을 때 곧 설명할 upsampling을 통한 학습이 더 효과적이고 효율적이었다.
coarse outputs를 dense pixels로 연결할(바꿀) (2가지) 방법이 interpolation과 backward strided convolution(=Deconvolution)이다.
전체 image에 fully convolutional training하는 것이 patchwise training보다 연산 효율적이다(patch 간 overlap 때문에 연산이 겹쳐서). 실험 결과 patchwise training이 dense prediction을 위해 더 빠르거나 좋은 수렴을 만들지 않았고 whole image training이 효과적이고 효율적이었다.
ILSVRC classifiers를 FCN으로 변경하고 in-network upsampling과
pixelwise loss를 가지고 dense prediction를 위해 augment한다. segmentation을 위해 fine-tuning하고, coarse, semantic information과 local, appearance information을 결합하는 새로운 skip architecture을 짓는다. per-pixel multinomial logistic loss를 가지고 학습하며 표준적인 metric인 mean pixel intersection over union로 평가한다.
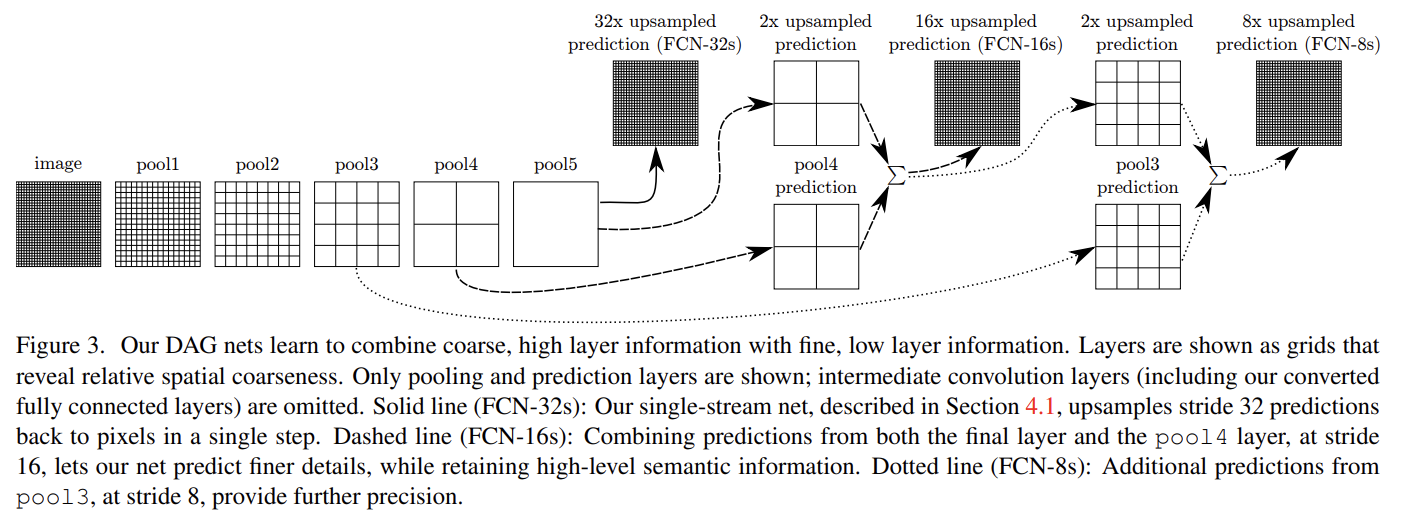
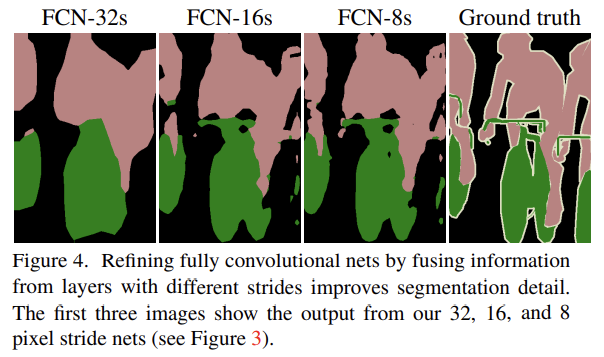
중간 pooling layer의 local, appearance information를 skip architecture로 가져와서 coarse, high layer information에 더해줬다. 1x1인 pool5의 activation map을 32배 한 upsampled prediction을 FCN-32s라고 한다. 2x2인 pool4의 activation map과 pool5를 2x upsampled prediction을 더해, 16x upsampled prediction(FCN-16s)를 구했다. 이와 같이 4x4 pool3과 앞서 더해주었던 prediction을 합해 8x upsampled predicton(FCN-8s)를 구했다. Fig 4에서 볼 수 있듯 FCN-32s, FCN-16s, FCN-8s 순으로 결과가 나아졌다. low layer의 정보를 더할수록 finer한 정보를 지니는 것이다.


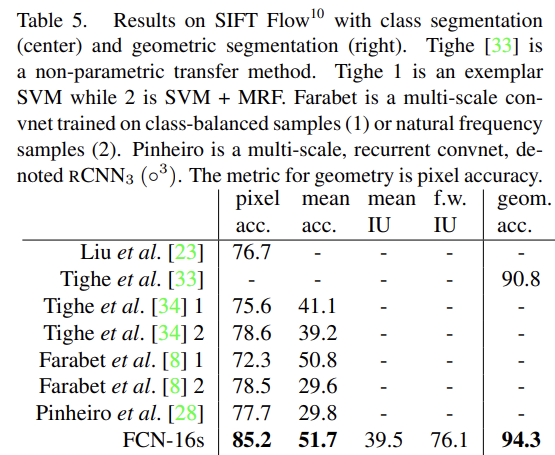

실험 결과 PASCAL VOC 2011-2, NYUDv2, SIFT Flow에서 SOTA를 달성했다.
논문은 설명이 뭔가 명확/깔끔하지 않아서 다시 정리하겠다.
쉽게 요약하면 (기존 FC layer는 공간 정보를 담지 못하는데 segmentation은 공간 정보를 유지하여 pixel 단위로 예측해야 하므로) 기존 유명 convnet에 마지막 FC-layer를 1x1 convolution layer로 교체해서 input image size를 유동적으로 만들었고 그로 인해 patchwise training 대신 whole image training을 했다. 그리고 pixelwise loss를 적용하기 위해 압축된 map을 다시 up-sampling해야 했는데, deconvolution을 수행해서 입력과 동일한 크기의(즉 dense한) output을 반환했다. 이때 정보 손실을 보상하기 위해 skip architecture를 적용하는데, Fig 3처럼 중간 pooling layer에서의 값을 중간중간에 더해주는 것이다.
FCN은 End-to-End 방식의 Fully-Convolution Model을 통한 Dense Prediction 혹은 Semantic Segmentation의 초석을 닦은 연구로써 이후 많은 관련 연구들에 영향을 주었다고 한다.
옛날 논문이라 사실 아이디어 자체는 단순한데 논문 읽는 데 집중도 안 되고 다른 포스트가 정리를 잘해놔서 논문은 대충 읽고 리뷰도 대충 썼다.
